标签:
第3章 分类:垃圾过滤
#machine learing for heckers
#chapter 3
library(tm) library(ggplot2)
#设置路径变量
spam.path <- "ML_for_Hackers/03-Classification/data/spam/" spam2.path <- "ML_for_Hackers/03-Classification/data/spam_2/" easyham.path <- "ML_for_Hackers/03-Classification/data/easy_ham/" easyham2.path <- "ML_for_Hackers/03-Classification/data/easy_ham_2/" hardham.path <- "ML_for_Hackers/03-Classification/data/hard_ham/" hardham2.path <- "ML_for_Hackers/03-Classification/data/hard_ham_2/"
###########################################
#构建垃圾邮件和正常邮件的特征词项类别知识库
###########################################
#######################
#构建垃圾邮件的特征词项
#######################
#打开每一个文件,找到空行,将空行之后的文本返回为一个字符串向量(只有一个元素)
#file用于打开文件,open设置rt(read as text), 由于邮件中可能包含非ACSⅡ码字符,
#设置encoding = "latin1"
#readLines按行读入文件
#定位到第一个空行“”并抽取后面的所有文本
#有些文件中未包含空行,会抛出错误,因此用tryCatch捕获这些错误并返回NA
#关闭文件,将所有行合并为一行并返回该向量
get.msg <- function(path){
con <- file(path, open = "rt", encoding = "latin1")
text <- readLines(con)
#The message always begins after the first full line break
#if not have a break, return NA
msg <- tryCatch(text[seq(which(text == "")[1]+1, length(text), 1)], error = function(e) return(NA))
close(con)
return(paste(msg, collapse = "\n"))
}
#创建向量保存所有正文,向量的每个元素就是一封邮件的内容
#dir函数得到路径下文件列表,除掉cmds文件
#应用sapply函数时,先传入一个无名函数,目的是用paste函数把文件名和适当的路径拼接起来
spam.docs <- dir(spam.path)
spam.docs <- spam.docs[which(spam.docs != "cmds")]
all.spam <- sapply(spam.docs,
function(p) get.msg(paste(spam.path, p, sep = "")))
#输入文本向量,输出TDM(Term Document Matrix,词项-文档矩阵)
#矩阵行表示词项,列表示文档,元素[i, j]代表词项i在文档j中出现的次数
#Corpus函数用于构建语料库(corpus对象),VectorSource用向量构建source对象
#source对象是用来创建语料库的数据源对象
#control变量是一个选项列表,用于设定提取文本的清洗规则
#stopwords移除停用词,removePunctuation, removeNumbers分别移除标点和数字
#minDocFreq设定最小两次出现的词才最终出现在TDM中
get.tdm <- function(doc.vec){
doc.corpus <- Corpus(VectorSource(doc.vec))
control <- list(stopwords = TRUE, removePunctuation = TRUE,
removeNumbers = TRUE, minDocFreq = 2)
doc.dtm <- TermDocumentMatrix(doc.corpus, control)
return(doc.dtm)
}
spam.tdm <- get.tdm(all.spam)
#用TDM构建垃圾邮件的训练数据:构建数据框保存所有特征词在垃圾邮件中的条件概率
#先将spam.tdm转为标准矩阵,rowSums创建一个包含每个特征在所有文档中总频次的向量
#注意禁止字符自动转为因子
#修改列名,frequency转数字类型
spam.matrix <- as.matrix(spam.tdm)
spam.counts <- rowSums(spam.matrix)
spam.df <- data.frame(cbind(names(spam.counts), as.numeric(spam.counts)),
stringsAsFactors = FALSE)
names(spam.df) <- c("term", "frequency")
spam.df$frequency <- as.numeric(spam.df$frequency)
