标签:
一般情况下我们人类大脑可以在没有明确指示的情况下处理绝大部分问题。例如,你做房产经纪时间很长,你对于房产的合适定价、它的最佳营销方式以及哪些客户会感兴趣等等都会有一种本能般的“感觉”。强人工智能(Strong AI)研究的目标就是要让计算机能这样思考。
但是目前的机器学习算法还没有那么好——它们只能专注于非常特定的、有限的问题。也许在这种情况下,“机器学习”更贴切的定义是“在少量范例数据的基础上找出一个等式来解决特定的问题”。
不幸的是,“机器在少量范例数据的基础上找出一个等式来解决特定的问题”这个名字太绕口。所以最后我们用“机器学习”取而代之。
前面例子中评估房价的程序,你打算怎么写呢?可以先思考一下。
如果你对机器学习一无所知,很有可能你会尝试写出一些基本规则来评估房价,如下:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# In my area, the average house costs $200 per sqft
price_per_sqft = 200
if neighborhood == "hipsterton":
# but some areas cost a bit more
price_per_sqft = 400
elif neighborhood == "skid row":
# and some areas cost less
price_per_sqft = 100
# start with a base price estimate based on how big the place is
price = price_per_sqft * sqft
# now adjust our estimate based on the number of bedrooms
if num_of_bedrooms == 0:
# Studio apartments are cheap
price = price?—?20000
else:
# places with more bedrooms are usually
# more valuable
price = price + (num_of_bedrooms * 1000)
return price
假如你像这样瞎忙几个小时,也许会取得一点成效,但是你的程序永不会完美,而且当价格变化时很难维护。
如果能让计算机找出实现上述函数功能的办法,这样岂不更好?只要返回的房价数字正确,谁会在乎函数具体干了些什么呢?
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = <computer, plz do some math for me> return price
考虑这个问题的一种角度是将房价看做一碗美味的汤,而汤中成分就是卧室数、面积和地段。如果你能算出每种成分对最终的价格有多大影响,也许就能得到各种成分混合起来形成最终价格的具体比例。
这样可以将你最初的程序(全是疯狂的if else语句)简化成类似如下的样子:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * .841231951398213 # and a big pinch of that price += sqft * 1231.1231231 # maybe a handful of this price += neighborhood * 2.3242341421 # and finally, just a little extra salt for good measure price += 201.23432095 return price
请注意那些用粗体标注的神奇数字——.841231951398213, 1231.1231231,2.3242341421, 和201.23432095。它们称为权重。如果我们能找出对每栋房子都适用的完美权重,我们的函数就能预测所有的房价!
找出最佳权重的一种笨办法如下所示:
首先,将每个权重都设为1.0:
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): price = 0 # a little pinch of this price += num_of_bedrooms * 1.0 # and a big pinch of that price += sqft * 1.0 # maybe a handful of this price += neighborhood * 1.0 # and finally, just a little extra salt for good measure price += 1.0 return price
步骤2:
将每栋房产带入你的函数运算,检验估算值与正确价格的偏离程度:

运用你的程序预测房屋价格。
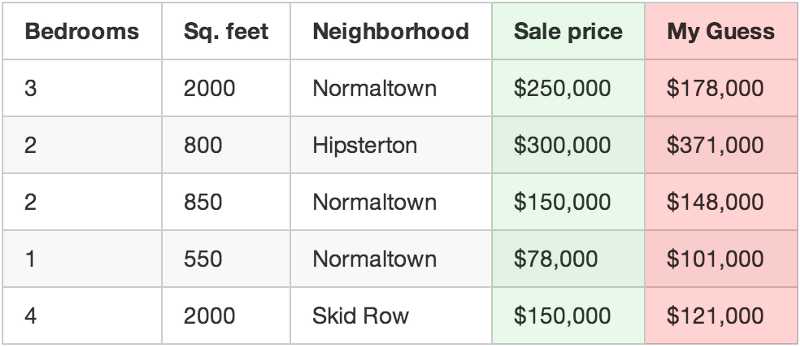
例如:上表中第一套房产实际成交价为25万美元,你的函数估价为17.8万,这一套房产你就差了7.2万。
再将你的数据集中的每套房产估价偏离值平方后求和。假设数据集中有500套房产交易,估价偏离值平方求和总计为86,123,373美元。这就反映了你的函数现在的“正确”程度。
现在,将总计值除以500,得到每套房产的估价偏离平均值。将这个平均误差值称为你函数的代价。
如果你能调整权重使得这个代价变为0,你的函数就完美了。它意味着,根据输入的数据,你的程序对每一笔房产交易的估价都是分毫不差。而这就是我们的目标——尝试不同的权重值以使代价尽可能的低。
不断重复步骤2,尝试所有可能的权重值组合。哪一个组合使得代价最接近于0,它就是你要使用的,你只要找到了这样的组合,问题就得到了解决!
这太简单了,对吧?想一想刚才你做了些什么。你取得了一些数据,将它们输入至三个通用的简单步骤中,最后你得到了一个可以对你所在区域的房屋进行估价的函数。
但是下面的事实可能会扰乱你的思想:
1.过去40年来,很多领域(如语言学/翻译学)的研究表明,这种通用的权重运算方式的学习算法已经胜过了需要利用真人明确规则的方法。机器学习的“笨”办法最终打败了人类专家。
2.你最后写出的函数真是笨,它甚至不知道什么是“面积”和“卧室数”。它知道的只是搅动,改变数字来得到正确的答案。
3.很可能你都不知道为何一组特殊的权重值能起效。所以你只是写出了一个你实际上并不理解却能证明的函数。
4.试想一下,你的程序里没有类似“面积”和“卧室数”这样的参数,而是接受了一组数字。假设每个数字代表了你车顶安装的摄像头捕捉的画面中的一个像素,再将预测的输出不称为“价格”而是叫做“方向盘转动度数”,这样你就得到了一个程序可以自动操纵你的汽车了!
太疯狂了,对吧?
好吧,当然你不可能尝试所有可能的权重值来找到效果最好的组合。那可真要花很长时间,因为要尝试的数字可能无穷无尽。
为避免这种情况,数学家们找到了很多聪明的办法(维基百科)来快速找到优秀的权重值,而不需要尝试过多。下面是其中一种:
首先,写出一个简单的等式表示前述步骤2:
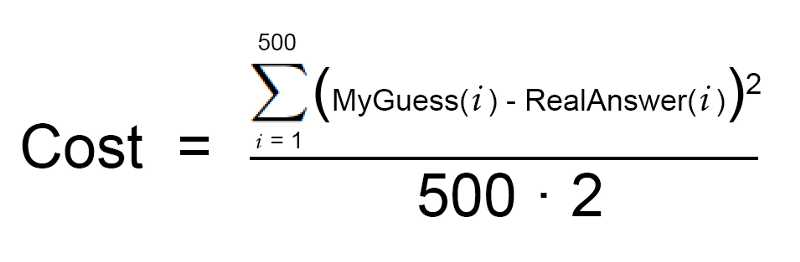

接着,让我们将这同一个等式用机器学习的数学术语(现在你可以忽略它们)进行重写:
θ表示当前的权重值。 J(θ) 意为“当前权重值对应的代价”。
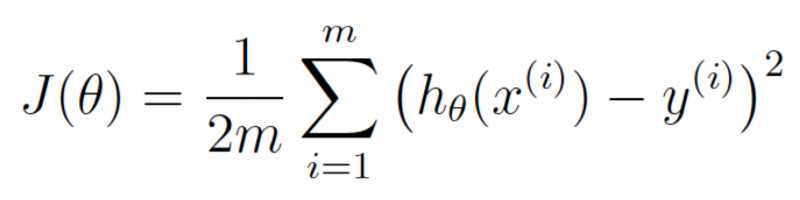

这个等式表示我们的估价程序在当前权重值下偏离程度的大小。
如果将所有赋给卧室数和面积的可能权重值以图形形式显示,我们会得到类似下图的图表:
事实上这个图在以后的学习中会遇到,我们一般给它取名叫损失函数与参数之间的曲面图

