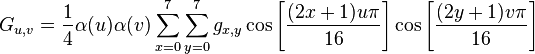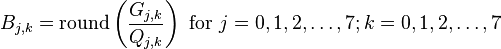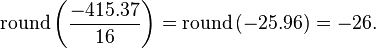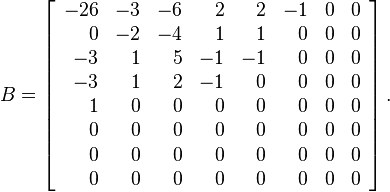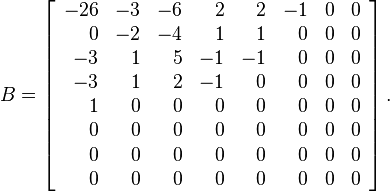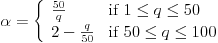标签:
原文链接:https://medium.freecodecamp.com/how-jpg-works-a4dbd2316f35#.iog01x8kp
JPG文件格式对于图片压缩是最令人印象深刻的技术进步之一,并在1992年登上了舞台。从那之后,它成为互联网上代表图片质量的技术标杆。这是很好的理由。然而JPG背后的很多技术却异常复杂,需要完全理解人眼如何调节对颜色和边界的感知。
因为我有些东西(你也是,如果你读到这篇文章),我想解释JPG编码是如何工作的,这样我们可以更好地理解如何生存更小的JPG文件。
JPG压缩机制分为几个阶段。下图从高层表述了这些阶段,后面我将逐个讲解。

有损数据压缩的一个关键原则是人类的传感器不像计算系统那样精确。科学来说,人眼只有分辨大约1千万种不同颜色的能力。然而,有许多因素会影响人眼感知颜色;完美的突出颜色错觉,或者这件搅乱因特网的礼服。要点就是,相对于要识别的颜色,人眼可以很好的被操纵。
质量是有损压缩效果的一种形式,然而JPG使用另一个方法进行:颜色模型。一个颜色空间代表一组颜色,它的颜色模型代表数学公式如何标示颜色(三原色RGB,四分色CMYK)。
这个过程的强大之处就是,你可以从一个色彩模型转换成另一个,意味着你可以用给定颜色的数学表达式得到一组完全不同的数值。
例如,下面指定的颜色,分别代表RGB和CMYK色彩模型,人眼看到的是相同的颜色,但是可以由不同的数值集标示。

JPG从RGB转换成Y,Cb,Cr色彩模型;模型由亮度(Y),色度蓝(Cb),色度红(Cr)组成。原因是,心里视觉试验(大脑如何处理眼睛看到的信息)表明人眼对亮度比色度更敏感,这意味着我们可以忽略在色度上的较大变化而不影响我们识别图像。因此,人眼收到信息之前,我们可以积极的改变CbCr通道信息。

YCbCr色彩空间的一个有趣的结果是,得到的Cb/Cr信道有较少的细粒度细节;它们包含的信息比Y信道少。
其结果是,JPG算法调整了Cb和Cr信道信息,压缩到原始大小的?(注意,有一些如何做到的细节,我这里不介绍…),被称为下采样。
这里需要注意的是下采样是有损压缩处理(不能恢复确切的原始色彩,但是非常接近),但对人类视觉皮层的可视化组件的整体影响是最小的。亮度(Y)是其中有趣的部分,因为我们只下采样CbCr信道,视觉系统的影响较低。

从现在起,JPG所有的操作都基于8x8的像素块。这样做是因为我们通常期望在8x8块上没有很多变化,即使在很复杂的图片中,在局部地区也有一些自相似性。我们将在之后的压缩处理利用这种自相似性。
这点上值得注意的是,我们要介绍JPG编码的常见”神器”之一。“色彩渗透”是沿着锋利边缘的颜色可以”渗透”到另一边。这是因为色度通道,它代表像素的颜色,平均到单个颜色需要4个像素1块,有些块跨越了锋利边缘。
到现在,事情已经相当简单。色彩空间,下采样,和分块在图像压缩领域都是简单的部分。但是现在… 现在真正的数学开始了。
DCT变化的关键部分是,它假定任何数字信号都可以使用余弦函数组合来重建。
例如,我们有下图:
你可以看到它实际上是cos(x)+cos(2x)+cos(4x)的和

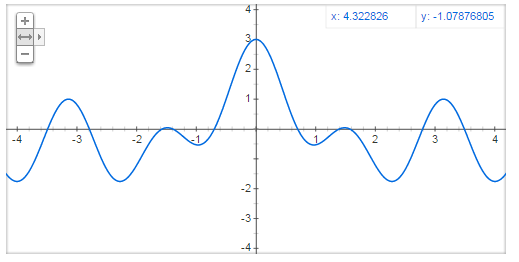
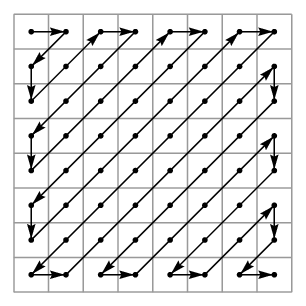
可能更好的显示是,真实的图片解码,给定在2D空间的一些列余弦函数。为了证明这一点,我展现了护粮网最惊人的GIF之一:在2D空间使用余弦函数编码n8x8像素块:
这里看到的是一张图片(最左边的面板)的重建。每一帧,我们使用一个新的基准值(右侧面板),并乘一个权重值(右侧面板文字)来生成图片(中间面板)的贡献。
如你所见,通过带权重的不同余弦值相加,我们重建了原始图像(相当完美…)
这是离散余弦变化如何工作的基础背景。核心就是任何8x8块都可以由一组权重余弦变化的和代表,在不同频率。整个事件的技巧就是搞清楚要用那些余弦输入,以及它们的权重。
原来“使用那些余弦”的问题相当简单;大量计算后,选出一组余弦值来生成最接近的值,它们是基础函数并在下图中显示。
至于“应当如何权重起来”的问题,简单的(HA!)套用这个公式。
我就不介绍这些值的含义了,你可以在维基上查看它们。

