标签:style blog http 使用 os strong io 文件
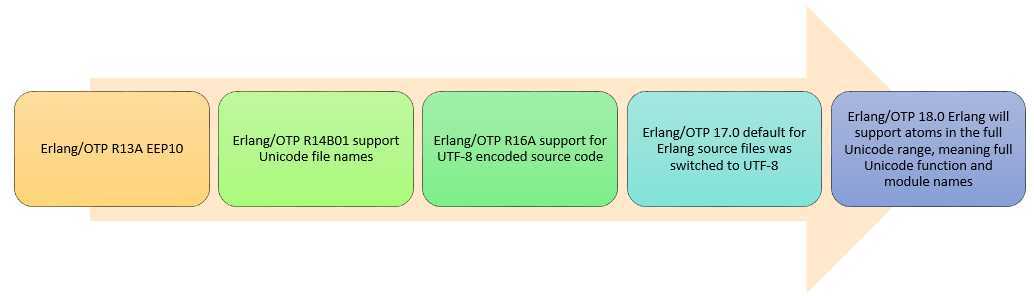
最近看了Erlang User Conference 2013上patrik分享的BRING UNICODE TO ERLANG!视频,这个分享很好的梳理了Erlang Unicode相关的问题,基本上把 Using Unicode in Erlang 讲解了一遍.再次学习了一下,整理成文字,补充一些 [Erlang 0062] Erlang Unicode 两三事 遗漏掉的内容.
视频在这里: http://www.youtube.com/watch?v=M6hPLCA0F-Y
PDF在这里: http://www.erlang-factory.com/upload/presentations/847/PatrikEUC2013.pdf
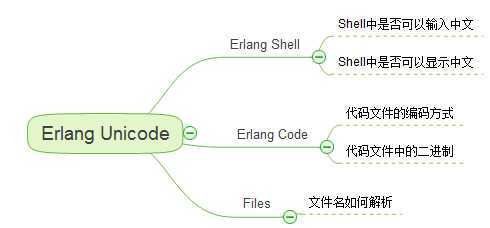
我们梳理一下,Erlang Unicode的问题域包含哪些具体的细节:
Erlang Shell
Erlang Shell中是否可以输入中文
Erlang Shell中是否可以显示中文
Erlang Code
代码文件的编码方式
Files
文件名如何解析
下面我们逐一击破:
Erlang Shell中是否可以输入中文
# echo $LANG en_US.UTF-8
LC_CTYPE=en_US.ISO-8859-1 /usr/local/bin/erl
LC_CTYPE=en_US.ISO-8859-1 /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> io:getopts().
[{expand_fun,#Fun<group.0.56199974>},
{echo,true},
{binary,false},
{encoding,latin1}]
2> "210\221[C.
[230,136,145,228,187,172]
3> io:setopts([{encoding,unicode}]).
ok
4>
4> "我们".
[25105,20204]
5>
Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:4:4] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V6.0 (abort with ^G)
1> "我们".
"我们"
2> io:format("~tp",[v(1)]).
"我们"ok
4> io:format("~ts",[v(1)]).
我们ok
5> io:format("~ts",[lists:seq(20204,20220)]).
们仭仮仯仰仱仲仳仴仵件价仸仹仺任仼ok
6> io:format("~ts",[lists:seq(20204,20290)]).
们仭仮仯仰仱仲仳仴仵件价仸仹仺任仼份仾仿伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏伐休伒伓伔伕伖众优伙会伛伜伝伞伟传伡伢伣伤伥伦伧伨伩伪伫伬伭伮伯估伱伲伳伴伵伶伷伸伹伺伻似伽伾伿佀佁佂ok
7> io:getopts().
[{expand_fun,#Fun<group.0.100149429>},
{echo,true},
{binary,false},
{encoding,unicode}]
8> io:setopts([{encoding,latin1}]).
ok
9> io:format("~ts",[lists:seq(20204,20290)]).
