标签:
本文通过比较基于纹理的方法和基于连通分量的方法发现对于复杂的背景使用基于连通分量的方法较好.
一、基于连通分量的方法和基于纹理的方法比较如下:
基于纹理的方法:将图像分割成块,然后提取块的纹理特征,并用分类器确认.
基于连通分量的方法:它是假设同一文本区域的字符具有相同的颜色,根据字符颜色的一致性及字符与背景有较大的颜色差来分割图像,提取连通分量,对连通分量利用几何约束关系得到文本区域.
基于纹理的方法的鲁棒性对于定位小字符的文本区域具有较好的效果,对噪声具有较高的抑制性.但是当定位大字符时,由于难以定位字符数量较少的文本区域,对文本区域的边框不能很精确的定位,因此所得到的效果很差.由于基于连通分量的定位是通过与背景的颜色相比较来定位文本所以效果比基于纹理的方法要好.
二、本文采用自适应图像分割,该方法的计算如下:
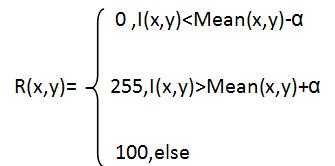
其中,I(x,y)为某个像素点灰度值,Mean为像素邻域内的均值,α为字符与背景方差描述阈值,像素邻域的大小和 α通过实验进行确定.
三、特征提取
本文主要提取三类特征,分别为基本特征,粗糙度特征和笔画宽度特征。基本特征包括面积、高度、宽度和周长。面积和周长可以排除大量太大或者太小的非字符连通分量。粗糙度特征用于表示字符轮廓较光滑,并且有直线条构成的特点。主要过程有:(1)提取外接轮廓的4方向链码;(2)对链码进行查分,并进行 模运算确定两个相邻像素之间码值的变化程度;(3)统计连续的3个链码值差分值的模式是否符合粗糙点模式。由于字符一般有一致宽度的笔画构成,所以笔画宽度是 字符连通分量和非字符连通分量的最显著的区别。
四、Adaboost 分类
基本思想是 通过训练具有若干个具有低错误率的弱分类器,然后组成强分类器。训练过程的基本算法流程如下:
(1)初始化样本权重;
(2)进行T次训练得到T个弱分类器h(x)。主要分为三部分:一、所有样本的权重归一化;二、对于每个特征j,确定阈值Thi 和偏置Pj,使得错误率最小,并找出错误率最小的弱分类器;三、更新样本权重。
(3)T次训练后得到最后的墙分类
器为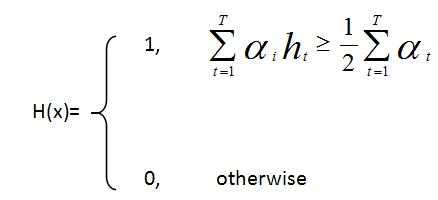
文本行识别采用K-means聚类算法:具体表现在以下三个方面
1、初始K 值得选择,采用连通分量的1/6作为初始k的值;
2、初始化点的选择,将对候选连通分量排列,均匀去K个初始值;
3、‘’‘’‘
A=imread(‘E:\mmtlable\tutu.png‘);
figure;
imshow(A);
title(‘Hawk‘);
cform=makecform(‘srgb2lab‘);
lab_A=applycform(A,cform); %这里为什么要转去lab空间,其他的转换不好用吗?对于颜色分割的吧 lab空间相互分量联系性比较小 利于分割
ab = double(lab_A(:,:,2:3));
nrows = size(ab,1);
ncols = size(ab,2);
ab = reshape(ab,nrows*ncols,2);% 矩阵转换类型转换为double型,这里的转换有其他的灵活用法吗?
nColors =2;
% 采用k-means方法实现聚类,重复三次
[cluster_idx cluster_center] = kmeans(ab,nColors,‘distance‘,‘sqEuclidean‘, ...
‘Replicates‘,3); %这一段东西后面的省略号是啥意思啊?省略号表示一行写不完 分行的 意思就是kmeans(ab,nColors,‘distance‘,‘sqEuclidean‘, ‘Replicates‘,3); 一样的
%对不同的类别进行标志
pixel_labels = reshape(cluster_idx,nrows,ncols); %这里也是矩阵转换吗?恩师矩阵转化 你最好看看help
figure;
imshow(pixel_labels,[]), title(‘聚类以后的现实图片‘);
%分类后的矩阵
segmented_images = cell(1,3);
rgb_label = repmat(pixel_labels,[1 1 3]);
for k = 1:nColors
color = A;
color(rgb_label ~= k) = 0;
segmented_images{k} = color;
end
figure;
imshow(segmented_images{1}), title(‘objects in cluster 1‘);
figure;
imshow(segmented_images{2}), title(‘objects in cluster 2‘);
标签:
原文地址:http://www.cnblogs.com/1510152012huang/p/5547874.html