标签:
Fuzzy Lookup 预先加载一个Reference表,在执行时,Fuzzy Lookup将源数据提取出来,逐行和Reference表中的每行数据进行模糊匹配,输出匹配程度的指数:相似度和信任度(Similarity and Confidence)。Fuzzy Lookup的匹配算法简单描述为:将Reference表中的标准字符串拆分成多个substring(单个字符在字符串中的相对位置不变),只要输入字符串包含任意一个substring,Fuzzy Lookup 就认为匹配成功,按照Fuzzy logic,输出Similarity and Confidence,模糊匹配的实现方式类似于like ‘%substring%’。When Fuzzy Lookup indexes a token like committee, it also indexes sub-token elements comm, ommi, mmit, mitt, itte, ttee. This scheme helps to speed up retrieval and to recover from input errors.
相似度(Similiarity)是指输入字符串和任意一个substring的相似程度,而信任度(Confidence)是指输入字符串和substring成功包含所占的百分比。
Fuzzy logic is an approach to computing based on "degrees of truth" rather than the usual "true or false" (1 or 0) Boolean logic. When the reference table has close matches for an input tuple, the similarity is high. If there is a single record among all reference tuples that closely matches the input tuple, the confidence score is also high.
ColumnSimilarity 是Input 字符串和 Reference表中的标准字符串直接进行比较的相似度,而不是Input 字符串 和 substring进行比较的相似度。
Fuzzy Lookup returns column-level similarity scores which measure how similar the values in a particular column for the input and match result. The column-level scores can be used to fine tune the match quality and for further downstream processing of match results.
一,Tab
Fuzzy Lookup Transformation performs a lookup operation between an input dataset and a reference dataset using a best-match algorithm.
1,Reference Table Tab
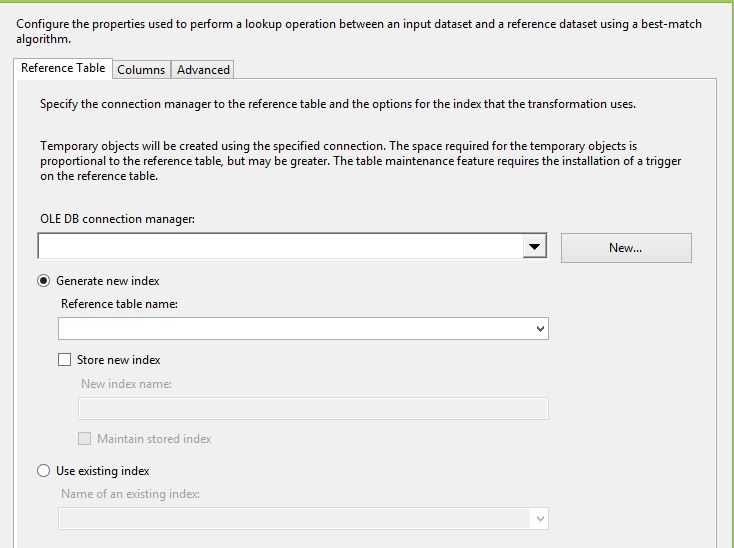
Reference Table 存储进行查找匹配的标准数据,用来对输入的数据进行匹配。
在Generate new index 或 Using existing index 选项中,这个“Index”是 Error-Tolerant Index(ETI)。如果勾选Store New index,那么SSIS Engine 将ETI实现为一个Table,默认的命名是dbo.FuzzyLookupMatchIndex. Fuzzy Lookup uses the Error-Tolerant Index (ETI) to find matching rows in the reference table.
