标签:style blog http 使用 os strong io 文件
Bloom Filter(BF)是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。它是一个判断元素是否存在于集合的快速的概率算法。Bloom Filter有可能会出现错误判断,但不会漏掉判断。也就是Bloom Filter判断元素不再集合,那肯定不在。如果判断元素存在集合中,有一定的概率判断错误。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter比其他常见的算法(如hash,折半查找)极大节省了空间。
它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
Bloom-Filter算法的核心思想就是利用多个不同的Hash函数来解决“冲突”。
计 算某元素x是否在一个集合中,首先能想到的方法就是将所有的已知元素保存起来构成一个集合R,然后用元素x跟这些R中的元素一一比较来判断是否存在于集合 R中;我们可以采用链表等数据结构来实现。但是,随着集合R中元素的增加,其占用的内存将越来越大。试想,如果有几千万个不同网页需要下载,所需的内存将 足以占用掉整个进程的内存地址空间。即使用MD5,UUID这些方法将URL转成固定的短小的字符串,内存占用也是相当巨大的。
于是,我们会想到用Hash table的数据结构,运用一个足够好的Hash函数将一个URL映射到二进制位数组(位图数组)中的某一位。如果该位已经被置为1,那么表示该URL已经存在。
Hash存在一个冲突(碰撞)的问题,用同一个Hash得到的两个URL的值有可能相同。为了减少冲突,我们可以多引入几个Hash,如果通过其中的一个 Hash值我们得出某元素不在集合中,那么该元素肯定不在集合中。只有在所有的Hash函数告诉我们该元素在集合中时,才能确定该元素存在于集合中。这便 是Bloom-Filter的基本思想。
原理要点:一是位数组, 二是k个独立hash函数。
1)位数组:
假设Bloom Filter使用一个m比特的数组来保存信息,初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0,即BF整个数组的元素都设置为0。

2)添加元素,k个独立hash函数
为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。
当我们往Bloom Filter中增加任意一个元素x时候,我们使用k个哈希函数得到k个哈希值,然后将数组中对应的比特位设置为1。即第i个哈希函数映射的位置hashi(x)就会被置为1(1≤i≤k)。
注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位,即第二个“1“处)。
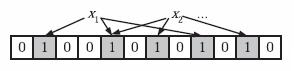
3)判断元素是否存在集合
在判断y是否属于这个集合时,我们只需要对y使用k个哈希函数得到k个哈希值,如果所有hashi(y)的位置都是1(1≤i≤k),即k个位置都被设置为1了,那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素(因为y1有一处指向了“0”位)。y2或者属于这个集合,或者刚好是一个false positive。
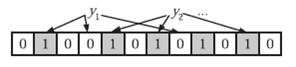
显然这 个判断并不保证查找的结果是100%正确的。
Bloom Filter的缺点:
1)Bloom Filter无法从Bloom Filter集合中删除一个元素。因为该元素对应的位会牵动到其他的元素。所以一个简单的改进就是 counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。 此外,Bloom Filter的hash函数选择会影响算法的效果。
2)还有一个比较重要的问题,如何根据输入元素个数n,确定位数组m的大小及hash函数个数,即hash函数选择会影响算法的效果。当hash函数个数k=(ln2)*(m/n)时错误率最小。在错误率不大于E的情况 下,m至少要等于n*lg(1/E) 才能表示任意n个元素的集合。但m还应该更大些,因为还要保证bit数组里至少一半为0,则m应 该>=nlg(1/E)*lge ,大概就是nlg(1/E)1.44倍(lg表示以2为底的对数)。
举个例子我们假设错误率为0.01,则此时m应大概是n的13倍。这样k大概是8个。
注意:
这里m与n的单位不同,m是bit为单位,而n则是以元素个数为单位(准确的说是不同元素的个数)。通常单个元素的长度都是有很多bit的。所以使用bloom filter内存上通常都是节省的。
一般BF可以与一些key-value的数据库一起使用,来加快查询。由于BF所用的空间非常小,所有BF可以常驻内存。这样子的话,对于大部分不存在 的元素,我们只需要访问内存中的BF就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。
一个Bloom Filter有以下参数:
