标签:style blog http color 使用 strong 数据 for
CUDA C编程入门-介绍
1.1.从图形处理到通用并行计算
在实时、高清3D图形的巨大市场需求的驱动下,可编程的图形处理单元或者GPU发展成拥有巨大计算能力的和非常高的内存带宽的高度并行的、多线程的、多核处理器。如图1和图2所示。
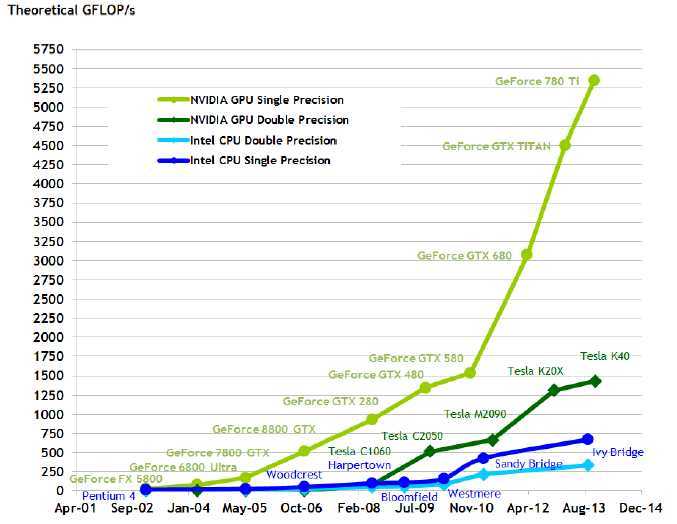
图 1 CPU和GPU每秒的浮点计算次数
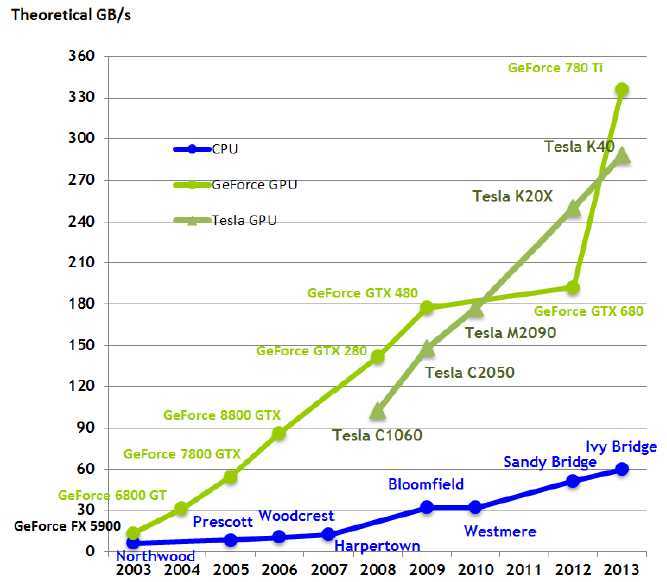
图 2 CPU和GPU的内存带宽
在CPU和GPU之间在浮点计算能力上的差异的原因是GPU专做密集型计算和高度并行计算-恰好是图形渲染做的-因此设计成这样,更多的晶体管用于数据处理而不是数据缓存和流控制,如图3所示。
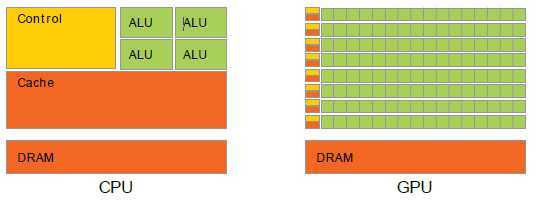
图 3 GPU将更多的晶体管用于数据处理
更具体的说,GPU特别适合处理能表示为数据并行计算的问题-相同程序并行地在许多元素上执行-更高的计算强度-计算操作的比例相对于内存操作来说的。因为相同的程序在每个数据元素上执行,所以对于复杂的流控制只有比较低要求。因为在每个数据元素上执行和有高的计算强度,计算中的内存访问延迟被隐藏,从而替换大的数据缓存。
数据并行处理映射数据元素到并行处理的线程(Thread)。许多处理大数据集的应用程序使用数据并行编程模型加速计算过程。在3D渲染,大型集合的像素和顶点映射到并行的线程中处理。同样地,图像和媒体处理应用程序,比如已渲染的图像的后处理、视频编码和解码、图像缩放、立体视觉和模式识别能映射图像的区域和像素点到并行的线程中计算。事实上,许多图像渲染和处理以外的领域能通过数据并行处理来加速,从一般的信号处理、物理仿真到计算金融学和计算生物学。
1.2.CUDA:一个通用的并行计算平台和编程模型
在2006年11月,NVIDIA介绍CUDA,一个通用的并行计算平台和编程模型,利用在NVIDIA的GPUs的并行计算引擎,比CPU更有效的解决许多复杂的计算问题。CUDA自带的软件环境允许开发者使用C作为高级的编程语言。如图4所示,其它语言、应用程序接口、基于指令的方法的支持,比如FORTRAN、DirectCompute、OpenACC。

