标签:
Trie树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。 典型应用是用于统计和排序大量的字符串(但不仅限于字符串), 所以经常被搜索引擎系统用于文本词频统计。
优点
利用字符串的公共前缀来节约存储空间,最大限度的减少无谓的字符串比较,查询效率比哈希表高。
比如说我们想储存3个单词,sky、skyline、skymoon。如果只是单纯的按照以前的字符数组存储的思路来存储的话,那么我们需要定义三个字符串数组。但是如果我们用字典树的话,只需要定义一个树就可以了。在这里我们就可以看到字典树的优势了。
基本性质
假如我们有and,as,at,cn,com这些关键词,那么如何构建trie树呢?
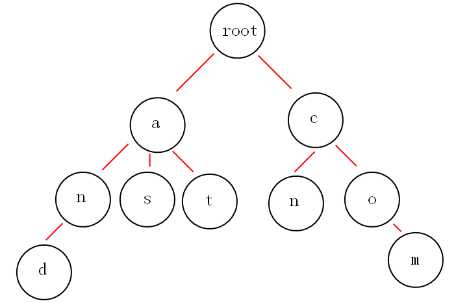
使用范围
既然学Trie树,我们肯定要知道这玩意是用来干嘛的。
第一:词频统计
可能有人要说了,词频统计简单啊,一个hash或者一个堆就可以打完收工,但问题来了,如果内存有限呢?还能这么玩吗?所以这里我们就可以用trie树来压缩下空间,因为公共前缀都是用一个节点保存的。
第二: 前缀匹配
就拿上面的图来说吧,如果我想获取所有以"a"开头的字符串,从图中可以很明显的看到是:and,as,at,如果不用trie树,你该怎么做呢?很显然朴素的做法时间复杂度为O(N2) ,那么用Trie树就不一样了,它可以做到h,h为你检索单词的长度,可以说这是秒杀的效果。
举个例子:现有一个编号为1的字符串”and“,我们要插入到trie树中,采用动态规划的思想,将编号”1“计入到每个途径的节点中,那么以后我们要找”a“,”an“,”and"为前缀的字符串的编号将会轻而易举。
关于Tire树的更多介绍请参见:http://www.cnblogs.com/jiutianhe/archive/2012/10/16/2755650.html
http://www.blogchong.com/?mod=pad&act=view&id=86
标签:
原文地址:http://www.cnblogs.com/moonandstar08/p/5525344.html