标签:
摘要: 买家的评论文本数据是电子商务领域一种重要的数据形式,通过对其分析,电商卖家可以直接了解顾客对产品的态度与建议,提取顾客关注的热点问题,也可以进行顾客分类,实现精准营销,改进和提高生产和服务等;买家可以提取所关注属性的相关评价,了解舆论情感倾向,提高购物决策效率。但是大数据环境下海量文本的出现给文本数据的有效利用带来了一定的困难,比如结构化处理后的文本数据的高维特性给电子商务文本聚类等分析带来了新的挑战。本文主要研究当词条数目(变量数)远远大于评论文本数(样本数)时如何归纳顾客评论以及提取热点话题。本文抓取了亚马逊中国站热门产品kindle的评论文本,通过惩罚高斯混合模型聚类方法,同时进行文本聚类和有效词条的筛选,实现了大规模评论文本的有效、快速、自动聚类,为后续更加精细的商业分析提供了良好的基础。
关键词:顾客评论;文本分析;聚类;热点话题
电子商务数据分析根据数据类型可以划分为以下几个方面:1)用户行为数据的分析,也可以称为事件分析,包括用户点击、浏览、收藏、购买等行为流程的分析;2)顾客信息分析,包括顾客年龄、性别、地区、交易模式、偏好等数据的分析;3)产品信息分析,包括产品参数、门类等,以实现优化产品结构、库存管理等;4)文本数据分析,包括用户评论文本数据以及外部可搜集的舆论文本等;5)业绩数据分析,例如通过对比营销前后的业绩数据检验营销手段效果等。分析流程包括数据的收集、整理、存储、管理、调用、分析、应用、检验、调整等。具体的研究方向涉及到电子商务网络平台的优化,用户行为分析,海量数据处理,营销因素研究等。以上分析的角度与方法贯穿于整个电子商务运行的生命周期,在信息科技飞速发展、数据急速扩张的时代,及时意识到数据分析的重要性并将其充分运用到商业经营当中,对于电子商务领域有着极其重要的意义。通过一系列的数据分析,电子商务运营方可以达到优化运营、完善产品、精准营销、维护吸引用户、创造良好口碑、知己知彼的健康运作状态。
2016年1月22日,中国互联网络信息中心(CNNIC)发布的第37次《中国互联网络发展状况统计报告》显示,截至2015年12月,我国网络购物用户规模达到4.13亿,较2014年底增加5183万,增长率为14.3%,与此同时,手机网络购物用户规模增长迅速,达到3.40亿,手机网络购物的使用比例由42.4%提升至54.8%,随之而来的是网民在各种网络平台上所发表的购物观点、意见等的激增,这些评论文本包含了消费群体对所购买的商品或者服务的情感态度等信息,反映了用户通过互联网对产品各方面发表的看法,对电子商务平台销售者以及个体消费者都有重要的分析价值。Deloitte Consumer Products Group调查显示,有67%的网民会浏览在线评论,其中82%认为在线评论影响了他们的购买决策,可见,在线评论引发的电子口碑已不容小觑,通过评论分析,商家能够了解市场对产品的看法,发现与竞争对手的差异,为产品改进、价格优化等提供有价值信息。具体来讲,透过商品评论,销售者可以直接了解到当前出售产品的评论热点、提取产品优势和不足、挖掘顾客建议,甚至提前预测顾客需求,达到指导生产服务的目的;另外与商家的促销信息相比,在线评论具有独立性、非商业性,因此深得用户信赖,与此同时,由于缺少线下体验,更多的用户倾向于先看评论,后做决策,通过查看商品评价,消费者可以迅速了解到其他顾客对商品的评价、锁定关注属性的相关评价,支持消费决策。所以说,电子商务评论文本蕴含了顾客产品评分、销售数据等无法涵盖的重要信息,对评论文本的归纳与挖掘可以实现相关信息的提取,进而为产品经营乃至产品购买提供一定的决策支持[1]。
