标签:blog http java 使用 os io 文件 数据
RPC的全称为远程过程调用。由于Hadoop是一个分布式系统,因此底层的通信库也就必须实现RPC的基础功能。Hadoop RPC 在整个hadoop中扮演着底层通信模块的角色,举例而言NN和DN、AM和RM之间的通信和协调都是Hadoop RPC来完成的。熟悉使用Hadoop RPC可以加深我们对Hadoop各个模块之间通信过程的理解,也能让我们实现一些自己想要的分布式的小功能。
很多Hadoop相关书籍中都详细介绍了Hadoop RPC,其具体原理大家有兴趣的话可以去看源码加深理解。不过,我觉得作为底层通信库,我们更多的是需要去使用它,因此在这里我利用Hadoop RPC本身提供的接口,实现一个简单的通信模型。
本文所针对的Hadoop版本为2.4.1,其实RPC这一模块,Hadoop的兼容性做的很好。同早起版本相比,对RPC编程库使用者而言,主要的改变时Hadoop现在可以很好地兼容Protocol buffer、Avro和早起的Writable等序列化框架。本文将会建立一个使用org.apache.hadoop.ipc包(在hadoop-common工程目录下)提供的RPC接口,并且使用Writable序列化框架的RPC通信模型。
首先,是定义一个通信协议,所有利用Hadoop RPC的通信协议都必须继承VersionedProtocol接口,它主要是为了加入协议的版本信息:
import org.apache.hadoop.ipc.VersionedProtocol;
public interface Protocol extends VersionedProtocol{
public static final long versionID = 1L;
public boolean writeFile(Info statics);
}
现在我们定义了一个客户端和服务器端进行通信的协议,我们希望客户端发起调用,而后,由远程的服务器端对调用进行处理,再将处理得到的结果进行返回。同时我们也定义了这个协议的版本号用于版本监测。
这里我们希望客户端执行的方法是writeFile,客户端将一个类型为Info的参数传递给此方法,在服务器端执行完writeFile方法后,将执行结果返回给客户端。显然这里会设计到网络通信的问题,我们的参数Info,必须经由网络传递给服务器端,同时,服务器将执行的结果再返回给客户端。
为了方便对象在网络中传输,Hadoop RPC利用两个主要的内部框架:
1.序列化层:将对象转化为字节流在网络中进行传输。
2.Java反射机制:传输过去的字节流,在服务器端利用反射,重新生成这个对象。
通过这两个框架,对于上层而言,我们看不到对象到底是如何传输的,只会感觉在服务器端收到了在客户端建立的完全一致的对象。
通过上面的简单的介绍,我们应该注意到,Info statics这个对象,必须要能够进行序列化,也必须要利用反射建立对象的一些基本条件。
现在让我们看看如何定义Info这个类:
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
public class Info implements Writable {
public Text fileName;
public LongWritable taskNum;
public Info(){
this.fileName=new Text();
this.taskNum =new LongWritable();
}
public void setFileName(String str){
this.fileName = new Text(str);
}
public void setTaskNum(Long num){
this.taskNum = new LongWritable(num);
}
public String getFileName(){
return fileName.toString();
}
public Long getTaskNum(){
return taskNum.get();
}
@Override
public void write(DataOutput out) throws IOException {
fileName.write(out);
taskNum.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
System.out.println("Come to invoke my readFields");
// TODO Auto-generated method stub
fileName.readFields(in);
taskNum.readFields(in);
System.out.println("Read Success!!!");
}
}
这里需要特别说明的几点如下:
1.要让一个对象可以序列化,必须继承Writable接口,只要实现了这个接口,那么对象在RPC 中的传递就可以认为对我们而言是透明的。
而实现这个对象的序列化,就必须override 两个方法:public void write(DataOutput out) throws IOException以及public void readFields(DataInput in) throws IOException
2.为了能够在服务器端对对象进行反射,特别需要注意的就是要定义一个无参数的构造函数。在服务器端,会调用此方法,生成一个对象的实例。另外,尤其要注意的是如果说此对象包含了自定义类型的成员变量,注意在构造函数中对其进行实例化。否则,在后续进行readFields调用时,将会报错。由于你没有对该自定义类型的成员变量进行实例化,readFields读取到的数据无法完成赋值操作,产生如下的运行时报错:
Exception in thread "main" java.lang.reflect.UndeclaredThrowableException
at com.sun.proxy.$Proxy8.writeFile(Unknown Source)
at SJTU.client.App.main(App.java:30)
Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.ipc.RpcServerException): IPC server unable to read call parameters: null
at org.apache.hadoop.ipc.Client.call(Client.java:1410)
at org.apache.hadoop.ipc.Client.call(Client.java:1363)
at org.apache.hadoop.ipc.WritableRpcEngine$Invoker.invoke(WritableRpcEngine.java:240)
... 2 more
现在我们已经定义了一个协议,也实现了协议中方法的参数的序列化,下面的工作就非常简单了,首先是实现我们之前定义的协议。注意,这个实现是会在服务器端运行的,你需要注意到服务器的运行环境和上下文。
下面是我的协议的实现:
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import org.apache.hadoop.HadoopIllegalArgumentException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.ProtocolSignature;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.RPC.Server;
public class WriteServer implements Protocol{
public Server server;
@Override
public long getProtocolVersion(String protocol, long clientVersion)
throws IOException {
return this.versionID;
}
@Override
public ProtocolSignature getProtocolSignature(String protocol,
long clientVersion, int clientMethodsHash) throws IOException {
return new ProtocolSignature(Protocol.versionID,null);
}
@Override
public boolean writeFile(Info statics) {
// 在服务器端新建一个文件,并将由客户端传递过来的Info statics信息写入进去
FileWriter writer;
try {
writer = new FileWriter("/home/chenershuile/helloWritable");
BufferedWriter bw = new BufferedWriter(writer);
bw.write(statics.getFileName());
bw.write(statics.getTaskNum().toString());
bw.close();
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return true;
// 执行完成,返回ture
}
public void init(){
try {
this.server = new RPC.Builder(new Configuration()).setBindAddress("master").setNumHandlers(5).setProtocol(Protocol.class).setPort(50071)
.setInstance(new WriteServer()).build();
} catch (HadoopIllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
@SuppressWarnings("static-access")
public void run(){
this.server.start();
System.out.println("The server start at:"+this.server.getPort());
}
public void stop(){
this.server.stop();
}
}
在这里,我不仅仅实现了协议,也利用org.apache.hadoop.ipc.RPC类提供给我们的Builder静态方法,建立起了一个服务器端。这个服务器端会开启50071端口,进行监听。
每个Set方法,感兴趣的可以去org.apache.hadoop.ipc.RPC类中查看,都非常简单,主要是设置服务器的配置。
要注意的是setProtocol()和setInstance()方法。前者填入此服务器的处理的协议的class(协议是一个接口),后者填入你所实现这个接口的类的实例(new Impl()).
好了,到此为止,我们已经完成了服务器端的工作,现在我们可以利用WriteServer中的方法,建立起一个高效的Hadoop RPC server。
public class App
{
public static void main( String[] args )
{
WriteServer writeServer = new WriteServer();
writeServer.init();
writeServer.run();
}
}
之后,运行此jar,可以看到程序执行如下:

