标签:
本来这篇是准备5.15更的,但是上周一直在忙签证和工作的事,没时间就推迟了,现在终于有时间来写写Learning Spark最后一部分内容了。
第10-11 章主要讲的是Spark Streaming 和MLlib方面的内容。我们知道Spark在离线处理数据上的性能很好,那么它在实时数据上的表现怎么样呢?在实际生产中,我们经常需要即使处理收到的数据,比如实时机器学习模型的应用,自动异常的检测,实时追踪页面访问统计的应用等。Spark Streaming可以很好的解决上述类似的问题。
了解Spark Streaming ,只需要掌握以下几点即可:
- DStream
- 概念:离散化流(discretized stream),是随时间推移的数据。由每个时间区间的RDD组成的序列。DStream可以从Flume、Kafka或者HDFS等多个输入源创建。
- 操作:转换和输出,支持RDD相关的操作,增加了“滑动窗口”等于时间相关的操作。
下面以一张图来说明Spark Streaming的工作流程:
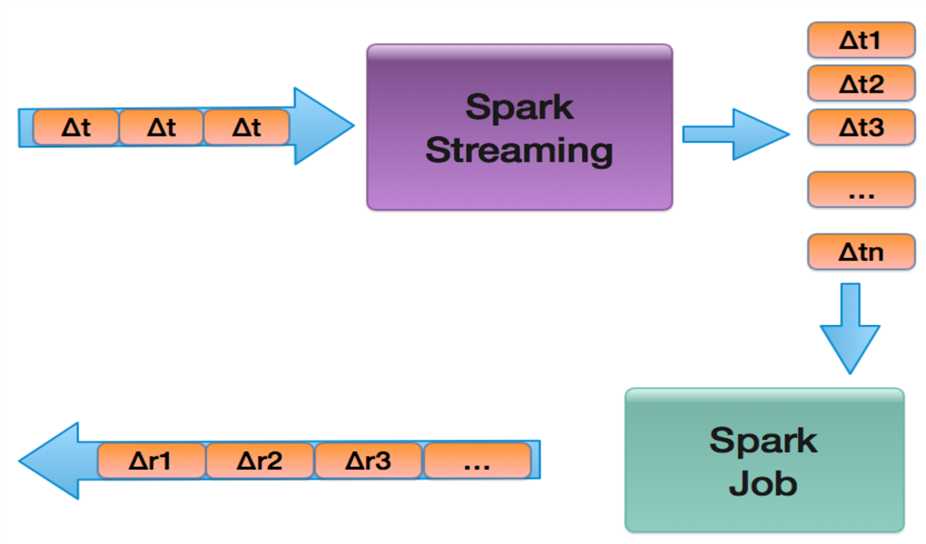
从上图中也可以看到,Spark Streaming把流式计算当做一系列连续的小规模批处理来对待。它从各种输入源读取数据,并把数据分组为小的批次,新的批次按均匀的时间间隔创建出来。在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中去。在时间区间结束时,批次停止增长。
转化操作
- 无状态转化操作:把简单的RDDtransformation分别应用到每个批次上,每个批次的处理不依赖于之前的批次的数据。包括map()、filter()、reduceBykey()等。
- 有状态转化操作:需要使用之前批次的数据或者中间结果来计算当前批次的数据。包括基于滑动窗口的转化操作,和追踪状态变化的转化操作(updateStateByKey())
无状态转化操作
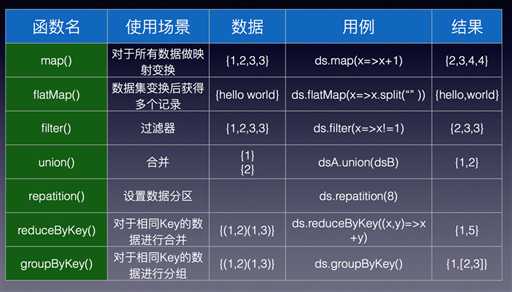
有状态转化操作
Windows机制(一图盛千言)
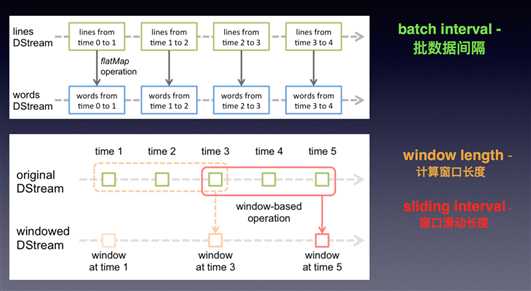
上图应该很容易看懂,下面举个实例(JAVA写的):
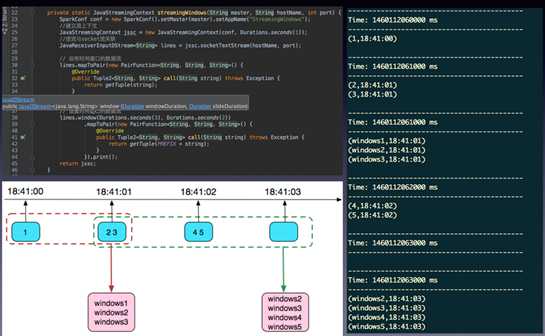
UpdateStateByKey()转化操作
主要用于访问状态变量,用于键值对形式的DStream。首先会给定一个由(键,事件)对构成的DStream,并传递一个指定如何个人剧新的事件更新每个键对应状态的函数,它可以构建出一个新的DStream,为(键,状态)。通俗点说,加入我们想知道一个用户最近访问的10个页面是什么,可以把键设置为用户ID,然后UpdateStateByKey()就可以跟踪每个用户最近访问的10个页面,这个列表就是“状态”对象。具体的要怎么操作呢,UpdateStateByKey()提供了一个update(events,oldState)函数,用于接收与某键相关的时间以及该键之前对应的状态,然后返回这个键对应的新状态。
