标签:
前面三篇通过CPU、内存、磁盘三巨头,讲述了如何透过现在看本质,怎样定位服务器三巨头反映出的问题。为了方便阅读给出链接:
通过三篇文章的基本介绍,可以看出系统的语句如果不优化,可能会导致三巨头都出现异常的表现。所以本篇开始介绍系统中的重头戏--------------SQL语句!

这就是SQL 语句! 帅气吧!还有呢!

这也是SQL语句!
博主真能骗人,我读书少也知道,这是“车、马、炮”的 “车” ! 没错,此篇文章里会以“车”来代表你的SQL 语句,让你知道怎样让你的“车”从16手报废车改装成------------------ |法拉利|
注:SQL语句优化的细节,一本书都写不全,所以这里只讲述“改装思想!”
你的系统中有成千上万的语句,那么优化语句从何入手呢 ? 当然是系统中运行最频繁,最核心的语句了。废话不多说,上例子:
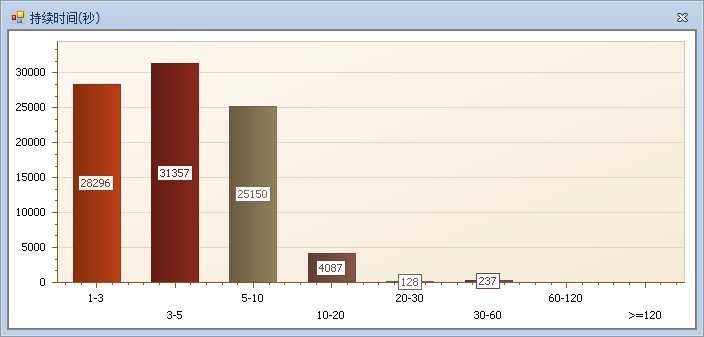
这是一天的语句执行情况,里面柱状图表示的是对应执行时间段内语句的次数,总体看起来长时间语句非常多。
下面看一下具体的语句执行情况:
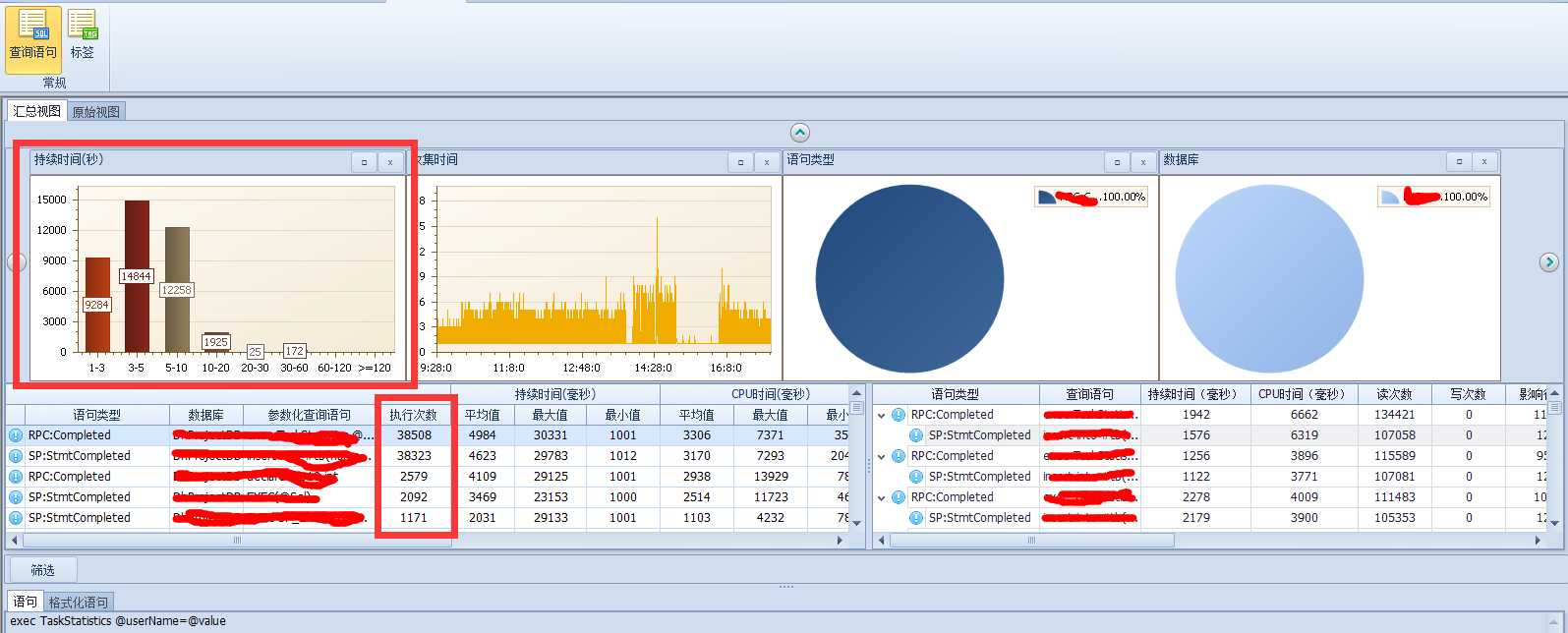
排位第一的语句执行次数38508次,是一个存储过程(RPC:Completed 表示存储过程结束,不知道这个的请看profiler的使用说明)。其中的一条语句(SP:StmtCompleted)也就是排在第二位的语句,存储过程的执行时间大部分消耗这条子语句上!
