标签:
1、朴素贝叶斯方法,首先要明确是用于分类任务。
在机器学习中,但凡遇到分类问题,所有的方法都关注两部分,即:待分类输入向量的特征和训练向量集中的每个类别的特征。
变量不过就是,特征数的多少,类别的多少,训练样本的多少。
朴素贝叶斯方法在处理这个问题时,采用的思路是概率化的,即每一个输入向量既可能属于类别1,也可能属于类别2,持开放性态度,但是必须选择的话,选择概率更大的那个类别。
拿文本分类来说,这个问题中的特征,就是所有词语,不重复的所有词语。样本呢,就是所有文档,类别呢,可以是垃圾邮件、正常邮件,也可以是任何的人为可分的类别。
所以自然而然的,我们脑海中应该形成一个类似于dataframe的表,其实也就是文档-词矩阵,每一行可以代表每一分文档,每一列都是不重复的词语。每个位置上的值可以表示该词在该文档中出现几次。这样就形成了一个训练集。
现在朴素贝叶斯方法要求的就是,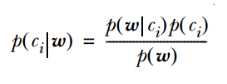 这个著名公式中的等号左边部分。
这个著名公式中的等号左边部分。
而等号左边部分的意义,实质上就是,我拿到了一篇文档,里面出现了这么多词,在这个条件下,我这篇文档归为类别1的概率是多少?归为类别2的概率是多少?
然后求解方式就很直观了,分母部分的p(w)是可以不求的,只需要求出分子的乘积。p(ci)也是相对容易的,只需要统计出所有训练集中每个类别的出现概率就好。难点在于p(w|ci),其中w是一个向量。这里需要用到朴素贝叶斯方法的第一个重要假设,就是各个特征之间相互独立。这样就可以把这项展开成一个连乘的形式,只需要统计每个词在该类别中出现的概率,然后连乘就得到结果。
另外一个小问题是具体计算过程中有可能会由于某项概率过小,四舍五入为0导致连乘积为0,因此需要laplace smoothing,默认每个词初始的出现次数都为1,求去条件概率的分母初始值为2。这叫做条件概率的贝叶斯估计。
还有一个问题也出现在计算机实际程序当中,叫做下溢出。出现原因也是因为连乘的每个概率值过于小的原因,这时候可以用取对数的办法,因为我们最终比较的是属于两个类别概率值的大小,依据对数函数的单调性性质,依然可以保证结果的准确性。
在实际程序逻辑中要注意,需要先对训练集中所有词汇的类别概率求取出来,得到两个类别概率向量以及一个先验概率,再将测试集中出现的词汇构造词集向量,直接进行向量相乘即可。
2、knn(最近邻方法)
knn应用类型也是分类问题。不过它的决策规则并不是朴素贝叶斯中的概率思路,而是最常规的投票模式(即少数服从多数)。
knn方法中的核心部分是如何判断和测试向量最近邻的训练向量们。最常见的是欧式距离,其余的像曼哈顿距离,Minkowski距离也可以使用。从这里就可以看出在进行knn方法的时候,需要将训练集的特征表达全部换成数字的形式。
其余的就很好理解了,通过sort,选出最近邻的k个训练向量,然后进行投票,选出类别占比最多的那个类别作测试向量的类别。
有两个问题,一是k的选择,既不能过大,又不能过小。过小容易把噪声点误判为正常点,俗称过拟合;过大意味着整体模型变的简单,学习的近似误差会增大。极端情况是k=N,那么无论输入实例是什么,都将简单地预测为训练集中占比最多的类别。k一般适宜取一个较小的数值。
二是knn的计算量问题。knn的一个缺点就是计算量太大,为了提高计算效率,引入了一种新的数据结构,叫做kd树。kd-tree的平均搜索复杂度可以达到O(log(N)),当训练实例数远远大于空间维数时,效率很高。关于如何搜索,可以查看李航《统计学习方法》p44。
标签:
原文地址:http://www.cnblogs.com/lvlvlvlvlv/p/5559451.html