\x{4EEC}\x{4EED}\x{4EEE}\x{4EEF}\x{4EF0}\x{4EF1}\x{4EF2}\x{4EF3}\x{4EF4}\x{4EF5}\x{4EF6}\x{4EF7}\x{4EF8}\x{4EF9}\x{4EFA}\x{4EFB}\x{4EFC}\x{4EFD}\x{4EFE}\x{4EFF}\x{4F00}\x{4F01}\x{4F02}\x{4F03}\x{4F04}\x{4F05}\x{4F06}\x{4F07}\x{4F08}\x{4F09}\x{4F0A}\x{4F0B}\x{4F0C}\x{4F0D}\x{4F0E}\x{4F0F}\x{4F10}\x{4F11}\x{4F12}\x{4F13}\x{4F14}\x{4F15}\x{4F16}\x{4F17}\x{4F18}\x{4F19}\x{4F1A}\x{4F1B}\x{4F1C}\x{4F1D}\x{4F1E}\x{4F1F}\x{4F20}\x{4F21}\x{4F22}\x{4F23}\x{4F24}\x{4F25}\x{4F26}\x{4F27}\x{4F28}\x{4F29}\x{4F2A}\x{4F2B}\x{4F2C}\x{4F2D}\x{4F2E}\x{4F2F}\x{4F30}\x{4F31}\x{4F32}\x{4F33}\x{4F34}\x{4F35}\x{4F36}\x{4F37}\x{4F38}\x{4F39}\x{4F3A}\x{4F3B}\x{4F3C}\x{4F3D}\x{4F3E}\x{4F3F}\x{4F40}\x{4F41}\x{4F42}ok
10> io:format("~ts",[v(1)]).
\x{6211}\x{4EEC}ok
11> io:setopts([{encoding,unicode}]).
ok
12> io:format("~ts",[v(1)]).
我们ok
13> io:format("~ts",[lists:seq(20204,20290)]).
们仭仮仯仰仱仲仳仴仵件价仸仹仺任仼份仾仿伀企伂伃伄伅伆伇伈伉伊伋伌伍伎伏伐休伒伓伔伕伖众优伙会伛伜伝伞伟传伡伢伣伤伥伦伧伨伩伪伫伬伭伮伯估伱伲伳伴伵伶伷伸伹伺伻似伽伾伿佀佁佂ok
14>
Erlang Shell中是否可以显示中文
之前提到过的Erlang Shell 中显示文本常量的各种奇怪,其实源于字符串启发式检测机制("Heuristic String Detection"),简单讲就是Erlang Shell会检测List,Binary里面的数据是否可以有可打印的字符,比如下面的二进制串<<230,136,145,228,187,172,229,173,166,228,185,160>>.就被认为检测到可打印的,就输出了<<"我们学习"/utf8>>.
还记得那个输出数据的技巧吗?输出的数据内容被Shell自作聪明的打印成了字符,怎么解决的呢?在数据尾部追加一个0,比如[25105].会打印出来"我",[25105,0]就原样输出了.这个技巧实际上是通过加0避开了"Heuristic String Detection"机制.做下面的实验需要注意的一点是启动erl的参数:
erl +pc unicode
+pc 这个选项的作用就是选择Shell可打印字符的范围,可以是erl +pc latin1 或者 erl +pc unicode,在紧接着的实验里面,[25105]被如实显示并没有被解析显示成"我".
默认情况下,erl启动参数是latin
# erl +pc unicode Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> <<230,136,145,228,187,172,229,173,166,228,185,160>>. <<"我们学习"/utf8>> 2> <<230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,97,110,103>>. <<"我们学习Erlang"/utf8>> 3> $我. 25105 4> <<230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,97,110,103,0>>. <<230,136,145,228,187,172,229,173,166,228,185,160,69,114, 108,97,110,103,0>> 5> [25105]. "我" 6> [25105,0]. [25105,0]
# erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> $我. 25105 2> [25105]. [25105] 3>
io:printable_range/0 和 io_lib:printable_list/1这两个函数可以帮助我们检查当前shell的可打印字符的范围,判断一个List是否属于可打印的.看下面的例子:
erl +pc unicode Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> io_lib:printable_list([25105,20204]). true 2> [25105,20204]. "我们" 3> io:printable_range(). unicode 4>
erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> io_lib:printable_list([25105,20204]). false 2> [25105,20204]. [25105,20204] 3> io:printable_range(). latin1 4>
这个启发机制(heuristics)同样被io(_lib):format/2使用,~tp会受到+pc参数的影响,~ts不会.