图 4 GPU计算程序,CUDA设计成支持多种语言和应用程序接口
1.3.一个可伸缩的编程模型
多核CPU和GPU的出现意味着主流的处理芯片现在是并行的系统。此外,其并行性继续按摩尔法则增加。开发应用软件的挑战是显式地缩放并行性去利用增加的处理器核心的数目。和3D图形应用显式地缩放其并行性到带有不同数目的多核心的GPUs一样。
CUDA并行编程模型被设计去克服这样的挑战,并且对熟悉标准编程语言,比如C,保持较低的学习曲线。
核心有3个关键的抽象:线程组的层次、共享内存和屏蔽同步-只是暴露给程序员一个最小的语言扩展集。
这些抽象提供细粒度的数据并行和线程并行,嵌入进粗细度的数据并行和任务并行。指导程序员把问题划分成粗的能被独立地并行地在多块线程中处理的子问题,每个子问题被并行地在每一块的线程处理。(也就是说每个问题被划分成许多子问题,每个子问题在单独的一块线程中处理,子问题和子问题的处理是并行的,而每个子问题又是在一块线程中处理,这个处理也是并行的。)
分解保持语言表达性,允许线程合作地解决每个子问题。同一时刻支持自动地可收缩。甚至,每块线程能被安排在GPU中的任何的空闲的多处理器,以任意的次序,同时地或者连续地,所以编译的CUDA程序能够执行在任何数量的多核心上,如图5。只有运行时系统需要知道物理的多处理器的个数。
这可伸缩编程模型通过简单地伸缩多处理器的数目和内存划分而允许CPU结构跨越广阔的市场范围:从高性能爱好者-GeForce GPUs、专业的Quadro和Tesla计算产品到各种便宜的、主流的GeForce GPUs(查看支持CUDA的GPU章节)。
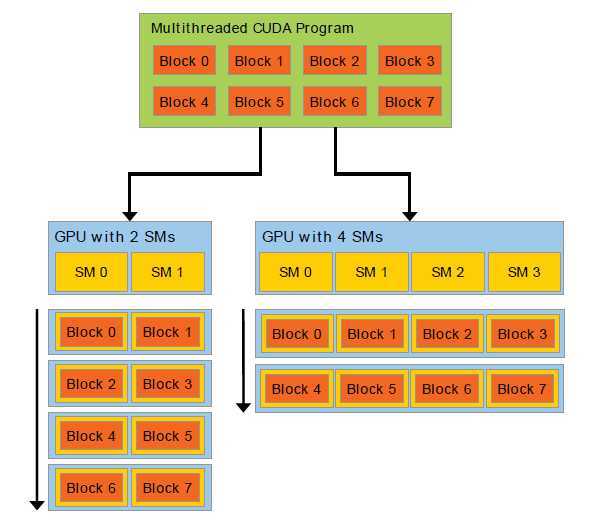
图 5 自动可扩展。一个GPU由一个流处理器(SM)阵列组成(更多细节可查考硬件实现这一章节)。每个多线程程序被划分到各个线程块独立地执行,所以拥有更多处理核心的自动地比更少的处理核心执行所花费的时间更少。
1.4.文档结构
文档组织成下面的章节:
标签:style blog http color 使用 strong 数据 for
原文地址:http://www.cnblogs.com/zjwzcnjsy/p/3887560.html