这个矩阵,G,代表用来重建图像(在动画右侧上方的小十进制数)的基础权重。基本上,每个基础余弦值,我们都与这个矩阵中的权重相乘,并相加整个值,之后得到最终的图像。
到这里,我们不在处理色彩空间了,而是直接操作G矩阵(基准权重),之后所有的压缩都直接基于这个矩阵。
这里的问题是我们现在将字节对齐的整数转换为实数。这样实际上膨胀了我们的信息(从1个字节到一个浮点数(4个字节))。为了解决这个问题,并开始生成更显著的压缩,我们进入量化阶段。
因此,我们不想压缩浮点数据。这将膨胀我们的数据流,而且是低效的。为此,我们要找到一个方法将权重矩阵转化成范围在[0,255]的值。直截了当来说,我们可以这样处理,找到矩阵中的最大/最小值 (分别是-415.38, 和77.13) ,将每个值除这个跨度来得到[0,1]区间的值,之后乘255的得到最终结果。
例如: [34.12- -415.38] / [77.13?—?-415.38] *255= 232
这个方法可行,但代价是显著的精度减少。这个缩放将产生不均匀分布的值,其结果是图像的显著视觉损失。
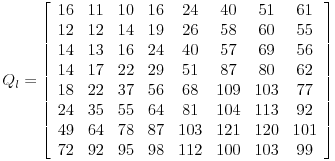
相反,JPG采取了不同的路线。不同于使用矩阵中值的范围作为它的缩放值,取而代之,使用了一个量化因素的预处理矩阵。这些QF不需要作为流的一部分,而是作为编码器本身的一部分。
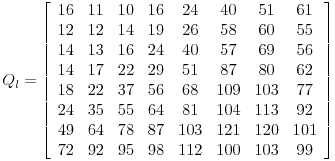
这个例子展示了量化因子矩阵的常用用法,
现在我们使用Q和G矩阵,来计算量化DCT协同矩阵:
例如,使用G[0,0]=?415.37和 Q[0,0]=16值:
最终结果矩阵:
看看矩阵变得更加简单了——它现在包含大量的0或小整数,使得它更容易压缩了。
简单些,我们对Y,CbCr信道分别应用和各过程,因此我们需要两个不同的矩阵:一个用于Y,另一个用于C信道:
图像量化压缩有两种重要的方式:1,限制权重的有效范围,减少代表它们所需的位数。2,许多权重变成相同的数字或者0,从而提高第三部的压缩,熵代码。
这样量化是JPEG产品的主要来源。因为图片的右下角趋向于最大的量化因数,JPEG产品趋向于图片重组。通过修改JPEG的”质量级别”,提升或降低,就可以直接控制量化因子的矩阵(我们会在一分钟内解释)。
现在,我们回到整数世界,并且可以对数据块进一步应用有损压缩。当看到我们的转化数据时,你会发现一些有趣的事情:
当你从左上移动到右下,0值出现的频率增加了。这看起来像首先怀疑是一个运行长度编码。但是这里行主序和列主序并不理想,因为这些0交织运行,而不是将它们打包到一起。
相反,我们从左上角开始,按照对角线之字形遍历矩阵,来回移动直到右下角。
亮度矩阵的结果,顺序如下:
?26,?3,0,?3,?2,?6,2,?4,1,?3,1,1,5,1,2,?1,1,?1,2,0,0,0,0,0,-1,-1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
一旦数据变成这种格式,接下来的步骤就简单了:顺序执行RLE,然后对结果执行统计编码(霍夫曼/算数/ANS)。
咚!数据块现在是JPG编码了。
现在,你理解了如何真正的创建JPG文件,这值得重新审视质量参数的概念,从Photoshop里导出JPG图像时就会遇到。
这个参数,称为q,是个从1到100的整数。可以认为q是图像质量的衡量:q值越高,相应的图像质量越高,文件大小越大。
质量值用在量化阶段,来缩放合适的量化因子。因此对于每个基准权重,量化阶段现在类似于
alpha符号作为质量参数的结果。
alpha或者Q[x,y]增加(记住alpha值越大对应的质量参数q越小),更多的信息会丢失,文件大小将减小。
因此,如果想以更高的视觉假象成本得到更小的文件,可以在导出阶段设置更低的质量值。

注意上图,在最低质量图片中,我们如何看待阻塞阶段还有量化阶段的清晰痕迹。
可能更重要的是质量参数变化依赖于图像。因为每个图片是唯一的且呈现出不同类型的可视产品,Q值也是唯一的。
当你理解JPG算法是如何工作的,几件事就变得明显了:
如果你想自己玩转这一切,这一切可以疯狂的整合到一个大约1000行的文件。
嘿!
希望知道如何是你的JPG文件更小?
希望知道PNG文件如何工作的,或者使它们更小?
希望有更多的数据压缩?买我的书!
标签:
原文地址:http://blog.csdn.net/lihenair/article/details/51427570