我们可以发现,服务器端已经开启了运行,现在需要的是建立一个Client端。
建立Client端的过程非常简单,我们可以用代码说明如下:
import java.io.IOException;
import java.net.InetSocketAddress;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import SJTU.server.Protocol;
import SJTU.server.Info;
/**
* Hello world!
*
*/
public class App
{
public static void main( String[] args )
{
InetSocketAddress addr = new InetSocketAddress("master",50071);
Configuration conf = new Configuration();
try {
Protocol proxy=RPC.getProxy(Protocol.class,Protocol.versionID,addr,conf);
System.out.println("Start Client");
String fileName = "hdfs://";
Long taskNum = 10L;
Info statics = new Info();
statics.setFileName(fileName);
statics.setTaskNum(taskNum);
System.out.println(proxy.writeFile(statics));
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
核心代码同样是借助于org.apache.hadoop.ipc.RPC提供给我们的对外的静态方法getProxy。这里我简单说明下参数的意义:前两者都没什么说的,跟协议相关。addr是一个InetSocketAddress,代表服务器端的地址,当然你要和服务器端保持一致,确保能访问到。conf主要的作用,按照我的理解,是相应的配置文件。具体它有什么用我也说不全面,还希望大神为我解答。
为了更好地理解调用的过程,我在相关的类中,写了很多System.out.println()来查看相关过程。。。所以我的执行结果也比较奇怪。。。
服务器端主要被涉及的类,除了org.apache.hadoop.ipc.RPC还有WritableRpcEngine,他俩都在同一个包下,它完成了Writable序列化比较相关的工作。
而对象的真正的序列化读取是在:ObjectWritable中,它在org.apcha.hadoop.io包中
对对象的反射机制,hadoop在底层的java.lang.reflect 上层又添加了一层:ReflectionUtil,它在org.apache.hadoop.util包中
最后,程序的执行过程如下,很多在终端的额外输出都是我自己对以上几个类修改添加的,可以帮助我们了解反射,代理,通信,序列化这些过程的执行。当然详细的理解还是需要自己去更加细致的分析整个RPC过程。
服务器端:
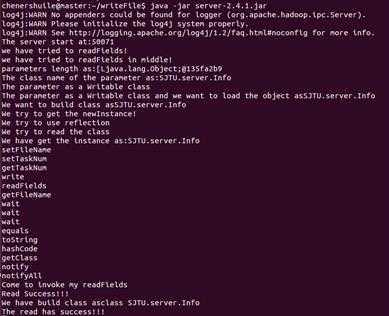
客户端:

可以注意一下,对Info对象,其在server端会进行readFields。而且在服务器端会进行反射,实例化等操作。具体的细节大家可以参考Hadoop技术内幕和到上文提到的相关的类中查看。

Hadoop 自定义RPC protocol,布布扣,bubuko.com
标签:blog http java 使用 os io 文件 数据
原文地址:http://www.cnblogs.com/chenershuile/p/3885117.html