Understanding the Error-Tolerant Index
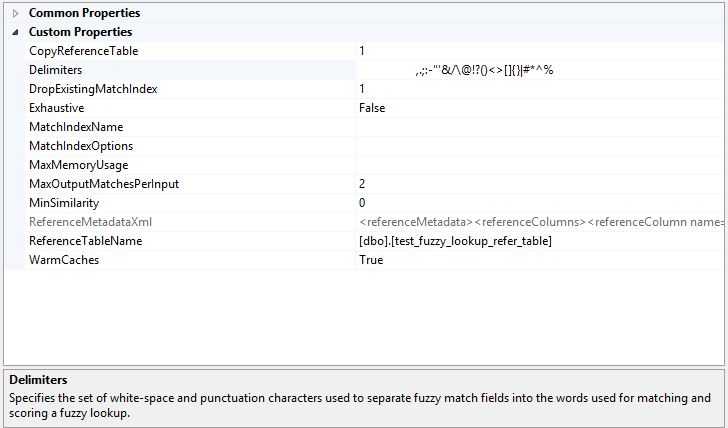
Fuzzy Lookup uses the Error-Tolerant Index (ETI) to find matching rows in the reference table. Each record in the reference table is broken up into words (also known as tokens), and the ETI keeps track of all the places in the reference table where a particular token occurs. In the address example, if your reference data contains 13831 N.E. 8th St, the ETI will contain entries for 13831, N, E, 8th, and St.. In addition, Fuzzy Lookup indexes substrings, known as q-grams, so that it can better match records that contain errors. The more unique tokens and the more rows in the reference table, the more entries and longer the occurrence lists in the ETI. The ETI will be roughly as big as your reference table. The tokenization process is controlled by the Fuzzy Lookup custom property Delimiters. For example, if you want to index N.E. instead of N and E, remove the period from the list of delimiters. The consequence is that N.E. appears as a single token in the ETI and will be looked up as a unit at run time. Because delimiters are applied globally, First.Avenue would also appears as a single token. When Fuzzy Lookup indexes a token like committee, it also indexes sub-token elements comm, ommi, mmit, mitt, itte, ttee. This scheme helps to speed up retrieval and to recover from input errors.
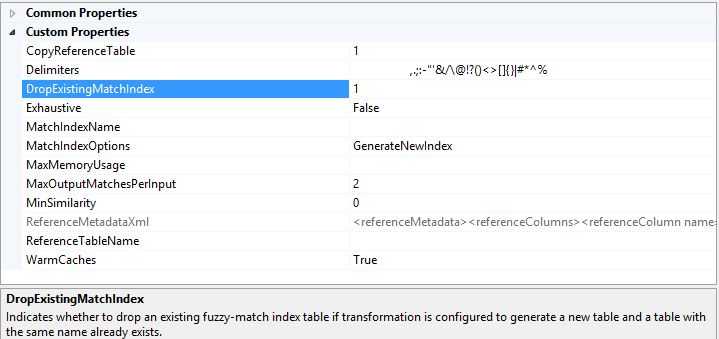
Because ETI construction for a very large reference table may take a non-trivial amount of time, Fuzzy Lookup offers the option of storing an ETI on the server and re-using it at a later date. This option takes a snapshot of the reference table and allows you to avoid re-building an ETI every time you run Fuzzy Lookup. If your ETI takes too long to re-build for every run, consider creating it once and re-using it in subsequent runs. To do this, select Store new index on the Reference Table tab, and then specify a table name.
If you would like to store your ETI, but your reference data changes from time to time, you can also enable Maintain stored index. This feature installs a trigger on the reference table that detects modifications and propagates them to the ETI, keeping it up-to-date. If you do not install table maintenance, Fuzzy Lookup will match against a snapshot of the reference table as it existed when the ETI was created.
注:q-grams是主流的字符串相似性查询方法,这种方法不改变单个字符在字符串中的相对位置,而将长的字符串拆分成多个substring,例如,将committee拆分成多个substring:comm, ommi, mmit, mitt, itte, ttee,如果一个字符串contain任意一个substring,那么Lookup Fuzzy认为该字符串和committee是匹配的,并输出Similarity and Confidence。
2,Columns Tab
设置 Available Input Columns (from the input data) 和 Available Lookup Columns (from the reference table) 之间的Mapping 关系,Fuzzy Lookup将对存在Mapping关系的两个Column value 进行匹配。Fuzzy Lookup的输出分为两部分:勾选Pass Through的Input Columns,勾选CheckBox的Lookup Columns。
3,Advanced Tab
配置 maximum number of matches to output per lookup,Similarity Threshold 和 Token Delimiters 选项。
二,What Happens at Run Time
At run time, takes an input row and tries to find the best match or matches in the reference table as efficiently as possible. By default, this is done by using the ETI to find candidate reference records that share tokens or q-grams in common with the input. The best candidates are retrieved from the reference table and a more careful comparison is made between the two records. Once there are no more candidates that could be better than any match found so far, Fuzzy Lookup stops and moves on to the next input row.
