标签:
balancer是当hdfs集群中一些datanodes的存储要写满了或者有空白的新节点加入集群时,用于均衡hdfs集群磁盘使用量的一个工具。这个工具作为一个应用部署在集群中,可以由集群管理员在一个live的cluster中执行。
语法:
To start:
start-balancer.sh
用默认的10%的阈值启动balancer
hfs dfs balancer -threshold 3
start-balancer.sh -threshold 3
指定3%的阈值启动balancer
To stop:
stop-balancer.sh
Threshold参数是1%~100%范围内的一个数,默认值是10%。Threshold参数为集群是否处于均衡状态设置了一个目标。
如果每一个datanode的利用率(已使用空间/节点总容量)和集群利用率(集群已使用空间/集群总容量)不超过Threshold参数值,则认为这个集群是均衡的。
Threshold参数值越小,集群会越均衡。但是以一个较小的threshold值运行balancer带到平衡时花费的时间会更长。同时,如果设置了一个较小的threshold,但是在线上环境中,hadoop集群在进行balance时,还在并发的进行数据的写入和删除,所以有可能无法到达设定的平衡参数值。
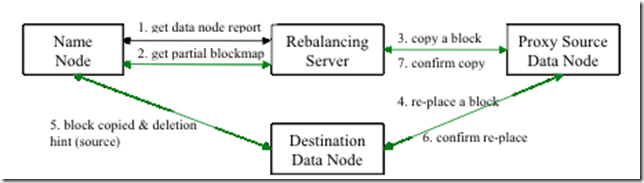
每次移动,一个datanode不会接受或移出少于10G的block或少于datanode总容量threshold百分比的block。每次移动不会运行超过20分钟。在每次移动结束,balancer会向namenode提交更新后的datanodes信息。
系统限制了balancer可以使用的带宽最大值,由如下参数设置:
dfs.balance.bandwidthPerSec
这个参数设置了一个数据块从一个datanode移到另一个时达到的最大速度。默认是1MB/s。该参数设置的越大,集群达到均衡的速度越快,但对应用进程带宽资源的竞争也就越大,会导致mapred应用运行缓慢。
?该参数在集群重启后生效
?该工具在一个hdfs集群中只能启动一个实例
?balancer在如下5种情况下会自动退出:
①集群已达到均衡状态;
②没有block能被移动;
③连续5次迭代移动没有任何一个block被移动;
④当与namenode交互式出现了IOException;
⑤另一个balancer在运行中。
对应5个退出信息:
* The cluster is balanced. Exiting
* No block can be moved. Exiting...
* No block has been moved for 5 iterations. Exiting...
* Received an IO exception: failure reason. Exiting...
* Another balancer is running. Exiting...
标签:
原文地址:http://www.cnblogs.com/roger888/p/5531841.html