标签:
数据接入Spark Streaming的二种方式:Receiver和no receivers方式
建议企业级采用no receivers方式开发Spark Streaming应用程序,好处:
1、更优秀的自由度控制
2、语义一致性
no receivers更符合数据读取和数据操作,Spark 计算框架底层有数据来源,如果只有direct直接操作数据来源则更天然。操作数据来源封装其一定是rdd级别的。
所以Spark 推出了自定义的rdd即Kafkardd,只是数据来源不同。
进入源码区:
注释基于Batch消费数据,首先确定开始和结束的offSet,特别强调语义一致性。
关键是metaData.broker.list,通过bootstrap.servers直接操作Kafka集群,操作kafka数据是一个offset范围。
/**
* A batch-oriented interface for
consuming from Kafka.
* Starting and ending offsets are
specified in advance,
* so that you can control exactly-once
semantics.
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>. Requires "metadata.broker.list" or
"bootstrap.servers" to be set
* with Kafka broker(s) specified in
host1:port1,host2:port2 form.
* @param offsetRanges offset
ranges that define the Kafka data belonging to this RDD
* @param messageHandler function
for translating each message into the desired type
*/
private[kafka]
class KafkaRDD[
K:
ClassTag,
V:
ClassTag,
U <:
Decoder[_]: ClassTag,
T <:
Decoder[_]: ClassTag,
R:
ClassTag] private[spark] (
sc: SparkContext,
kafkaParams: Map[String, String],
val offsetRanges: Array[OffsetRange],
leaders: Map[TopicAndPartition, (String, Int)],
messageHandler: MessageAndMetadata[K, V] => R
) extends
RDD[R](sc, Nil) with Logging with
HasOffsetRanges {
你要直接访问Kafka中的数据需要自定义一个KafkaRDD,如果读取hBase上的数据
也必须自定义一个hBaseRDD。有一点必须定义接口HasOffsetRange,RDD天然的是一个
A List Partitions,基于kafka直接访问RDD时必须是HasOffsetRange类型,代表了
来自kafka topicAndParttion,其实力被HasOffsetRange Create创建,从fromOffset到untilOffset ,
分布式传输Offset数据时必须序列化。
/**
* Represents any object that has a
collection of [[OffsetRange]]s. This can be used to access the
* offset ranges in RDDs generated by the
direct Kafka DStream (see
* [[KafkaUtils.createDirectStream()]]).
* {{{
*
KafkaUtils.createDirectStream(...).foreachRDD { rdd =>
*
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
*
...
*
}
* }}}
*/
trait HasOffsetRanges
{
def
offsetRanges: Array[OffsetRange]
}
/**
* Represents a range of offsets from a
single Kafka TopicAndPartition. Instances of this class
* can be created with `OffsetRange.create()`.
* @param topic Kafka topic name
* @param partition Kafka
partition id
* @param fromOffset Inclusive
starting offset
* @param untilOffset Exclusive
ending offset
*/
final class OffsetRange
private(
val
topic: String,
val partition:
Int,
val fromOffset:
Long,
val untilOffset:
Long) extends Serializable {
import
OffsetRange.OffsetRangeTuple
/**
Kafka TopicAndPartition object, for convenience */
def
topicAndPartition(): TopicAndPartition = TopicAndPartition(topic, partition)
/**
Number of messages this OffsetRange refers to */
def
count(): Long = untilOffset - fromOffset
Offset是消息偏移量,假设untilOffset是10万,fromOffset是5万,第10万条消息
和5万条消息,一般处理数据规模大小是以数据条数为单位。
创建一个offSetrange实例时可以确定从kafka集群partition中读取哪些topic,从
foreachrdd中可以获得当前rdd访问的所有分区数据。Batch Duration中产生的rdd的分区数据,这个是对元数据的控制。
在看getPartitions方法,offsetRanges指定了每个offsetrange从什么位置开始到什么位置结束。
override def getPartitions: Array[Partition] = {
offsetRanges.zipWithIndex.map { case (o, i)
=>
val
(host, port) = leaders(TopicAndPartition(o.topic, o.partition))
new
KafkaRDDPartition(i, o.topic, o.partition, o.fromOffset, o.untilOffset, host, port)
}.toArray
}
看KafkaRDDPartition类,会从传入的topic和partition及offset中获取kafka数据
/** @param topic kafka topic name