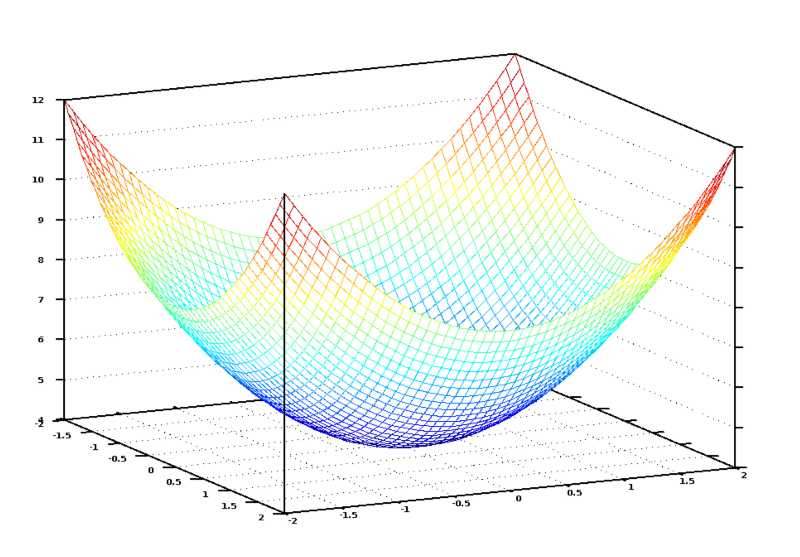
图中蓝色的最低点就是代价最低的地方——即我们的程序偏离最小。最高点意味着偏离最大。所以,如果我们能找到一组权重值带领我们到达图中的最低点,我们就找到了答案!

因此,我们只需要调整权重值使我们在图上能向着最低点“走下坡路”。如果对于权重的细小调节能一直使我们保持向最低点移动,那么最终我们不用尝试太多权重值就能到达那里。
如果你还记得一点微积分的话,你也许记得如果你对一个函数求导,结果会告诉你函数在任一点的斜率。换句话说,对于图上给定一点,它告诉我们那条路是下坡路。我们可以利用这一点朝底部进发。
所以,如果我们对代价函数关于每一个权重求偏导,那么我们就可以从每一个权重中减去该值。这样可以让我们更加接近山底。一直这样做,最终我们将到达底部,得到权重的最优值。(读不懂?不用担心,接着往下读)。
这种找出最佳权重的办法被称为批量梯度下降,上面是对它的高度概括。如果想搞懂细节,不要害怕,我们在后面会继续学习。
先简单发一张损失函数的等高线图来镇楼:
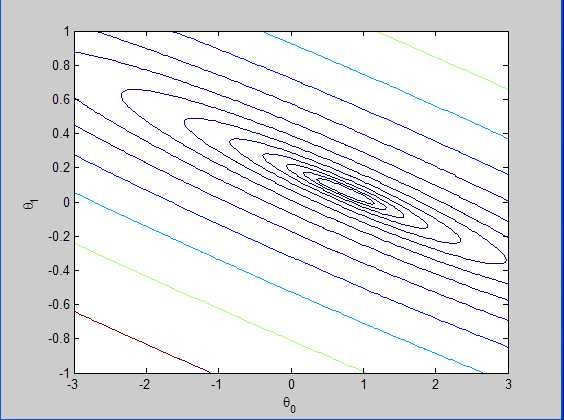
当你使用机器学习算法库来解决实际问题,所有这些都已经为你准备好了。但明白一些具体细节总是有用的。
其时上面整个内容介绍的就是机器学习中的一种思想:多元线性回归,一种深度学习算法。即根据多个数据样本生成一个问题解决方案。
这边的内容需要有一定的入门知识,我打算按照这个方向学习下去(加个好友一起学习啊)。
一旦你开始明白机器学习技术很容易应用于解决貌似很困难的问题(如手写识别),你心中会有一种感觉,只要有足够的数据,你就能够用机器学习解决任何问题。只需要将数据输入进去,就能看到计算机变戏法一样找出拟合数据的等式。
但是很重要的一点你要记住,机器学习只能对用你占有的数据实际可解的问题才适用。
例如,如果你建立了一个模型来根据每套房屋内盆栽数量来预测房价,它就永远不会成功。房屋内盆栽数量和房价之间没有任何的关系。所以,无论它怎么去尝试,计算机也推导不出两者之间的关系。
打算采用Andrew Ng的网页教程UFLDL Tutorial,据说这个教程写得浅显易懂,也不太长。不过在这这之前还是复习下machine learning的基础知识,见网页:http://openclassroom.stanford.edu/MainFolder/CoursePage.php?course=DeepLearning。内容其实很短,每小节就那么几分钟,且讲得非常棒。
入门已经结束,接下来还有好几座大山去爬。共勉!!
标签:
原文地址:http://www.cnblogs.com/dinghing154/p/5550493.html