For Fuzzy Lookup to find a match in the reference table using the ETI, the input and target record must share at least one token or q-gram in common which is stored in the ETI. For reference table records consisting of only a single short word, it is possible that Fuzzy Lookup may be unable to match a dirty input record that contains a spelling mistake because there is no common token or q-gram stored in the ETI. Be aware, also, that Fuzzy Lookup indexes only a subset of the all the possible q-grams in a given record for efficiency reasons. Fuzzy Lookup may fail to find a match due to this sampling process, although matches will be found with a high degree of probability if the records contain many q-grams. For datasets which have attributes whose values are predominantly a single short token, one alternative, if Fuzzy Lookup is having trouble finding matches which you think it should find, is to set the Exhaustive component property to True. This will cause Fuzzy Lookup to ignore the ETI and instead directly compare the input record to each and every record in the reference table. This approach is prohibitively time-consuming for large reference tables, so only attempt exhaustive search on small reference tables.
Each match returned by Fuzzy Lookup has multiple scores associated with it which quantitatively describe how good a match the returned reference table record is to the input record. Each score is a number between 0.0 and 1.0. Perhaps the most important score, is the record-level similarity score. This score measures the overall similarity between the records across all fuzzy match columns that were defined. A score of 1.0 means that the records matched exactly on each of the match columns, while scores less than 1.0 indicate progressively more dissimilar matches. A record-level similarity score of 0.0 indicates that Fuzzy Lookup was unable to find a match in the reference table. As mentioned above, this could be because there were no common tokens or q-grams between the input and target reference table record that were indexed in the ETI. In addition to the record-level similarity, Fuzzy Lookup returns column-level similarity scores which measure how similar the values in a particular column for the input and match result. As described below, these column-level scores can be used to fine tune the match quality and for further downstream processing of match results.
Fuzzy Lookup additionally returns an estimate of the confidence for each match returned. This can be used to decide whether or not to automatically accept or reject a match. For instance, the reference table might contain values "E. Virginia" and "W. Virginia". If the dirty input was simply "Virginia", both reference records would have very high Similarity, but the difference between their similarity values would be very small. This indicates that Fuzzy Lookup could not find a clear winner and that you may need to manually review the match results for this input record. Such decisions can be automated by adding a Conditional Split Transformation after the Fuzzy Lookup which makes an accept/reject decision based upon the values of similarity and confidence.
In determining best matches, the most important parameter is the MinSimilarity threshold. You can set this custom property by using the Fuzzy Lookup UI. A reference tuple will be returned only if it has a Similarity that is greater than or equal to the MinSimilarity threshold. By setting a high similarity requirement, Fuzzy Lookup will consider fewer candidates and, as a result, may not return any matches. If you set MinSimilarity low, Fuzzy Lookup will consider more candidates and may be more likely to find a match, but the search could take longer.
Note that you can set MinSimilarity and both the record-level and also at the column-level for each individual column. Any match result return must meet the thresholds set at ALL levels and for ALL columns. For instance, you might set a record-level MinSimilarity of 0.5, but require that ZipCode has MinSimilarity 0.9 and Name has MinSimilarity 0.4. Fuzzy Lookup will only return results that meet all of those criteria.
The factors that determine similarity scores include:
Setting the right threshold depends on the nature of your application and of your data. If you require a close match between your inputs and your reference, you should consider setting a high value for MinSimilarity, such as 0.90. If you are doing an exploratory project, you may be interested in examining weak matches as well as close matches, so you should set MinSimilarity to a lower value, such as 0.1. There is no firm rule that you can use to determine this range, so it is recommended that you experiment with your data set. Looking at the output from several runs can suggest optimal values to set. For example, you perform a first run by using a threshold of 0.1. You observe that a certain input is matched with a certain output with similarity 0.2. If the tuples are too dissimilar for your application, you can set the MinSimilarity to 0.3 for your next run and exclude the match as too dissimilar. Repeating this process for a few iterations on a small test set can help you determine what is appropriate for your application.