# erl +pc unicode
7> io:format("~ts",[[25105]]).
我ok
8> io:format("~tp",[[25105]]).
"我"ok
9>
# erl +pc latin1
3> io:format("~ts",[[25105]]).
我ok
4> io:format("~tp",[[25105]]).
[25105]ok
5>
代码文件的编码方式
-module(coding). -compile(export_all). a()-> "我们学习Erlang".
Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V6.0 (abort with ^G)
1> coding:a().
[25105,20204,23398,20064,69,114,108,97,110,103]
2> io:format("~ts",[v(1)]).
我们学习Erlangok
3> q().
ok
4>
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:a().
[230,136,145,228,187,172,229,173,166,228,185,160,69,114,108,
97,110,103]
2> io:format("~ts",[v(1)]).
æ??们å¦ä¹ Erlangok
3>
%% -*- coding: utf-8 -*- -module(coding). -compile(export_all). a()-> "我们学习Erlang".
下面我们在之前的测试代码文件中添加一个方法,返回一个二进制序列:
b()-> <<"我们学习Erlang">>.
# /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<17,236,102,96,69,114,108,97,110,103>>
2> io:format("~ts",[v(1)]).
^Qìf`Erlangok
3> q().
ok
你可能会猜测是+pc unicode的原因吗?好吧,明知不是我们还是试一下:
# /usr/local/bin/erl +pc unicode
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<17,236,102,96,69,114,108,97,110,103>>
2> io:format("~ts",[v(1)]).
^Qìf`Erlangok
3> q().
ok
问题在什么地方?对utf8描述符
b()-> <<"我们学习Erlang"/utf8>>.
# /usr/local/bin/erl
Erlang R16B02 (erts-5.10.3) [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V5.10.3 (abort with ^G)
1> coding:b().
<<230,136,145,228,187,172,229,173,166,228,185,160,69,114,
108,97,110,103>>
2> io:format("~ts",[v(1)]).
我们学习Erlangok
3>
做下简单的实验看看这两者的区别:
erl Erlang/OTP 17 [erts-6.0] [source] [64-bit] [smp:2:2] [async-threads:10] [hipe] [kernel-poll:false] Eshell V6.0 (abort with ^G) 1> "αβ" . [945,946] 2> 2> <<"αβ">> . <<"±²">> 3> 3> <<"αβ"/utf8>> . <<206,177,206,178>> 5> <<177,178>>. <<"±²">>
上面的第2行测试代码是怎么回事呢?输出的是个什么东西呢?看一下第5行代码就可以了,输出的是<<177,178>>,换句话说数据显示的时候被截断了.
文件名如何解析
至于文件名是否包含unicode,除非是文件名是不可控的外部资源,否则这个问题是可以通过项目规约规避掉的,没有必要通过代码/技术手段解决这个问题.
erl启动的时候添加不同的flag可以控制解析文件名的方式: +fnl 按照latin去解析文件名 +fnu 按照unicode解析文件名 +fna 是根据环境变量自动选择,这也是目前的系统默认值.可以使用file:native_name_encoding检查此参数.
Eshell V5.10.3 (abort with ^G) 1> file:native_name_encoding(). latin1 2> Eshell V6.0 (abort with ^G) 1> file:native_name_encoding(). utf8 2>
最后
unicode,io,file,group,user,re,wx,string这些模块在遇到unicode的时候要特别注意下.应该有不少人在正则这里栽跟头了吧, Using Unicode in Erlang 文档信息量很大,最后还有一些常见问题的解决以及代码,有兴趣的可以动手实践一下,今天就到这里.
[Erlang 00124] Erlang Unicode 两三事 - 补遗,布布扣,bubuko.com
[Erlang 00124] Erlang Unicode 两三事 - 补遗
标签:style blog http 使用 os strong io 文件
原文地址:http://www.cnblogs.com/me-sa/p/erlang-unicode_2.html