标签:
本期内容 :
Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢?
例如:join操作和普通Map操作的处理数据的时间消耗是否会呈现出一致的线性规律呢,也就是说,并非数据量规模越大就是简单加大BatchDuration
就可以解决问题的,数据量是一个方面,计算的算子也是一个考量的因素。
使用BatchSize来适配我们的流处理程序 :
线上的处理程序越来越重要,流入的数据规模越来越大的时候,传统的一台机器不能够容纳此刻流入的数据并处理此刻流入的数据,所以需要分
布式。分布式的流处理程序其根源在于此1秒中流入的数据我们一台机器无法容纳且无法完成及时的处理,也就是大数据,更谈不上实时性处理和在
线处理 。数据处理的过程中最重要问题是在不同的算子和工作负载对我们处理时间的影响以及这种影响是否是我们预期中的结果。
目前有很多的计算框架,这些所有的计算框架有一个共同特征,就是在连续不断的流进来的一系列数据中使用MapReduce的思想去处理接收到的
数据, MapReduce是一种思想,无论是Hadoop还是Spark都是MapReduce的思想实现,MapReduce的实现有一个很好的方面就是容错性,他有自
己的一套完整的容错机制。流处理程序在具体处理线上数据的时候,借助MapReduce容错机制能够快速从错误中恢复的能力。
构建一套稳定的处理程序,有很多维度需要去考虑,如实时性、波峰,如每秒处理1G的数据,突然一个波峰需要处理100T的数据,此时将如何处
理,整个流处理应该怎样去应对这种情况?
以往的流处理系统中,一种是流处理框架可以动态调整资源,如内存、CPU等资源。另外一种是在来不及处理时使用丢弃部分数据。那如何在保证
数据的完整性的情况下,且数据一定会处理。如何应对现实突发的情况,如果直接调整内存、CPU等资源其代价非常大而且也不太好调整。
Spark Streaming的处理模型是以Batch为模型然后不断的在Queue中把每个BatchDuration的数据进行排队:
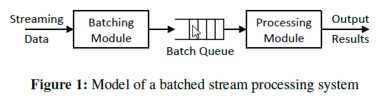
Spark Streaming的数据一批批的放在队列中,然后一个个的在集群中处理的,无论是数据本身还是元数据,Job都是以队列的方式获取信息来控制整
个作业的运行。随着数据规模变的越来越大的时候,并不是简简单单的增加内存、CPU等硬件资源就可以的,因为很多时候并不是线性规律的变化。
什么因素导致了Batch处理数据的延时:
01、 接收数据并且把接收到的数据放到Batch待处理的队列中(也就是BatchSize会极大的影响其延时性)
02、 等待时间
03、 处理时间
静态处理模型 :
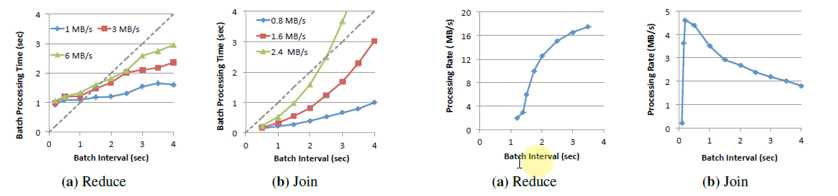
图中的虚线就是安全区域,安全区域就是数据流进来的速度能够及时在这个BatchDuration中被消化。对Reduce与Join的操作进行对比,不同的算子存在不同的
线性规律,不是随着数据量的增加呈现线性的处理速度,流处理有很多因素影响 .
一般使用几个BatchDuration进行流处理,直接配置一些参数,每隔10S中就有一个BatchDuration然后处理,这样的处理方式是不可取的。从上图可以看出,实
际不是这样的,随着数据量的改变,原来的数据量运行很好,预期也有评估,如每秒处理100M的数据(单节点),使用线性方式评估在500M的时候是怎样的,然后就设
置相对应的静态模型,是基于你现有的硬件资源(内存、CPU、网络),这样评估是不准确的,而且很难预测,因为当消费数据的容量的不同很难去预测其运行行为。
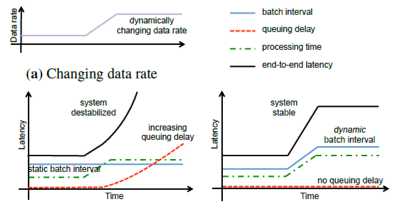
在改变其数据rate时,状态有不稳定性,如果能够改变BatchSize的话其相对稳定,所以需要设计一种算法或者实现,不是去调整内存、CPU等硬件资源,而是调
整其Batch的大小,当Batch足够小或者小得适当的时候,应该是个更好的思路,低延时、灵活性、通用性、简单性。
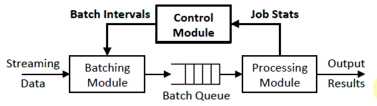
要完成BatchSize的变化的不断的调整肯定需要对Job信息进行统计,动态的调整这个模式,这个模式就是配置相应的参数。随着处理的不断运行,在下一次运行
之前看一下上次统计的信息,是否需要调整我们的模型,但是这样做会比较困难。因为会出现一些非线性的行为,把你认为的线性的资源改变一下就是可以的,处理
规模不一样,处理算子不一样,有很多不可预测的因素,需要实现对BatchSize的动态调整。
备注:
Spark Streaming中动态Batch Size深入及RateController解析
标签:
原文地址:http://www.cnblogs.com/yinpin2011/p/5565381.html