在大数据的时代背景下,电子商务领域也面临着数据急剧扩张的问题,评论文本也是如此,尤其是热门销售产品,其评论文本可以在短时间内达到极高的累计值,此时进行评论文本的人工阅读与分析不仅耗费时间和精力,也无法确保分析的准确性和全局性,所以有必要借助于数据分析手段以及自然语言处理等方法来实现文本的快速、准确分析[2]。聚类分析是一种自动、快速实现评论文本信息挖掘的有效方式。通过对顾客评论文本聚类,可以实现热点话题的自动识别,提取产品的优势与不足,指导生产与营销,并实现顾客的有效划分,为后续更加精准的分析提供良好的分析基础。但是,文本数据经过结构化处理后,往往存在高维特性,即词条数目远远大于评论文本数,需要在聚类前或者聚类过程中进行变量(特征)筛选以改善聚类效果。综合考虑互联网的文本数据文本容量庞大、表述歧义性、类属中介性等特性,以及模型聚类在处理互联网的文本数据时理论和实效方面的优势,本文选取惩罚高斯混合模型对文本数据进行聚类分析,在进行聚类特征筛选的同时改善了聚类效果,实现了电子商务评论文本热点话题的自动、高效聚类。
本文所使用的评论文本数据都通过网络爬虫获取。所谓网络爬虫,是按照一定的规则,自动地抓取网络信息的程序或者脚本,将互联网上的网页下载到本地形成一个互联网内容的镜像备份。传统爬虫按照访问网页地址,即访问统一资源定位器(Uniform Resource Locator,URL),从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。由于本文主要分析对象是电子商务平台顾客产品评论语料,并关注实证层面,所以采用基于产品编码的爬取方式,即选定某种研究产品垂直爬取目标网页的评论文本等数据,采用R语言、Python语言编写网络爬虫或利用其他开源爬虫程序(如Gooseeker)完成数据获取、解析、存储与调用。
我们抓取了亚马逊中国站上热门产品“kindle”电子书阅读器下“kindle”、“kindle paperwhite”、“kindle voyage”三个子类产品的商品评论语料,抓取的期间为2014年10月3日至2015年8月24日,抓取的字段包括:project_id、source_id、conment、meta、pubdate,分别代表产品大类id、产品子类id(共三个子产品,取值为1、3、4,分别对应“kindle paperwhite”、“kindle voyage”和“kindle”)、产品评论、产品评分(5分、4分、3分、2分、1分)和评论日期。在产品5个等级的评分中,5分为最高分,1分为最低分。理论上来讲,1、2分属于用户对产品“差评”;3分表明用户对产品给予“中评”;即用户对产品基本满意,用户的产品评价中等;4、5分为表明用户对产品给予“好评”,即用户的产品评价最高。抓取评论文本总计5477条,其中“kindle”2942条、“kindle paperwhite”902条、“kindle voyage”1633条,各子类产品语料分布情况详见表1.