| m | bit数组的宽度(bit数) |
| n | 加入其中的key的数量 |
| k | 使用的hash函数的个数 |
| f | False Positive的比率 |
BloomFilter有个缺点,就是不支持删除操作,因为它不知道某一个位从属于哪些向量。那我们可以给Bloom Filter加上计数器,添加时增加计数器,删除时减少计数器。
但这样的Filter需要考虑附加的计数器大小,假如同个元素多次插入的话,计数器位数较少的情况下,就会出现溢出问题。如果对计数器设置上限值的话,会导致Cache Miss,但对某些应用来说,这并不是什么问题,如Web Sharing。
为了能在服务器之间更快地通过网络传输Bloom Filter,我们有方法能在已完成Bloom Filter之后,得到一些实际参数的情况下进行压缩。
将元素全部添加入Bloom Filter后,我们能得到真实的空间使用率,用这个值代入公式计算出一个比m小的值,重新构造Bloom Filter,对原先的哈希值进行求余处理,在误判率不变的情况下,使得其内存大小更合适。
Bloom-Filter一 般用于在大数据量的集合中判定某元素是否存在。例如邮件服务器中的垃圾邮件过滤器。在搜索引擎领域,Bloom-Filter最常用于网络蜘蛛 (Spider)的URL过滤,网络蜘蛛通常有一个URL列表,保存着将要下载和已经下载的网页的URL,网络蜘蛛下载了一个网页,从网页中提取到新的 URL后,需要判断该URL是否已经存在于列表中。此时,Bloom-Filter算法是最好的选择。
1.key-value 加快查询
一般Bloom-Filter可以与一些key-value的数据库一起使用,来加快查询。
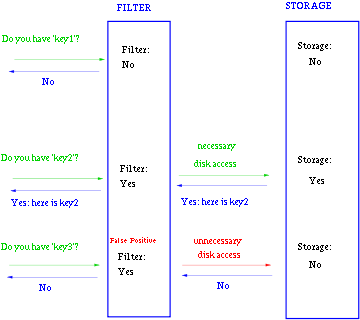
一般key-value存储系统的values存在硬盘,查询就是件费时的事。将Storage的数据都插入Filter,在Filter中查询都不存在时,那就不需要去Storage查询了。当False Position出现时,只是会导致一次多余的Storage查询。
由于Bloom-Filter所用的空间非常小,所有BF可以常驻内存。这样子的话,对于大部分不存在的元素,我们只需要访问内存中的Bloom-Filter就可以判断出来了,只有一小部分,我们需要访问在硬盘上的key-value数据库。从而大大地提高了效率。如图:
2 .Google的BigTable
Google的BigTable也使用了Bloom Filter,以减少不存在的行或列在磁盘上的查询,大大提高了数据库的查询操作的性能。
3. Proxy-Cache
在Internet Cache Protocol中的Proxy-Cache很多都是使用Bloom Filter存储URLs,除了高效的查询外,还能很方便得传输交换Cache信息。
1)P2P网络中查找资源操作,可以对每条网络通路保存Bloom Filter,当命中时,则选择该通路访问。
2)广播消息时,可以检测某个IP是否已发包。
3)检测广播消息包的环路,将Bloom Filter保存在包里,每个节点将自己添加入Bloom Filter。
4)信息队列管理,使用Counter Bloom Filter管理信息流量。
像网易,QQ这样的公众电子邮件(email)提供商,总是需要过滤来自发送垃圾邮件的人(spamer)的垃圾邮件。
一个办法就是记录下那些发垃圾邮件的 email地址。由于那些发送者不停地在注册新的地址,全世界少说也有几十亿个发垃圾邮件的地址,将他们都存起来则需要大量的网络服务器。
如果用哈希表,每存储一亿个 email地址,就需要 1.6GB的内存(用哈希表实现的具体办法是将每一个 email地址对应成一个八字节的信息指纹,然后将这些信息指纹存入哈希表,由于哈希表的存储效率一般只有 50%,因此一个 email地址需要占用十六个字节。一亿个地址大约要 1.6GB,即十六亿字节的内存)。因此存贮几十亿个邮件地址可能需要上百 GB的内存。
而Bloom Filter只需要哈希表 1/8到 1/4 的大小就能解决同样的问题。
BloomFilter决不会漏掉任何一个在黑名单中的可疑地址。而至于误判问题,常见的补救办法是在建立一个小的白名单,存储那些可能别误判的邮件地址。
问题实例】 给你A,B两个文件,各存放50亿条URL,每条URL占用64字节,内存限制是4G,让你找出A,B文件共同的URL。如果是三个乃至n个文件呢?
根据这个问 题我们来计算下内存的占用,4G=2^32大概是40亿*8大概是340亿bit,n=50亿,如果按出错率0.01算需要的大概是650亿个bit。 现在可用的是340亿,相差并不多,这样可能会使出错率上升些。另外如果这些urlip是一一对应的,就可以转换成ip,则大大简单了。
转自:
http://blog.csdn.net/hguisu/article/details/7866173
【转】海量数据处理算法-Bloom Filter,布布扣,bubuko.com
标签:style blog http 使用 os strong io 文件
原文地址:http://www.cnblogs.com/ljygoodgoodstudydaydayup/p/3888324.html