* @param partition kafka
partition id
* @param fromOffset inclusive
starting offset
* @param untilOffset exclusive
ending offset
* @param host preferred kafka
host, i.e. the leader at the time the rdd was created
* @param port preferred kafka
host‘s port
*/
private[kafka]
class KafkaRDDPartition(
val index:
Int,
val topic: String,
val partition: Int,
val fromOffset: Long,
val untilOffset: Long,
val host: String,
val port: Int
) extends Partition {
/** Number of messages this partition refers to */
def count(): Long =
untilOffset - fromOffset
}
Host port指定读取数据来源的kfakf机器。
看kafka rdd的compute计算每个数据分片,和rdd理念是一样的,每次迭代操作获取计算的rdd一部分。
操作KafkaRDDIterator和操作rdd分片是一样的,需要迭代数据分片:
override def compute(thePart: Partition, context: TaskContext): Iterator[R] = {
val part
= thePart.asInstanceOf[KafkaRDDPartition]
assert(part.fromOffset <=
part.untilOffset, errBeginAfterEnd(part))
if (part.fromOffset
== part.untilOffset) {
log.info(s"Beginning offset ${part.fromOffset} is the same as ending offset " +
s"skipping ${part.topic}
${part.partition}")
Iterator.empty
} else
{
new KafkaRDDIterator(part, context)
}
}
private class KafkaRDDIterator(
part: KafkaRDDPartition,
context: TaskContext) extends NextIterator[R] {
context.addTaskCompletionListener{
context => closeIfNeeded() }
log.info(s"Computing topic ${part.topic}, partition ${part.partition}
" +
s"offsets ${part.fromOffset} -> ${part.untilOffset}")
val kc = new KafkaCluster(kafkaParams)
val keyDecoder
= classTag[U].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(kc.config.props)
.asInstanceOf[Decoder[K]]
val valueDecoder
= classTag[T].runtimeClass.getConstructor(classOf[VerifiableProperties])
.newInstance(kc.config.props)
.asInstanceOf[Decoder[V]]
val consumer
= connectLeader
var requestOffset
= part.fromOffset
var iter: Iterator[MessageAndOffset]
= null
// The idea is to use the provided preferred host, except
on task retry attempts,
// to minimize number of kafka metadata
requests
private def connectLeader: SimpleConsumer
= {
if (context.attemptNumber
> 0) {
kc.connectLeader(part.topic, part.partition).fold(
errs => throw new SparkException(
s"Couldn‘t connect to leader for topic ${part.topic} ${part.partition}: " +
errs.mkString("\n")),
consumer => consumer
)
} else {
kc.connect(part.host, part.port)
}
}
private def handleFetchErr(resp:
FetchResponse) {
if (resp.hasError)
{
val err
= resp.errorCode(part.topic, part.partition)
if (err
== ErrorMapping.LeaderNotAvailableCode
||
err == ErrorMapping.NotLeaderForPartitionCode) {
log.error(s"Lost leader for topic ${part.topic} partition ${part.partition}, " +
s" sleeping for ${kc.config.refreshLeaderBackoffMs}ms")
Thread.sleep(kc.config.refreshLeaderBackoffMs)
}
// Let normal rdd retry sort out reconnect attempts
throw ErrorMapping.exceptionFor(err)
}
}
关键的地方kafkaCluster对象时在kafkaUtils中直接创建了directStream,看下之前操作kafka代码发现传入的参数是上下文、 broker.List.topic.list参数:
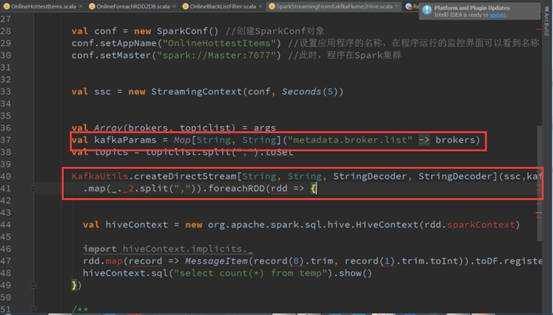
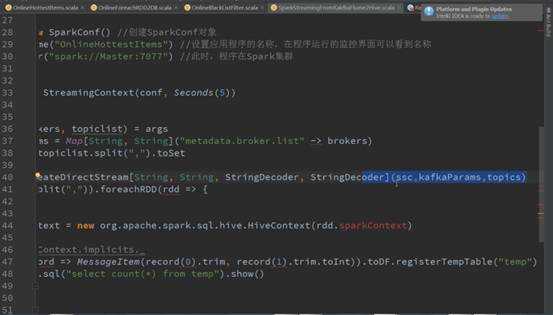
构建时传入topics为Set,当然可以直接指定ranges,他从kafka集群直接创建了kafkaCluster和集群进行交互,从fromOffset获取数据具体的偏移量:
/**
* Create an input stream that directly
pulls messages from Kafka Brokers
* without using any receiver. This
stream can guarantee that each message
* from Kafka is included in
transformations exactly once (see points below).