表1 产品各水平得分评论数汇总表
| 产品 | 评论总数 | 1分 | 2分 | 3分 | 4分 | 5分 |
| Paperwhite
Voyage Kindle |
902
1633 2942 |
42
94 107 |
32
44 84 |
73
147 218 |
153
331 607 |
602
1017 1926 |
在获取的三种产品评论语料中,kindle的语料数超过了50%,而kindle paperwhite评论语料最少,不足20%,详见图1。将各月评论数累积加总,绘制各月累积评论数趋势图2。
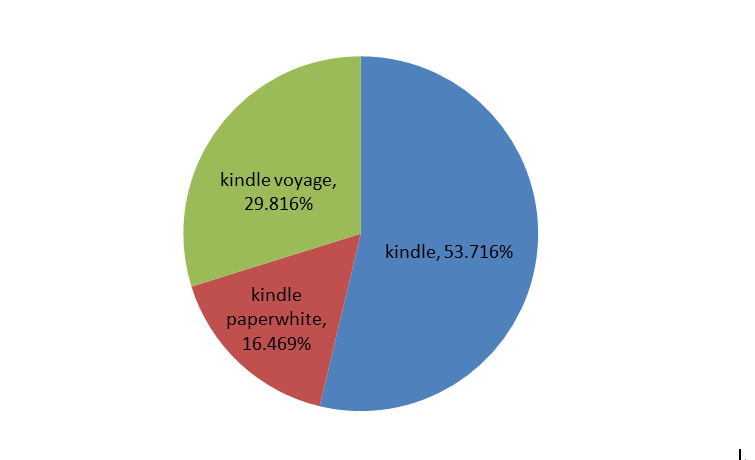
图1 三种产品评论语料占比
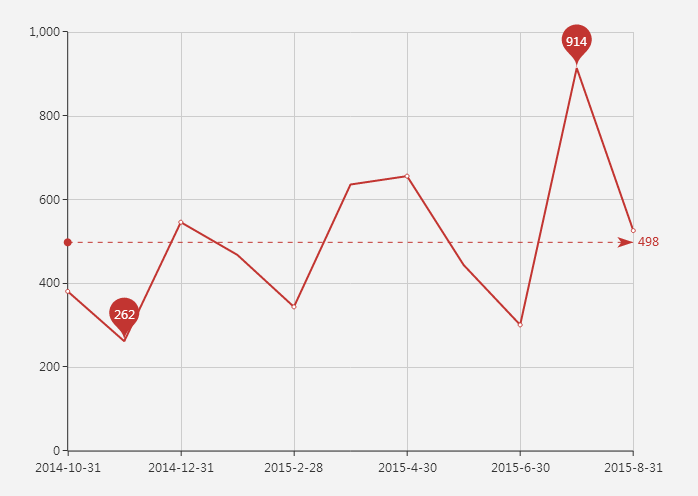
图2 累积评论趋势(注:横坐标,时间/月,纵坐标,评论数/条)
图2上标注了各月累积评论数的最大值、最小值以及均值,累积评论在2015年7月达到了最大值,为914条,在2014年11月达到了最小值,为262条,整个研究区间内月平均评论数为498条,总体来看,各月评论数围绕该均值上下波动,且呈现上升趋势。
利用Python中mmseg算法包对所有产品的评论语料进行分词,绘制词云图,输出词频最高的前60个词汇,可以直观的看出,“kindle”、“电子书”、“亚马逊”是出现次数最多的几个词汇,“分辨率”、“快递”、“背光灯”、“性价比”、“保护套”、“翻页键”等为消费者关注较多的产品属性,但是针对不同关注焦点的具体评论情况还有待于进一步的分析。
从三类产品各自的词云图(图3至6)可以看出,除了“kindle”、“电子书”、“亚马逊”、“分辨率”、“快递”、“性价比”等相同的高频词汇,三个子类产品都出现了词汇“iPad”,可见多数消费者都会讲kindle与iPad进行对比;此外,“退货”问题也是关注的重点。分别来看,三种产品词云的差异之处在于:“Paperwhite”有关于“反应速度”的评论语句;“voyage”有“赠送”、“限量版”、“珍藏版”出现;“kindle”则出现“数据线”、“充电器”、“开机”、“待机时间”等高频词汇。可见,虽然消费者对三种产品都存在共性的关注点,但是针对不同的产品也有不同的侧重点。

图3 全部语料词云图

图4 Paperwhite语料词云
图5 Voyage语料词云
图6 kindle语料词云
此外,在产品大类层次下,5分评论占比最多,达到65%,2分评论最少,仅为3%,整体评论趋于乐观。图8显示产品voyage 1分评价显著高于2分评价,且占比高于另外两种子产品,属于评价分布异常产品,应给予预警。
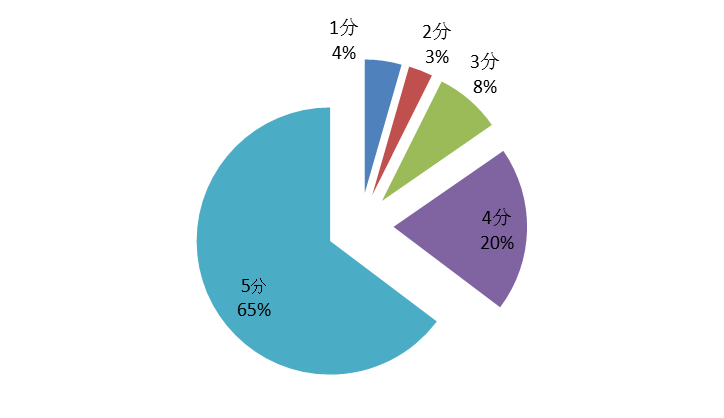
图7 总体评分占比
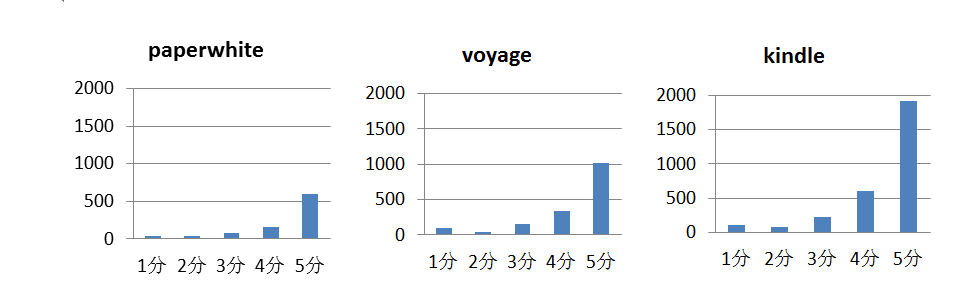
图8 各子产品评分分布
(1)文本结构化处理