这个例子可以看出业务系统中使用最频繁,且远远高于其他处理的语句就是这个执行3W8Q多次的语句。
那么看到这样的数据,想做优化当然要从这条语句下手了!它就是你最常开的车了! 这个例子中只要解决了这条语句的性能问题,整个系统性能就可以有一个质的飞跃。
--------------------------------上面的情况,你很专一,只喜欢开一种车!----------------------------
这个例子中,你喜欢开的车就比较多了,也就是说需要你关注,并且优化的语句较多。(很多语句执行次数都很频繁,也就是系统中使用到的频繁功能较多)
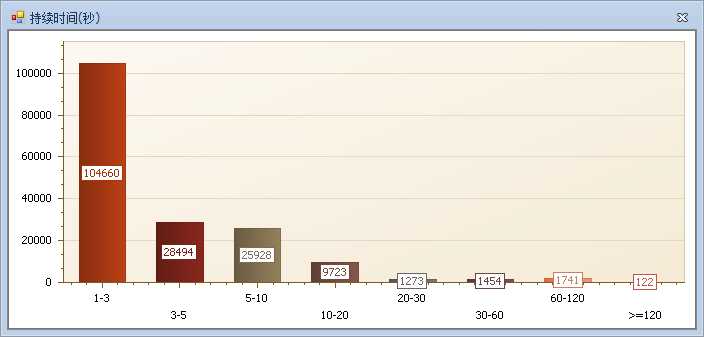
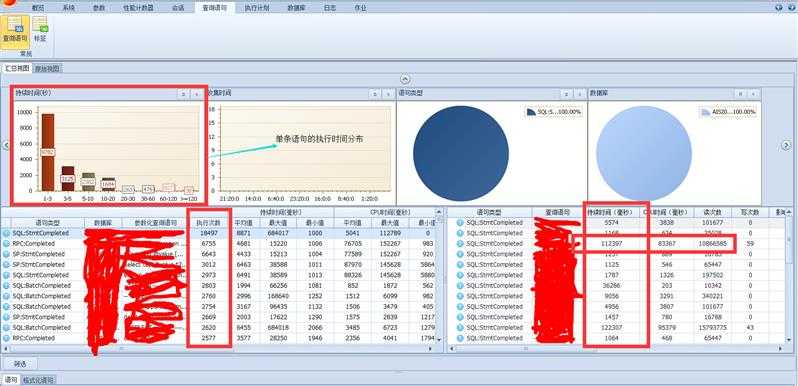
系统优化需要循序渐进,从系统最频繁的语句出发,逐个解决语句问题。
有人看到这会说,博主你有工具,能收集、能统计,我啥也没有咋整?不要急后文脚本都会奉上!
知识储备很重要,语句的优化涉及的地方很多很多,要么为什么说可以写本书呢?