*
* Points to note:
*
- No receivers: This stream does not use any receiver. It directly
queries Kafka
*
- Offsets: This does not use Zookeeper to store offsets. The consumed
offsets are tracked
*
by the stream itself. For interoperability with Kafka monitoring tools
that depend on
*
Zookeeper, you have to update Kafka/Zookeeper yourself from the
streaming application.
*
You can access the offsets used in each batch from the generated RDDs
(see
*
[[org.apache.spark.streaming.kafka.HasOffsetRanges]]).
*
- Failure Recovery: To recover from driver failures, you have to enable
checkpointing
*
in the [[StreamingContext]]. The information on consumed offset can be
*
recovered from the checkpoint. See the programming guide for details
(constraints, etc.).
*
- End-to-end semantics: This stream ensures that every records is
effectively received and
*
transformed exactly once, but gives no guarantees on whether the
transformed data are
*
outputted exactly once. For end-to-end exactly-once semantics, you have
to either ensure
*
that the output operation is idempotent, or use transactions to output
records atomically.
*
See the programming guide for more details.
*
* @param ssc StreamingContext
object
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
*
configuration parameters</a>. Requires "metadata.broker.list" or
"bootstrap.servers"
*
to be set with Kafka broker(s) (NOT zookeeper servers), specified in
*
host1:port1,host2:port2 form.
*
If not starting from a checkpoint, "auto.offset.reset" may be
set to "largest" or "smallest"
*
to determine where the stream starts (defaults to "largest")
* @param topics Names of the
topics to consume
* @tparam K type of Kafka message
key
* @tparam V type of Kafka message
value
* @tparam KD type of Kafka message
key decoder
* @tparam VD type of Kafka
message value decoder
* @return DStream of (Kafka
message key, Kafka message value)
*/
def createDirectStream[
K: ClassTag,
V: ClassTag,
KD <: Decoder[K]:
ClassTag,
VD <: Decoder[V]:
ClassTag] (
ssc: StreamingContext,
kafkaParams:
Map[String, String],
topics:
Set[String]
): InputDStream[(K, V)] = {
val
messageHandler = (mmd: MessageAndMetadata[K, V]) => (mmd.key, mmd.message)
val
kc = new KafkaCluster(kafkaParams)
val
fromOffsets = getFromOffsets(kc, kafkaParams, topics)
new
DirectKafkaInputDStream[K, V, KD, VD, (K, V)](
ssc, kafkaParams, fromOffsets, messageHandler)
看下getFromOffsets方法:
private[kafka] def getFromOffsets(
kc: KafkaCluster,
kafkaParams: Map[String, String],
topics: Set[String]
): Map[TopicAndPartition, Long] = {
val reset
= kafkaParams.get("auto.offset.reset").map(_.toLowerCase)
val result
= for {
topicPartitions <-
kc.getPartitions(topics).right
leaderOffsets <- (if (reset == Some("smallest")) {
kc.getEarliestLeaderOffsets(topicPartitions)
} else {
kc.getLatestLeaderOffsets(topicPartitions)
}).right
} yield {
leaderOffsets.map { case (tp, lo) =>
(tp, lo.offset)
}
}
KafkaCluster.checkErrors(result)
}
如果不知道fromOffsets的话直接从配置中获取fromOffsets,创建kafka DirectKafkaInputDStream的时候会从kafka集群进行交互获得partition、offset信息,通过DirectKafkaInputDStream无论什么情况最后都会创建DirectKafkaInputDStream:
/**
*
A stream of {@link org.apache.spark.streaming.kafka.KafkaRDD}
where
* each given Kafka topic/partition
corresponds to an RDD partition.
* The spark configuration
spark.streaming.kafka.maxRatePerPartition gives the maximum number
*
of messages
* per second that each ‘‘‘partition‘‘‘ will accept.