文本数据属于非结构化数据,要对其进行聚类分析,需要事先进行结构化处理。本文采用的结构化处理方式是构建空间向量模型,向量的权重采用TF-IDF值,即词频-逆向文件频率(Term Frequency–Inverse Document Frequency,简称TF-IDF)。文本分词处理后,由 个词汇项w1,w2,?,wNw1,w2,?,wN构成的包含M个文本d1,?,dMd1,?,dM
的文本集合 ,的TF-IDF矩阵如表2所示:
表2 文本TF-IDF矩阵
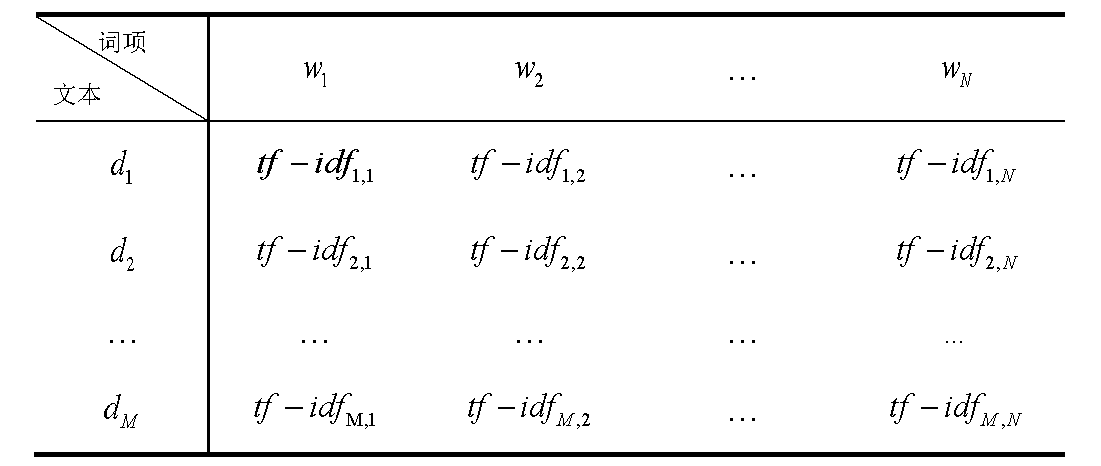
矩阵元素tf−idfi,j=tfi,j⋅idfjtf−idfi,j=tfi,j⋅idfj,其中:
ni,jni,j 表示词项ωjωj 在文本didi中的频数,∑Nj=1ni,j∑j=1Nni,j则为文本didi的总词数;
|D||D|为文本集合 中的总文本数, |{I:wj∈di}||{I:wj∈di}|表示包含词项 wjwj的总文本数,由于矩阵的稀疏性, |{I:wj∈di}||{I:wj∈di}| 可能趋近于零,故一般采用idfi=log|D|1+|{i:wj∈di}|idfi=log|D|1+|{i:wj∈di}|的计算形式。
(2)聚类模型设定
结构化处理后,每一个文本即每一条评论语料都对应着一个以词项TF-IDF值为元素的向量,对不同评论进行聚类,就是向量d1,?,dMd1,?,dM的聚类,其中di=[tf−idfi,1,tf−idfi,2,?,tf−idfi,N](i=1,2,?,M)di=[tf−idfi,1,tf−idfi,2,?,tf−idfi,N](i=1,2,?,M);记词汇向量wj=[tf−idfi,j,tf−idf2,j,?,tf−idfM,j](j=1,2,?,N)wj=[tf−idfi,j,tf−idf2,j,?,tf−idfM,j](j=1,2,?,N)。
聚类过程中,并不是所有的词汇都是聚类的相关变量,使用这些变量会增加聚类过程中的噪音,会妨碍挖掘真实的聚类结构[3]。所以,为了提高聚类效果,有必要在聚类之前或者聚类过程中进行变量筛选,减少聚类变量数目,即降低矩阵维度,来增加聚类的准确性。鉴于惩罚GMM聚类的优势[4]以及对高维文本IF-IDF矩阵聚类的适用性[5],本文采用惩罚GMM模型来实现文本聚类。
假设文档集合服从高斯混合模型f(di)=∑Kk=1πkNk(dk;μk,Σk)f(di)=∑k=1KπkNk(dk;μk,Σk) ,其中,πkπk是混合比率,满足0≤πk≤10≤πk≤1 ,且∑Kk=1πk=1∑k=1Kπk=1 ,μk=(μk1,?,μkj,?,μkN)μk=(μk1,?,μkj,?,μkN) 为第k个类的高斯分布的均值向量,ΣkΣk 即为相应的方差协方差矩阵。本文我们将注意力集中在高维数据上,故简单假设 Σk=Σ=diag(σ21,?,σ2j,σ2N)Σk=Σ=diag(σ12,?,σj2,σN2),即不同类的方差协方差矩阵都是相同的,并且均为对角矩阵。该模型的含义在于,观测文档数据来自由K个子类组成的总体,每个文档由第 个类生成的概率为 ,基本的思想就是为每个子类的数据分布假定了一个概率模型,并利用有限混合模型将总体模型作为这些子类模型的混合,通过逐渐逼近的方法,使得模型可以最佳拟合给定的数据集。在有限混合模型中,每一个成分对应一个类。这样关于合适的聚类方法以及聚类数目的问题转化为关于模型如何选择的问题。和通常所用的系统聚类法(或称层次聚类法)及K-means聚类法相比,基于混合模型的聚类并不是仅仅给出关于聚类样品的类标签,而是给出了每个聚类样品属于某一个类(作为模型成分的分布)的概率,并由此来决定类别的标签。