------------------------------------新手区-----------高手勿进-------------------------------------
是不是就没法短时间内,掌握大部分语句的优化技巧呢? 这是可以的,简单介绍一下语句简单粗暴的调优方式:
开启执行计划,让执行计划告诉你,预计慢的原因
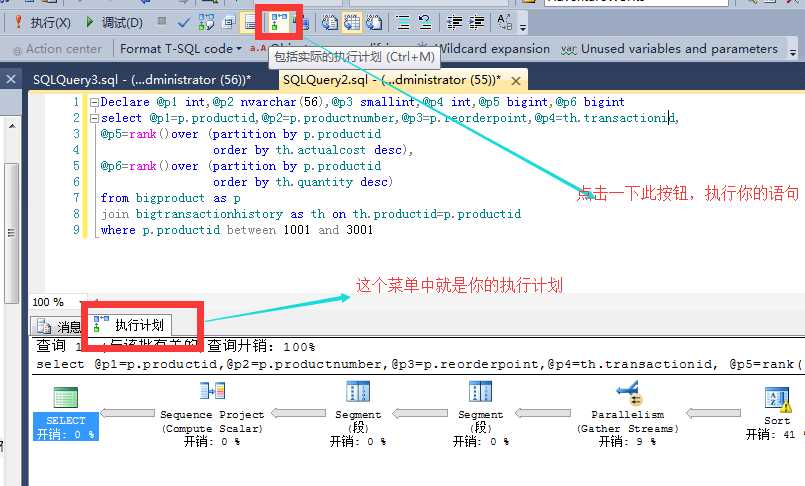
透过计划,一眼看出索引
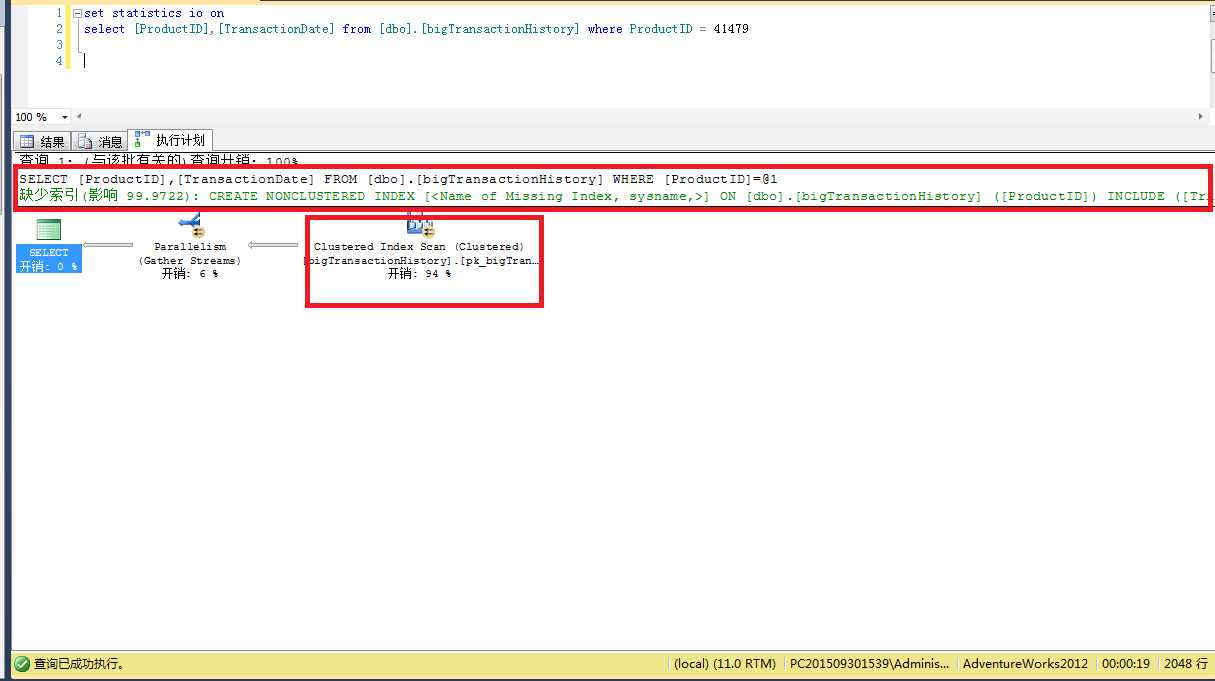
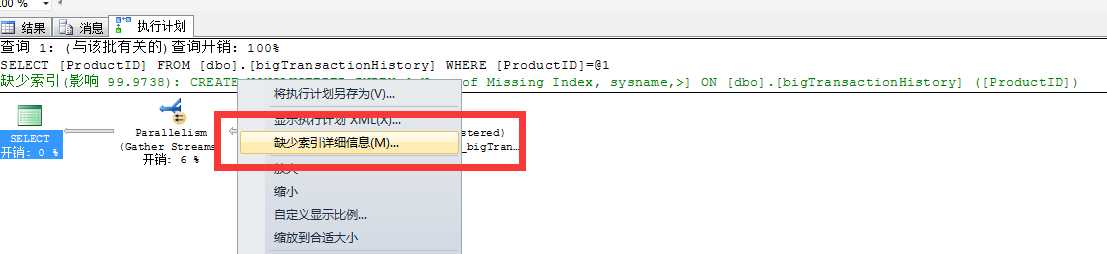
当语句执行后,执行计划中会提示你这条运行的语句中是否缺少索引,右键绿色部分"缺少索引提示",点击缺少索引详细信息,生成对应的索引脚本,创在在数据库中。
在次执行语句验证是否有效,如果还继续提示索引缺失,继续按照此方法创建索引。
索引对于一个语句的影响很大,一个有效的索引可以缩短语句的执行时间,并且降低CPU、IO、内存等消耗。也就是说不但让你的语句执行快,更降低了宝贵的系统资源消耗!