* Starting offsets are specified in
advance,
* and this DStream is not responsible
for committing offsets,
* so that you can control exactly-once
semantics.
* For an easy interface to Kafka-managed
offsets,
*
see {@link org.apache.spark.streaming.kafka.KafkaCluster}
* @param kafkaParams Kafka <a href="http://kafka.apache.org/documentation.html#configuration">
* configuration parameters</a>.
*
Requires "metadata.broker.list" or
"bootstrap.servers" to be set with Kafka broker(s),
*
NOT zookeeper servers, specified in host1:port1,host2:port2 form.
* @param fromOffsets per-topic/partition
Kafka offsets defining the (inclusive)
*
starting point of the stream
* @param messageHandler function
for translating each message into the desired type
*/
private[streaming]
class DirectKafkaInputDStream[
K:
ClassTag,
V:
ClassTag,
U <:
Decoder[K]: ClassTag,
T <:
Decoder[V]: ClassTag,
R:
ClassTag](
ssc_ : StreamingContext,
val kafkaParams: Map[String, String],
val fromOffsets: Map[TopicAndPartition, Long],
messageHandler: MessageAndMetadata[K, V] => R
) extends
InputDStream[R](ssc_)
with Logging {
val maxRetries
= context.sparkContext.getConf.getInt(
"spark.streaming.kafka.maxRetries", 1)
DirectKafkaInputDStream会产生kafkaRDD,不同的topic partitions生成对应的的kafkarddpartitions,控制消费读取速度。操作数据的时候是compute直接构建出kafka rdd,读取kafka 上的数据。确定获取读取数据的期间就知道需要读取多少条数据,然后构建kafkardd实例。Kafkardd的实例和DirectKafkaInputDStream是一一对应的,每次compute会产生一个kafkardd,其会包含很多partitions,有多少partition就是对应多少kafkapartition。
看下KafkaRDDPartition就是一个简单的数据结构:
/** @param topic kafka topic name
* @param partition kafka
partition id
* @param fromOffset inclusive
starting offset
* @param untilOffset exclusive
ending offset
* @param host preferred kafka
host, i.e. the leader at the time the rdd was created
* @param port preferred kafka
host‘s port
*/
private[kafka]
class KafkaRDDPartition(
val index:
Int,
val topic: String,
val partition: Int,
val fromOffset: Long,
val untilOffset: Long,
val host: String,
val port: Int
) extends Partition {
/** Number of messages this partition refers to */
def count(): Long =
untilOffset - fromOffset
}
总结:
而且KafkaRDDPartition只能属于一个topic,不能让partition跨多个topic,直接消费一个kafkatopic,topic不断进来、数据不断偏移,Offset代表kafka数据偏移量指针。
数据不断流进kafka,batchDuration假如每十秒都会从配置的topic中消费数据,每次会消费一部分直到消费完,下一个batchDuration会再流进来的数据,又可以从头开始读或上一个数据的基础上读取数据。
思考直接抓取kafka数据和receiver读取数据:
好处一:
直接抓取fakfa数据的好处,没有缓存,不会出现内存溢出等之类的问题。但是如果kafka Receiver的方式读取会存在缓存的问题,需要设置读取的频率和block interval等信息。
好处二:
采用receiver方式的话receiver默认情况需要和worker的executor绑定,不方便做分布式,当然可以配置成分布式,采用direct方式默认情况下数据会存在多个worker上的executor。Kafkardd数据默认都是分布在多个executor上的,天然数据是分布式的存在多个executor,而receiver就不方便计算。
好处三:
数据消费的问题,在实际操作的时候采用receiver的方式有个弊端,消费数据来不及处理即操作数据有deLay多才时,Spark Streaming程序有可能奔溃。但如果是direct方式访问kafka数据不会存在此类情况。因为diect方式直接读取kafka数据,如果delay就不进行下一个batchDuration读取。
好处四:
完全的语义一致性,不会重复消费数据,而且保证数据一定被消费,跟kafka进行交互,只有数据真正执行成功之后才会记录下来。
生产环境下强烈建议采用direct方式读取kafka数据。
感谢王家林老师的知识分享
王家林老师名片:
中国Spark第一人
感谢王家林老师的知识分享
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
YY课堂:每天20:00现场授课频道68917580
Spark Streaming发行版笔记15:no receivers彻底思考
标签:
原文地址:http://www.cnblogs.com/sparkbigdata/p/5544602.html