对于某一给定的观测文档d∗=[tf−idf∗1,tf−idf∗2,?,tf−idf∗N]d∗=[tf−idf1∗,tf−idf2∗,?,tf−idfN∗],可以计算d∗d∗ 来自类别k的概率为:
d∗d∗将被归类于pkpk最大的那一类。
记 Θ={σ2j,πk,μkj,k=1,?,K;j=1,?,N}Θ={σj2,πk,μkj,k=1,?,K;j=1,?,N}作为包含所有参数的集合,给定数据d1,?,dnd1,?,dn ,对数似然函数为:
设惩罚模型通式为:
本文选择L1L1 惩罚,即
基于参数ΘΘ 求上式的最大值通常是比较困难的,本文采用期望最大算法(expectation maximization (EM) algorithm) (Dempster, Laird, Rubin(1977))[6],引进隐含变量τikτik ,为 didi是否来自于类别k的示性函数,即当 来自于类别k时,τik=1τik=1 ,否则τik=0τik=0 ,如果可以获得数据τikτik 的观测值,以上的对数似然函数就可以转换为:
对式(8)求解即可得到未知参数估计值以及相应的聚类结果[7]。
从抓取的评论语料中抽取部分语料人工进行评论主题标注,以标准主题为类别标准,对比不同聚类方法的聚类效果进行对比评价。标注评论语料总计57条,共标注为6个主题,基本构成如2表所示。
表2 标注语料构成
| 类别序号 | 语料条数 | 标注主题 | 类别序号 | 语料条数 | 标注主题 |
| 1
2 3 |
11
5 11 |
闪屏
免费书少 有亮点 |
4
5 6 |
11
12 7 |
价格偏高
不伤眼 轻 |
本文采用纯度(purity)和F值两个指标评价聚类系统的整体性能。假设标注的类别用L表示,共有I类,其中第i个标注类别表示为LiLi ,同样,假设聚类类别用K表示,共有J类,则第j个聚类类别表示为KjKj ,聚类结果和标注结果匹配表如表3所示。
表3聚类结果匹配表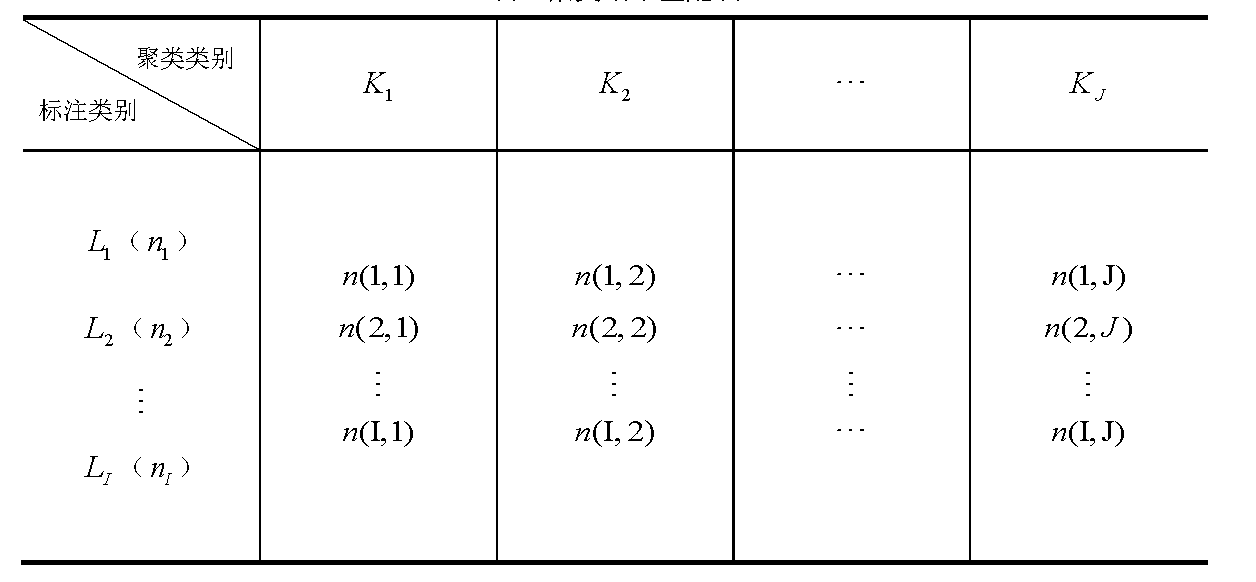
其中nijnij表示聚类结果j中包含的标注类别为i的样本个数,括号中的nini 表示标注的类别LiLi 中包含的样本数,即ni=∑Jj=1n(i,j)ni=∑j=1Jn(i,j) 。定义聚类类别j的纯度p(i,j)p(i,j) 如下:
定义整体聚类纯度为:
其中,n为样本总数,该值越大,说明聚类的结果与被分析的数据越匹配,即算法的有效性越高。
对于F值的定义参照信息检索的评测方法,将每个聚类结果看做查询结果,对于聚类类别j和标注类别i,有以下定义:
形式类似信息检索评测的准确率和召回率。标注类别i和聚类类别j之间的f值定义为:
$$f(i,j)=\frac{2 \times precision(i,j) \times recall(i,j)}{recision(i,j) + recall(i,j) }(13)
最终聚类结果的评价函数F表示为:
以聚类纯度和F值为评价指标,分别运用K-means欧式距离聚类、K-means余弦距离聚类[8][9]、惩罚高斯混合模型聚类对标注的文本进行聚类,得到的聚类效果对比汇总如表4所示。
表4 不同文本聚类方法聚类指标对比
| K-means欧式距离 | K-means余弦距离 | 惩罚GMM | |
| 聚类纯度
F值 |
–
– |
35.09%
0.35 |
71.93%
0.62 |
综合以上分析结果,对文本TF-IDF矩阵进行聚类时,K-means欧式距离聚类、K-means余弦距离聚类和惩罚GMM聚类三种方法中,惩罚GMM聚类效果最好,K-means余弦距离聚类其次,K-means欧式距离聚类效果最差。在处理大量文本聚类问题时,应首先考虑惩罚GMM聚类以提高聚类效果。
本部分选取文本聚类效果最好的惩罚GMM模型对全部5477条评论语料进行聚类,最终得到8个有效聚类结果,实现了评论文本话题自动、快速聚类。通过这种文本聚类方式,即使有上千条评论语料,也可在很短的时间内准确抓取热点话题,提取消费者关注的产品属性。
各个类别对应的标签以及评论数见表5,部分详细聚类结果如表6所示,同时绘制了类别的词云图(图9至12),增强结果的可读性。
表5 聚类结果分布
| 类别标签(主题) | 评论数 | 类别标签(主题) | 评论数 |
| 喜欢
感觉好 翻页闪屏 屏幕 |
116
484 184 2056 |
感觉不错
电子书券 还好 阅读 |
200
77 14 243 |
从聚类结果可以看出,可以实现热点话题识别,热点话题涉及到顾客针对产品的态度、反馈的问题、提出的意见等等,这些话题的内容深刻影响着潜在消费者的购买意愿,所以销售者面对这些话题要及时作出反馈,如产品存在的问题要及时改进、消费者提出的质疑要及时回应等,只有不断发现问题、不断修正,才能在维护好既有用户的同时吸引更多的潜在顾客,创造更多的商业价值。
从表5可以看出,在所有kindle评论中,超过三分之一的评论围绕“屏幕”这一话题展开,可见对于kindle这款产品人们最关心的莫过于屏幕的质量,针对主题为“屏幕”的评论文本类,可以进一步提取顾客对屏幕属性的评价,发现反馈最多的问题包括:阴阳屏、屏幕亮点、屏幕发黄、分辨率低等等,这就为产品质量的提升指出了明确的方向;另外,“翻页闪屏”问题也颇受关注,消费者反馈,kindle系列产品在翻页时存在闪屏现象,导致阅读体验大打折扣;此外,“喜欢”、“感觉好”、“感觉不错”三个文本类都表现了消费者对kindle这款产品积极的评价态度,在一定程度上有助于商家快速了解顾客评价倾向,以便及时作出经营策略调整;“电子书券”文本类中包含77条评论,通过查看评论文本,得知,kindle voyage 这一款产品在销售时许诺赠送100元电子书券,但是很多顾客反映并未收到电子书券并要求商家做出解释,针对这种类型的聚类结果,销售者应予以重视并及时与顾客沟通,最小化事件不良影响,营造产品良好口碑。
表6 聚类结果汇总
| 类标签 | 评论数 | 评论语料 |