执行计划中除了可以看出缺失的索引,也可以看出语句的主要消耗在哪。知道了主要消耗,我们也就可以针对这个消耗进行优化。如例子中94%的开销在表的扫描上。当看到这个开销很大并且是一个扫描的时候,第一反应要看扫描的表,有没有筛选条件“where”条件,或 “关联条件join" 如果有条件,那就看为什么没有先用条件过滤数据!是不是没有索引? 是不是创建的索引不能用(隐式转换?列上有函数?等等,具体为什么不能使用索引,请自行百度)
高能提示:不要小看索引,感觉这都是小儿科。在我亲身经历的众多客户之中,大面积缺少索引的系统可以占到三层以上。或是软件开发完,对数据库就没有建立索引,或是随着系统的日积月累,数据量、功能也随之增加,系统得不到一个及时的跟踪优化导致。
降低语句的复杂度
讲一个我自己的故事,我刚从业的时候对数据库的优化了解不深,一度认为自己写的SQL 好牛逼,因为现在给我,我真是看不懂。一个语句两张A4纸都打印不下!各种子查询,视图嵌套,函数嵌套,UNION ALL等等等。
不能否认这种语句写出来以后,有种小自豪感!因为别人根本看不懂,改也改不了!这种语句在对于SQL 的优化器来说就是灾难,下面简单的说下优化器拿到一条语句怎么样作出执行计划:
首先传入一个语句,如果有视图,则会把你视图内的代码和外层代码经过二次编译变成一个大语句(多层视图都会编译成一个),然后从表连接开始,优化器会根据统计信息,和一些预查询(如执行所需要的字段类型长度,数据量等)针对你的条件选用一个表作为驱动表,然后继续和其他的表关联,并选用关联方式(hash、merge、nested loop)等,每次关联顺序和方式的都基于SQL的预估,也就是关联的越多,最后的预估可能越不准确,进而导致选用一个比较差的计划。为什么有好的不选却选出一个差的呢?因为优化器不会把你所有执行的可能都验证一次,然后选择一个最好的。这里选出来的“最优”的只是一个相对值。
介绍的有点跑题了,下面我们说一下降低语句复杂度的常用方式:最常用的就是临时表,比如先把条件筛选性较强的几张表关联,然后把结果放入临时表,在用临时表和其他表关联。可以理解成我有10张表关联,我先拿5张表出来关联,然后把结果放入临时表,再跟另外5张表关联。这样这个查询的复杂度由10张表的联合变成 5+6,这样降低了复杂语句复杂度。
复杂视图也是如此,在视图和外层关联前,放入临时表,再跟外层关联。
子查询也是如此,可以分离出来成为临时表的子查询,先分离出来。
情况很多种,最终目的就是降低语句复杂性,让语句分多个步骤执行,这样也可以让优化器每次选出一个比较稳定的计划(一个语句执行有时快有时慢,也很可能是语句的复杂性导致的)。
高能提示:部分系统核心处理的语句比较复杂,且已经很多年前留下的遗产了,经历了一代又一代,我真心不敢碰。那么恭喜你中奖了,好好分析下业务,通过临时表拆分语句还是有可能的!
临时表和表变量,最大的区别是表变量作为中间过程表不能插入太多数据,如果数据插入的多严重影响性能。
降低并行度,或使用并行提升性能
这个小标题好像有些矛盾!解释一下降低并行度是因为现在的服务器配置CPU数都很大64或更多的随处可见,系统选用并行计划时,使用过多的CPU 反而会使性能下降具体请参见:Expert 诊断优化系列------------------你的CPU高么?