- events:是在当前批次中收到的时间列表()可能为空。
- oldState:是一个可选的状态对象,存放在Option内;如果一个键没有之前的状态,可以为空。
- newState:由函数返回,也以Option形式存在。如果返回一个空的Option,表示想要删除该状态。
UpdateStateByKey()的结果是一个新的DStream,内部的RDD序列由每个时间区间对应的(键,状态)对组成。
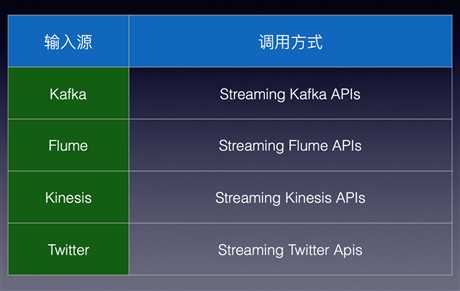
接下来讲一下输入源
- 核心数据源:文件流,包括文本格式和任意hadoop的输入格式
- 附加数据源:kafka和flume比较常用,下面会讲一下kafka的输入
- 多数据源与集群规模
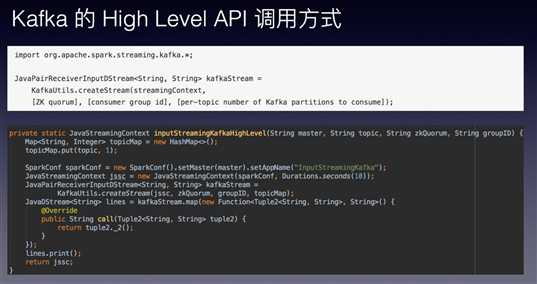
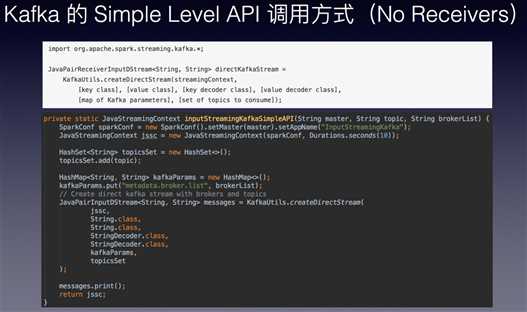
Kafka的具体操作如下:
基于MLlib的机器学习
一般我们常用的算法都是单机跑的,但是想要在集群上运行,不能把这些算法直接拿过来用。一是数据格式不同,单机上我们一般是离散型或者连续型的数据,数据类型一般为array、list、dataframe比较多,以txt、csv等格式存储,但是在spark上,数据是以RDD的形式存在的,如何把ndarray等转化为RDD是一个问题;此外,就算我们把数据转化成RDD格式,算法也会不一样。举个例子,你现在有一堆数据,存储为RDD格式,然后设置了分区,每个分区存储一些数据准备来跑算法,可以把每个分区看做是一个单机跑的程序,但是所有分区跑完以后呢?怎么把结果综合起来?直接求平均值?还是别的方式?所以说,在集群上跑的算法必须是专门写的分布式算法。而且有些算法是不能分布式的跑。Mllib中也只包含能够在集群上运行良好的并行算法。
MLlib的数据类型
- Vector:向量(mllib.linalg.Vectors)支持dense和sparse(稠密向量和稀疏向量)。区别在与前者的没一个数值都会存储下来,后者只存储非零数值以节约空间。
- LabeledPoint:(mllib.regression)表示带标签的数据点,包含一个特征向量与一个标签,注意,标签要转化成浮点型的,通过StringIndexer转化。
- Rating:(mllib.recommendation),用户对一个产品的评分,用于产品推荐
- 各种Model类:每个Model都是训练算法的结果,一般都有一个predict()方法可以用来对新的数据点或者数据点组成的RDD应用该模型进行预测
一般来说,大多数算法直接操作由Vector、LabledPoint或Rating组成的RDD,通常我们从外部数据读取数据后需要进行转化操作构建RDD。具体的聚类和分类算法原理不多讲了,可以自己去看MLlib的在线文档里去看。下面举个实例----垃圾邮件分类的运行过程:
步骤:
1.将数据转化为字符串RDD
2.特征提取,把文本数据转化为数值特征,返回一个向量RDD
3.在训练集上跑模型,用分类算法