#关键训练数据1:计算一个特定特征词项所出现的文档在所有文档中所占比例
#sapply函数将行号传入无名函数,计算该行值为正数的元素个数,再除以文档总数(列数)
#关键训练数据2:统计整个语料库中每个词项的频次(不用于分类,但是可以通过对比频次知道某些词是否影响结果)
spam.occurrence <- sapply(1:nrow(spam.matrix),
function(i) {length(which(spam.matrix[i, ] > 0))/ncol(spam.matrix)})
spam.density <- spam.df$frequency/sum(spam.df$frequency)
spam.df <- transform(spam.df, density = spam.density, occurrence = spam.occurrence)
#按照occurrence列降序排列并显示前6条(与书上的结果不同)
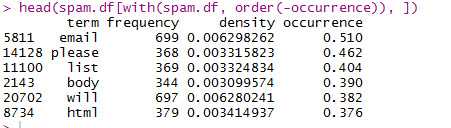
#######################
#构建正常邮件的特征词项
#######################
easyham.docs <- dir(easyham.path)
easyham.docs <- easyham.docs[which(easyham.docs != "cmds")]
#注意为了平衡数据,将正常邮件数量限定在500
easyham.docs<-easyham.docs[1:500]
all.easyham <- sapply(easyham.docs,
function(p) get.msg(paste(easyham.path, p, sep = "")))
easyham.tdm <- get.tdm(all.easyham)
easyham.matrix <- as.matrix(easyham.tdm)
easyham.counts <- rowSums(easyham.matrix)
easyham.df <- data.frame(cbind(names(easyham.counts), as.numeric(easyham.counts)),
stringsAsFactors = FALSE)
names(easyham.df) <- c("term", "frequency")
easyham.df$frequency <- as.numeric(easyham.df$frequency)
easyham.occurrence <- sapply(1:nrow(easyham.matrix),
function(i) {length(which(easyham.matrix[i, ] > 0))/ncol(easyham.matrix)})
easyham.density <- easyham.df$frequency/sum(easyham.df$frequency)
easyham.df <- transform(easyham.df, density = easyham.density, occurrence = easyham.occurrence)
#按照occurrence列降序排列并显示前6条(与书上的结果不同)
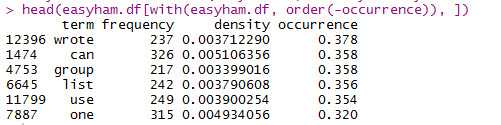
#########################################################################
#构造函数classify.email:输入文本返回这封邮件是垃圾邮件的贝叶斯概率估计值
#########################################################################
#抽取正文、转换成TDM、计算特征词项频率
#先验概率默认为50%,未出现词的概率设为0.0001%
classify.email <- function(path, training.df, prior = 0.5, c = 1e-6){
msg <- get.msg(path)
msg.tdm <- get.tdm(msg)
msg.freq <- rowSums(as.matrix(msg.tdm))
#find intersections of words找到邮件中的词项和出现在训练集中的词项的交集
msg.match <- intersect(names(msg.freq), training.df$term)
if(length(msg.match) < 1){
#如果没有任何词出现在垃圾邮件集中
#length(msg.freq)是词的个数
#返回的值很小,因为没有训练集中出现过的词,无法判定
return(prior*c^(length(msg.freq)))
}else{
#交集中词的频率存放到match.probs
#用这些词的特征概率,计算这封邮件是训练集中对应类别的条件概率
#返回值=是垃圾邮件的先验概率*各重合词在垃圾邮件训练集中的概率积*缺失词项的小概率积
match.probs <- training.df$occurrence[match(msg.match, training.df$term)]
return(prior*prod(match.probs)*c^(length(msg.freq) - length(msg.match)))
}
}
#############################################
#用不易分类的正常邮件进行测试