| 喜欢 | 116 | 挺喜欢的,有一些小缺陷,但也没有其他评论说的那么恐怖 |
| 女朋友是很爱看书的类型 但是携带起来不太方便 就给她买了kindle 她说很喜欢 手感也很好 | ||
| 不错的电子书阅读器,给女儿买的,看来她很喜欢 | ||
| 很喜欢,可以好好阅读了 | ||
| 很喜欢,感觉像宝藏一样的,去哪都可以带着它,可以利用很多碎片时间来看书,太阳底下也很清楚哦,喜欢读书的你们,赶快下手吧,你不会后悔的:) | ||
| …… | ||
| 翻页闪屏 | 184 | 似乎反应不是很灵敏, 要很长时间才能翻页. 另外, 没有纸制的说明书 |
| 之前使用kp2,确实有闪屏,但看书时就会被书的内容吸引,闪屏问题就会潜意识忽略了。kp3相比,性能提升了很多,很细腻,体验很好。培养看书习惯之良品 | ||
| 第一次用这电子阅读器,翻页效果一闪一闪的,实在受不了 | ||
| 总体还不错 四星是因为价格稍贵和无法避免的闪屏 背光很有用 亮度也可以调节 | ||
| 每次翻页都会闪两下 对于眼睛来说不是很舒服 但时间长了就习惯了 | ||
| …… | ||
| 感觉不错 | 200 | 第一次买kindle,刚好新出了一款,感觉还是不错的 |
| 用了一段时间,感觉还不错。也没碰到常见的商品问题。 | ||
| 不错,300ppi果然好多了啊 | ||
| 用来看书不错,反应速度有点迟钝 | ||
| 第一个发光不均匀,售后和快递服务都不错。拍照,技术确认,很快就给发了个新的。新的还不错,使用再看看 | ||
| …… |

图9 话题“喜欢”词云图

图10 话题“翻页闪屏”词云图
图11话题“不错”词云图

图12话题“电子书券”词云图
本文从电子商务文本数据分析需求出发,针对文本数据结构化处理后高维稀疏的特性,提出将惩罚高斯混合模型应用于文本聚类,以纯度和F值两个指标为评价标准,利用人工标准主题的语料验证了惩罚高斯混合模型聚类方法在评论文本聚类方面的优越性,最后将其应用到亚马逊热门产品kindle的评论分中,得到8个有效聚类,即8个热点话题,结合产品特点以及业务需求,参照聚类结果提出了产品和服务的具体改进建议。
本文的研究重点集中于文本数据的结构化处理和文本聚类两个方面,虽然取得了较好的分析效果,但是不论在研究方法还是研究深度上都还有改进空间。在文本聚类方面,降维处理可采用的惩罚函数有多重形式,本文只考虑了L1范数惩罚,并未考察分组或分层等惩罚形式[10],所以未来有必要进一步针对文件聚类的更加高效的方法;此外,在聚类分析的基础上有必要进行更加深入的文本挖掘探索,如文本情感分析、产品属性评价提取等,实现评论文本更加全面、细致的分析,充分挖掘文本信息的价值,为电子商务经营提供更加精准的建议。
参考文献
[1] Dave K, Lawrence S, Pennock D M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews[C]//Proceedings of the 12th international conference on World Wide Web. ACM, 2003: 519-528.