If you want to view more than the single best match for each input, set the MaxOutputMatchesPerInput property to a value larger than one. Fuzzy Lookup will then return up to that many matches for each input row. Note that increasing the value of this property may increase the time it takes to process each input row.
三,Custom Property
1,WarmCaches
默认情况下,Fuzzy Lookup转换将 Reference Table 全部加载到Cache中, 如果Reference Table 数据量很大,而Input 数据很少,Fuzzy Lookup 转换会使用大量内存来加载Reference Table,耗费时间和内存。可以在Advanced Editor中设置 Custom Propertity:WarmCaches,将其设置为False,那么在Data Flow 执行之前,Fuzzy Lookup不会将Reference Table加载到内存。
By default, Fuzzy Lookup will load the ETI and reference table into available memory before starting to process rows. If you only have a few rows to process in a particular run, you can reduce this time by setting the WarmCaches property to False.

2,CopyReferenceTable
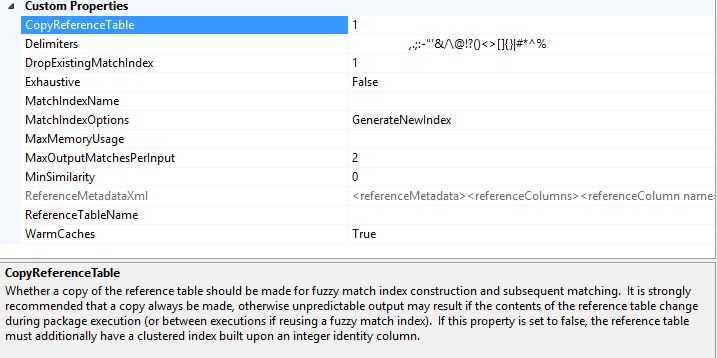
3,Delimiters
4,DropExistingMatchIndex
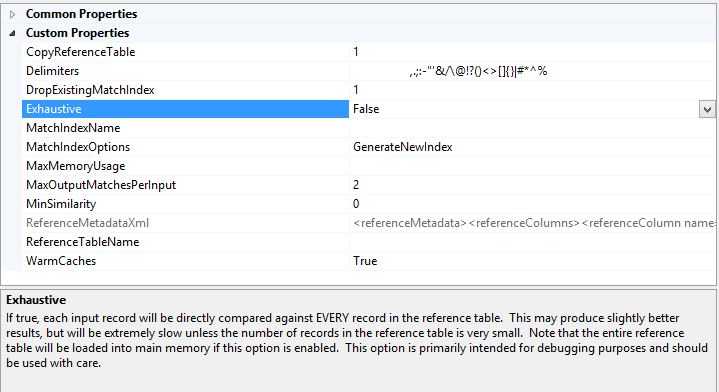
5,Exhaustive
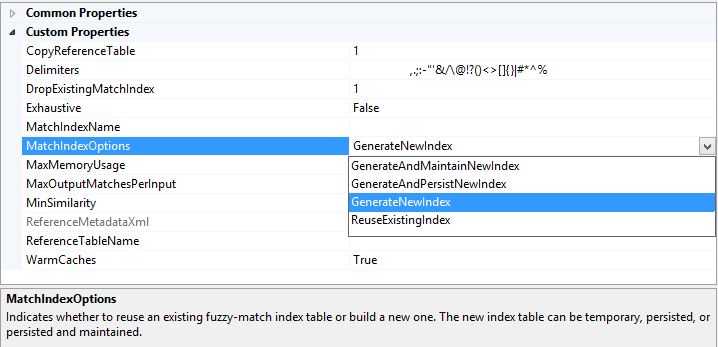
6,MatchIndexOptions
推荐博客:
利用SQL Server实现模糊查询(Fuzzy Lookup)和模糊分组(Fuzzy Grouping)
Fuzzy Lookup and Fuzzy Grouping in SQL Server Integration Services 2005
SSIS-Fuzzy lookup for cleaning dirty data
Fuzzy Lookup Transformation Usage
标签:
原文地址:http://www.cnblogs.com/ljhdo/p/5523602.html