4.在测试系上评估效果
具体代码:

1 from pyspark.mllib.regression import LabeledPoint
2 from pyspark.mllib.feature import HashingTF
3 from pyspark.mllib.calssification import LogisticRegressionWithSGD
4
5 spam = sc.textFile("spam.txt")
6 normal = sc.textFile("normal.txt")
7
8 #创建一个HashingTF实例来把邮件文本映射为包含10000个特征的向量
9 tf = HashingTF(numFeatures = 10000)
10 #各邮件都被切分为单词,每个单词背映射为一个特征
11 spamFeatures = spam.map(lambda email: tf.transform(email.split(" ")))
12 normalFeatures = normal.map(lambda email: tf.transform(email.split(" ")))
13
14 #创建LabeledPoint数据集分别存放阳性(垃圾邮件)和阴性(正常邮件)的例子
15 positiveExamples = spamFeatures.map(lambda features: LabeledPoint(1,features))
16 negativeExamples = normalFeatures.map(lambda features: LabeledPoint(0,features))
17 trainingData = positiveExamples.union(negativeExamples)
18 trainingData.cache#因为逻辑回归是迭代算法,所以缓存数据RDD
19
20 #使用SGD算法运行逻辑回归
21 model = LogisticRegressionWithSGD.train(trainingData)
22
23 #以阳性(垃圾邮件)和阴性(正常邮件)的例子分别进行测试
24 posTest = tf.transform("O M G GET cheap stuff by sending money to...".split(" "))
25 negTest = tf.transform("Hi Dad, I stared studying Spark the other ...".split(" "))
26 print "Prediction for positive test examples: %g" %model.predict(posTest)
27 print "Prediction for negative test examples: %g" %model.predict(negTest)
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5544239.html