#############################################
hardham.docs <- dir(hardham.path)
hardham.docs <- hardham.docs[which(hardham.docs != "cmds")]
hardham.spamtest <- sapply(hardham.docs,
function(p) classify.email(file.path(hardham.path, p),
training.df = spam.df))
hardham.hamtest <- sapply(hardham.docs,
function(p) classify.email(file.path(hardham.path, p),
training.df = easyham.df))
hardham.res <- ifelse(hardham.spamtest > hardham.hamtest, TRUE, FALSE)
summary(hardham.res)

#############################################
#用三种类型的邮件下标为2的邮件集进行测试
#############################################
#creating a function: return the probability and the classification
spam.classifier <- function(path) {
pr.spam <- classify.email(path, spam.df)
pr.ham <- classify.email(path, easyham.df)
return(c(pr.spam, pr.ham, ifelse(pr.spam > pr.ham, 1, 0)))
}
#path list
spam2.docs <- dir(spam2.path)
spam2.docs <- spam2.docs[which(spam2.docs != "cmds")]
easyham2.docs <- dir(easyham2.path)
easyham2.docs <- easyham2.docs[which(easyham2.docs != "cmds")]
hardham2.docs <- dir(hardham2.path)
hardham2.docs <- hardham2.docs[which(hardham2.docs != "cmds")]
#classifying using lapply
spam2.class <- suppressWarnings(lapply(spam2.docs,
function(p) spam.classifier(file.path(spam2.path, p))))
easyham2.class <- suppressWarnings(lapply(easyham2.docs,
function(p) spam.classifier(file.path(easyham2.path, p))))
hardham2.class <- suppressWarnings(lapply(hardham2.docs,
function(p) spam.classifier(file.path(hardham2.path, p))))
#"lapply"返回的是列表对象,需要转换为矩阵
#turn the list into matrix and label them easyham2.matrix <- do.call(rbind, easyham2.class) easyham2.final <- cbind(easyham2.matrix, "EASYHAM") hardham2.matrix <- do.call(rbind, hardham2.class) hardham2.final <- cbind(hardham2.matrix, "HARDHAM") spam2.matrix <- do.call(rbind, spam2.class) spam2.final <- cbind(spam2.matrix, "SPAM")
#combine all matrices and turn them into data frame, name the column
class.matrix <- rbind(easyham2.final, hardham2.final, spam2.final)
class.df <- data.frame(class.matrix, stringsAsFactors = FALSE)
names(class.df) <- c("Pr.SPAM" ,"Pr.HAM", "Class", "Type")
#设置stringAsFactors = FALSE后,数据框所有元素类型均为"character",因此需要单独更改
class.df$Pr.SPAM <- as.numeric(class.df$Pr.SPAM) class.df$Pr.HAM <- as.numeric(class.df$Pr.HAM) class.df$Class <- as.logical(as.numeric(class.df$Class)) class.df$Type <- as.factor(class.df$Type)
#creat a plot of results
#直线的绘制,需要使用"geom_abline"命令,设定截距使用"intercept"参数,与书中代码不同