[2] 王和勇, 蓝金炯. 面向海量高维数据的文本主题发现[J]. 情报杂志, 2015, 34(11),162-167.
[3] 张亮, 李敏强. 一种有限混合模型对无监督文本聚类的广义方法[J]. 模式识别与人工智能, 2007, 20(5),698-703.
[4] Pan W, Shen X. Penalized model-based clustering with application to variable selection[J]. The Journal of Machine Learning Research, 2007, 8, 1145-1164.
[5] Willett P. Document clustering using an inverted file approach[J]. Journal of Information Science, 1980, 2(5), 223-231.
[6] Dempster A P, Laird N M, Rubin D B. Maximum likelihood from incomplete data via the EM algorithm[J]. Journal of the royal statistical society. Series B (Statistical Methodology), 1977, 1-38.
[7] Maugis-Rabusseau C, Michel B. Adaptive density estimation for clustering with Gaussian mixtures[J]. ESAIM: Probability and Statistics, 2013, 17, 698-724.
[8] Hatagami Y, Matsuka T. Text mining with an augmented version of the bisecting k-means algorithm[C]//Neural Information Processing. Springer Berlin Heidelberg, 2009, 352-359.
[9] Yao M, Pi D, Cong X. Chinese text clustering algorithm based k-means[J]. Physics Procedia, 2012, 33: 301-307.
[10] Zhao P, Rocha G, Yu B. Grouped and hierarchical model selection through composite absolute penalties[J]. Department of Statistics, UC Berkeley, Tech. Rep, 2006, 703.
转自:http://cos.name/2016/05/e-commerce-customer-reviews-hot-topic-analysis/
标签:
原文地址:http://www.cnblogs.com/payton/p/5567755.html