标签:
程序的结构如下:
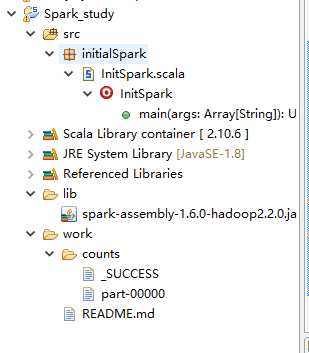
src:代码
lib: 存放spark的jar包
work:
README.md:输入文件
counts : 输出文件路径
_SUCCESS: 程序执行成功的标志文件(空白文件)
part-00000:结果文件
InitSpark.scala代码
package initialSpark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.rdd.RDD.rddToPairRDDFunctions
object InitSpark {
def main(args: Array[String]) {
//创建Spark Context
val conf = new SparkConf()
.setMaster("local") //单机模式
.setAppName("My App") //应用名
val sc = new SparkContext(conf)
//读取输入文件
val input = sc.textFile("./work/README.md")
//用空格分隔输入文件,切分成一个个单词
val words = input.flatMap { line => line.split(" ") }
//将单词转化成键值对并计数
val counts = words.map(word => (word, 1)) //转化成键值对
.reduceByKey((x, y) => x + y) //统计各个单词出现的次数
//将处理结果出入到指定文件夹
counts.saveAsTextFile("./work/counts")
}
}
本文参照《Spark 快速大数据分析》
标签:
原文地址:http://www.cnblogs.com/grufield/p/5525463.html