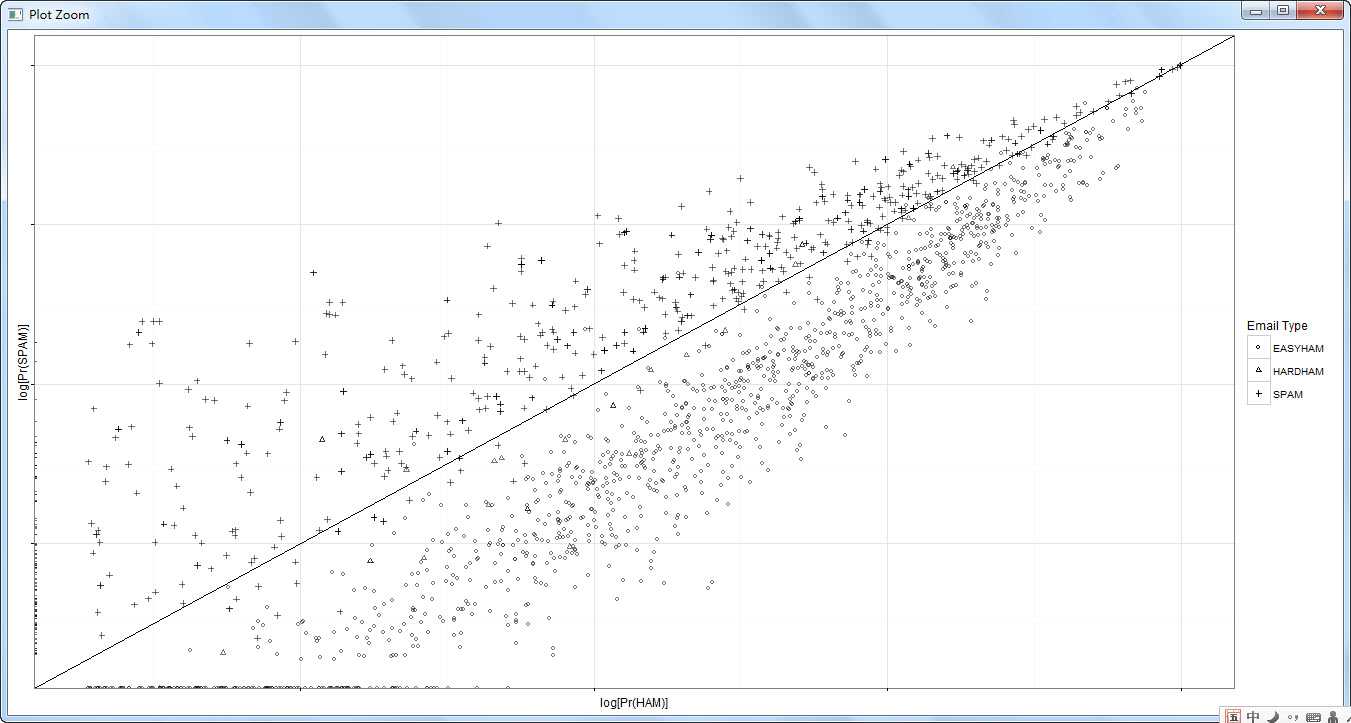
class.plot <- ggplot(class.df, aes(x = log(Pr.HAM), log(Pr.SPAM))) +
geom_point(aes(shape = Type, alpha = 0.5)) +
geom_abline(intercept = 0, slope = 1) +
scale_shape_manual(values = c("EASYHAM" = 1,
"HARDHAM" = 2,
"SPAM" = 3),
name = "Email Type") +
scale_alpha(guide = "none") +
xlab("log[Pr(HAM)]") +
ylab("log[Pr(SPAM)]") +
theme_bw() +
theme(axis.text.x = element_blank(), axis.text.y = element_blank())
print(class.plot)
#creat a table of results
get.results <- function(bool.vector){
results <- c(length(bool.vector[which(bool.vector == FALSE)]) / length(bool.vector),
length(bool.vector[which(bool.vector == TRUE)]) / length(bool.vector))
return(results)
}
easyham2.col <- get.results(subset(class.df, Type == "EASYHAM")$Class)
hardham2.col <- get.results(subset(class.df, Type == "HARDHAM")$Class)
spam2.col <- get.results(subset(class.df, Type == "SPAM")$Class)
class.res <- rbind(easyham2.col, hardham2.col, spam2.col)
colnames(class.res) <- c("NOT SPAM", "SPAM")
print(class.res)
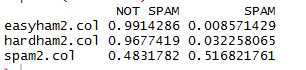
#效果评价:对于正常邮件分类效果好,但是对于垃圾邮件分类效果差,有48.3%的误判
#结果与书上不一致
########################################
#效果改进
########################################
#之前的先验概率设置为50%,但是实际数据集中,垃圾邮件数量347/(347+247+1400)=17.4%
#事实上,垃圾邮件和正常邮件分别约占20%和80%
#因此更改先验概率
#以下是关键代码,重复上面代码的一部分即可得到结果
spam.classifier.new <- function(path){
pr.spam <- classify.email(path, spam.df, prior = 0.2)
pr.ham <- classify.email(path, easyham.df, prior = 0.8)
return(c(pr.spam, pr.ham, ifelse(pr.spam > pr.ham, 1, 0)))
}
spam2.class <- suppressWarnings(lapply(spam2.docs,
function(p) spam.classifier.new(file.path(spam2.path, p))))
easyham2.class <- suppressWarnings(lapply(easyham2.docs,
function(p) spam.classifier.new(file.path(easyham2.path, p))))
hardham2.class <- suppressWarnings(lapply(hardham2.docs,
function(p) spam.classifier.new(file.path(hardham2.path, p))))
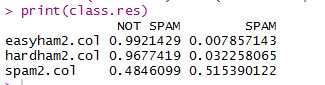
#这一段的效果改进是针对书上的结果来的,书上的结果问题在于对正常邮件的误判很高
#但是之前的结果,对于正常邮件的分类效果很好,而对垃圾邮件的分类效果很差,
#因此这种改进方式并不能解决问题
#然而实际应用中,这种效果的分类器反而比书上的更为好用
PS:
1.这一章的代码里让我感兴趣和不太理解的地方还有tryCatch()和suppressWarnings()的用法,涉及到的应该是处理报错和忽略warnings()的用法。由于现在有关R编程的书不在手边,在网上的其他博客中都是单独用一篇博客来讨论的,我没有仔细看。所以还是一边学习一边填坑吧。
2.对于apply函数族的理解不够深入。想起毕设的时候不会用apply,用了四层循环嵌套,今天想了想并没有想出怎样用apply写,等熟悉一下再试试。
参考博客:
http://www.cnblogs.com/MarsMercury/p/4899669.html
http://www.cnblogs.com/weibaar/p/4382397.html
标签:
原文地址:http://www.cnblogs.com/gyjerry/p/5562478.html