首先看一个等待: CXPACKET
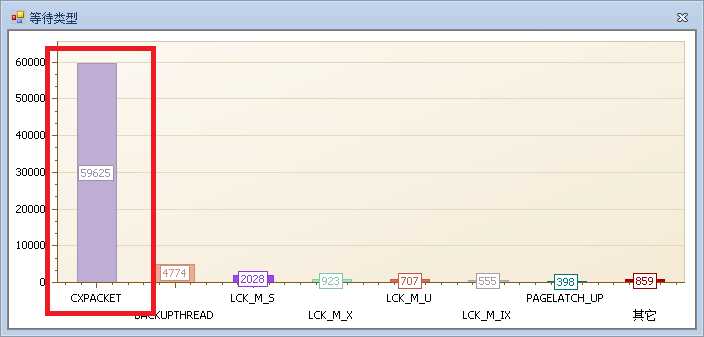
CXPACKET 是最常见的等待之一,等待 并行计划 CPU的调度,或线程上的资源等待,请参见
当你看见如图的等待情况时,说明你系统中并行度需要调整了!请参见系列中的CPU篇,这里不过多介绍。
另一种情况,语句可以通过并行来提升执行时间,这里也不过多介绍,请参见SQL提示介绍-强制并行
使用一切方法降低读次数
一个语句运行起来消耗的读次数也少,说可以间接说明这个语句优化程度较高,读取的页数少也会降低内存和磁盘的压力。
优化时可以开set statistics io on 来观察语句的IO消耗情况。降低IO的主要方式就是添加索引和降低语句复杂度。
注:重点关注读次数多的表!
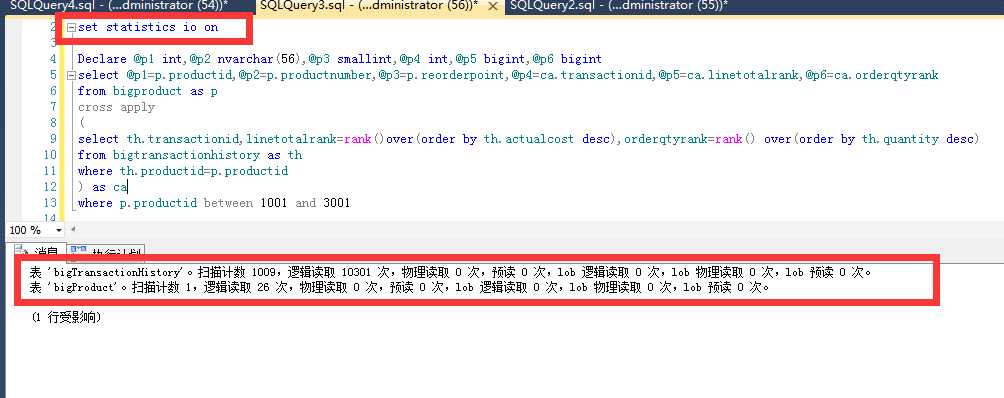
这里就不细说了!
前三篇一直在强调语句很影响服务器资源。但不能忽略的一点就是,语句的运行好坏也很依赖于资源,硬件资源就好比路面环境。语句这车再好,路没有那么宽,也不平坦,再好的车也跑不起来。
反过来就算硬件足够好,路够宽也够好,没有好车也是跑不起来的!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
总结:语句运行的效率是系统的关键,而运行最频繁的语句就是关键中的关键。找出系统运行频率高且效率较差的语句进行优化,是优化思路中的核心。
80%的优化不需要你有高深的技术积累,程咬金的三板斧轮上去,也会扫倒一大片的。请参见 ”常见改装“中的三种手段。
剩下20%的优化就需要对知识的不断积累,在实际场景中获得更好的知识提升。
硬件和语句相互依赖,都是最优的那自然是好,但是作为技术人员我们保证系统语句是最优的,也是一种责任的体现!
