标签:
系统高可用,或者说系统的可用性,在计算机领域是一个相当久远并且重要的概念。小到CPU芯片、内存、硬盘等硬件组件,大到支付宝、微信等日常互联网服务,在设计、开发、维护的时候,都离不开对它的考量。本文首先介绍跟系统可用性相关的关键概念,然后讨论高可用系统的评价指标。
一个系统的可用性,由组成这个系统的模块的可用性,以及模块之间的关系决定。模块可以看成一个系统,由更小的子模块组成,而系统可以看成一个模块,从而组成更大的系统。所以计算机系统的可用性,可以一层一层这样递归讨论下去。讨论系统的可用性,就是讨论模块的可用性。
一个模块的行为分为标准行为(specified behavior)和实际行为(observed behavior)。设计和开发这个模块时定义的标准输入和输出称之为标准行为,模块实际工作过程中观察到的输入和输出称之为实际行为。当实际行为与标准行为不一致的情况,定义为模块发生了失败(failure)。比如我们在网站上点击一个新闻链接,标准行为是显示一个包含新闻详细内容的网页,而实际展示了一个错误页面,这就发生了失败。比如一个key-val数据库,我们给定key读取,应当返回val或者空,却返回了"未通过校验",这就发生了失败。
错误(error)是导致模块失败(failure)发生的原因。比如新闻页面没能正常显示的失败,可能是数据库服务器宕机这个错误导致的。比如一个Key-Val数据库读取的错误,可能是硬盘损坏导致的。需要注意的是,错误存在并不一定会导致失败,比如key-val数据库的例子,硬盘损坏的错误发生之后,只有当我们需要读取损坏处的数据时,失败才会发生。
故障(fault)是导致错误(error)发生的原因。比如数据库宕机的的原因,可能是服务器电源故障。硬盘损坏的原因,可能是硬盘服务年限过长。错误和故障,并非只存在于硬件。比如,程序员写的代码里隐藏了一个bug,上线后这就是一个错误(error),导致这个错误的原因可能是程序员水平不行或者测试流程不规范,这是故障(fault),当在特定的条件下,这个bug被触发,影响了系统的行为,那么失败(failure)就发生了。
下图描述了上述几个概念之间的关系:
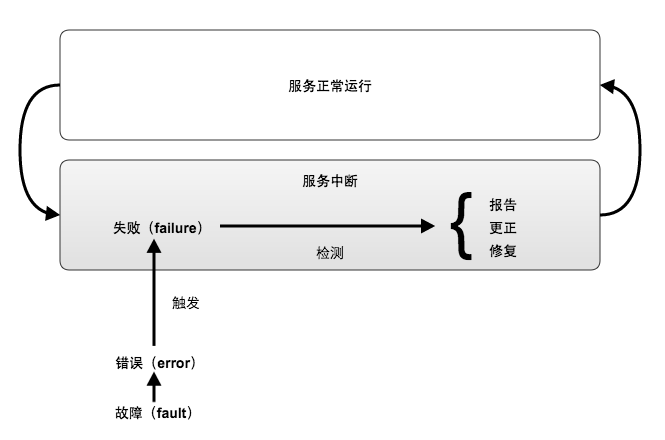
如上图所示,Failure导致模块服务中断,而检测到该错误之后,经过报告、更正、修复等过程后,模块恢复正常服务。通常使用MTTF和MTTR来量化一个模块的可用性。
MTTF(mean time to failure),指模块处在正常服务状态的平均时间。
MTTR(mean time to repair),指模块处在服务中断状态的平均时间。
模块可用性,指模块处在正常服务状态的时间与总的模块服务时间的比例。可以量化定义为:
MTTF/(MTTF + MTTR)
从我们讨论的概念入手,也就是说从引起模块失败的原因着手,才能提升模块可用性。具体可分为以下两大类,分别展开又是大话题,本文不再展开。
如果一个模块能够快速地检测到失败(failure),并在检测到失败(failure)后,立刻停止服务。我们称其为失败即停(failfast),失败即停是非常重要的,它可以大大加快上层模块检测到错误的时间,避免单一错误(error)变成级联错误。
如上面的讨论,系统可用性的定义是MTTF/(MTTF + MTTR),一个大于等于0,小于等于1的数值。且该数值越大,系统可用性越高。业界最常用的方法是用9的个数来描述系统可用性,比如3个9的可用性,指系统在99.9%的时间里可用,而5个9的可用性意味着系统在99.999%的时间里都是可用的。
下表展示了基于9的个数描述系统可用性而计算得出的,不同可用性的情况下,系统每年允许的服务不可用时间。
| 可用性 | 年服务不可用时间 |
|---|---|
| 99%(2个9) | 3.65天 |
| 99.9%(3个9) | 8.76小时 |
| 99.99%(4个9) | 52.56分钟 |
| 99.999%(5个9) | 5.26分钟 |
| 99.9999%(6个9) | 31.54秒 |
这也就是说,如果一个服务提供方在SLA里承诺了3个9的服务可用性,那么一个自然年里,总的服务中断时间,不能超过8.76小时。
多数固定电话交换机的设计目标是达到5个9的可用性,即每年不超过5.26分钟的服务中断。在业界,除了某些需要更高可用性的场景,5个9的可用性被认为是数据服务的黄金标准。即对数据服务而言,满足了5个9的可用性,即可称之为做到了高可用。
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5551888.html