本文只是非常简单的介绍常规优化的思路和方法,不足之处请谅解。后续文章中也会针对等待、执行计划、tempDB等继续细说系统的优化。
PS: 优化需要使用各种手段,反复尝试才能达到一个最好的效果,优化无止境。
-------------------------干货到了---------------------------------------------------------------------------
没有自己的SQL工具怎么找出执行频繁的语句呢?
with aa as ( SELECT --执行次数 QS.execution_count, --查询语句 SUBSTRING(ST.text,(QS.statement_start_offset/2)+1, ((CASE QS.statement_end_offset WHEN -1 THEN DATALENGTH(st.text) ELSE QS.statement_end_offset END - QS.statement_start_offset)/2) + 1 ) AS statement_text, --执行文本 ST.text, --执行计划 qs.last_elapsed_time, qs.min_elapsed_time, qs.max_elapsed_time, QS.total_worker_time, QS.last_worker_time, QS.max_worker_time, QS.min_worker_time FROM sys.dm_exec_query_stats QS --关键字 CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) ST WHERE QS.last_execution_time > ‘2016-02-14 00:00:00‘ and execution_count > 500 -- AND ST.text LIKE ‘%%‘ --ORDER BY --QS.execution_count DESC ) select text,max(execution_count) execution_count --,last_elapsed_time,min_elapsed_time,max_elapsed_time from aa where [text] not like ‘%sp_MSupd_%‘ and [text] not like ‘%sp_MSins_%‘ and [text] not like ‘%sp_MSdel_%‘ group by text order by 2 desc
怎么查看自己系统缺失的索引?适合大批量创建索引
这里的DMV信息只是记录自上次SQL Server启动以后的信息项,也就是说每次重启之后这部分信息就丢失了,所以对于生产系统,建议确保运行了一段周期之后再进行查看。
在我们重新创建聚集索引的时候,SQL Server会默认的重新生成全部非聚集索引,如果表数据量特别大,这个过程会很漫长,如果不指定ONLINE的话,这个过程会是锁定索引B-Teee的,这就意味着是阻塞的,业务就要停下来等待完成操作。
------------------缺失索引----------------------- SELECT migs.group_handle, mid.* FROM sys.dm_db_missing_index_group_stats AS migs INNER JOIN sys.dm_db_missing_index_groups AS mig ON (migs.group_handle = mig.index_group_handle) INNER JOIN sys.dm_db_missing_index_details AS mid ON (mig.index_handle = mid.index_handle) WHERE migs.group_handle = 2 ----------------------------------无用索引---------------------- SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.name AS IndexName INTO #TempNeverUsedIndexes FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB ‘USE [?]; INSERT INTO #TempNeverUsedIndexes SELECT DB_NAME() AS DatbaseName , SCHEMA_NAME(O.Schema_ID) AS SchemaName , OBJECT_NAME(I.object_id) AS TableName , I.NAME AS IndexName FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id AND I.index_id = S.index_id AND DATABASE_ID = DB_ID() WHERE OBJECTPROPERTY(O.object_id,‘‘IsMsShipped‘‘) = 0 AND I.name IS NOT NULL AND S.object_id IS NULL‘ SELECT * FROM #TempNeverUsedIndexes ORDER BY DatbaseName, SchemaName, TableName, IndexName DROP TABLE #TempNeverUsedIndexes --------------------------经常被大量更新,但是却基本不适用的索引项-------------------- SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED SELECT DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] INTO #TempUnusedIndexes FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE 1=2 EXEC sp_MSForEachDB ‘USE [?]; INSERT INTO #TempUnusedIndexes SELECT TOP 20 DB_NAME() AS DatabaseName , SCHEMA_NAME(o.Schema_ID) AS SchemaName , OBJECT_NAME(s.[object_id]) AS TableName , i.name AS IndexName , s.user_updates , s.system_seeks + s.system_scans + s.system_lookups AS [System usage] FROM sys.dm_db_index_usage_stats s INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id] AND s.index_id = i.index_id INNER JOIN sys.objects o ON i.object_id = O.object_id WHERE s.database_id = DB_ID() AND OBJECTPROPERTY(s.[object_id], ‘‘IsMsShipped‘‘) = 0 AND s.user_seeks = 0 AND s.user_scans = 0 AND s.user_lookups = 0 AND i.name IS NOT NULL ORDER BY s.user_updates DESC‘ SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC DROP TABLE #TempUnusedIndexes
----------------------------------------------------------------------------------------------------
注:此文章为原创,欢迎转载,请在文章页面明显位置给出此文链接!
若您觉得这篇文章还不错请点击下右下角的推荐,非常感谢!
引用高大侠的一句话 :“拒绝SQL Server背锅,从我做起!”
Expert 诊断优化系列------------------语句调优
标签:
原文地址:http://www.cnblogs.com/double-K/p/5544439.html