标签:
简介
最近测试服务器进行数据归档,其间程序员发现一个问题,空间不足,我查看原因发现日志文件暴涨。然后将数据库改为简单恢复模式,但是依然存在这个问题。经过查询资料发现了日志文件在简单模式下依然增加的原因。
Simple概念
Simple恢复模式也叫做”Checkpoint with truncate log“,其实这个名字更形象,在Simple模式下,SQL Server会在每次checkpoint或backup之后自动截断log,也就是丢弃所有的闲置日志记录,仅保留用于实例启动时自动发生的instance recovery所需的少量log,这样做的好处是log文件非常小,不需要DBA去维护、备份log,但坏处也是显而易见的,就是一旦数据库出现异常,需要恢复时,最多只能恢复到上一次的备份,无法恢复到最近可用状态,因为log丢失了。
Checkpoint
CheckPoint和lazyWriter一样,都会将缓冲区内脏数据写入到磁盘,同时在简单恢复模式下截断日志;lazyWriter缓存不足的时候会触发执行,这里我们暂且不做讨论。
针对CheckPoint我请教了Careyson以后总结出以下几个触发其执行的原因:
场景描述:
Simple模式主要用于非critical的业务,比如开发库和测试库,那么这次由于测试环境的磁盘紧张我们也都采用了简单模式。但是数据归档发生时依然产生了大量的日志,并且增加了磁盘占用,这又是什么原因那?因为我们在归档处理中使用了大量的insert和delete以及update操作,这样话,短时间内产生了大量的日志,这个时候日志迅速增加;又因为在SQL Server中,CheckPoint是一个完整的过程,这个过程的耗时取决于脏数据的大小。一旦在很短时间内,日志的CheckPoint没完成的时候日志增加超过了日志的规定上限。则将产生更多的日志。
如上所述,产生这个问题的原因就是:CheckPoint时间间隔阈值被足够多的日志记录超过,触发CheckPoint才写入磁盘。
下面这个实例来自于:
让我们用一个脚本来实际的阐明这种行为。首先在一个测试数据库中运行一下脚本创建一个测试表并填充一些数据。
测试数据库设置:
1.设置为简单的恢复模式。
2.日志的大小为100M。
3.日志文件的自动增长被禁用(因为观察日志空间被用完的错误比检查自动增长要容易)。

运行以下脚本,观察资源竞争:
反复根据修改@change_size来看结果,当我将@change_size改为120甚至更大时,得到了9002的错误信息,非常准确的告诉我数据库的事务日志已满。
通过上面这个引用的例子,很好地再现了问题的产生机制,那么我们怎么处理这个情况那?
解决
方案1:
强制执行CheckPoint。但是执行后有个很不好的影响,严重影响了存储过程的执行时间。由此可知这样做很消耗性能啊。
方案2:
缩短CheckPoint时间间隔阈值。
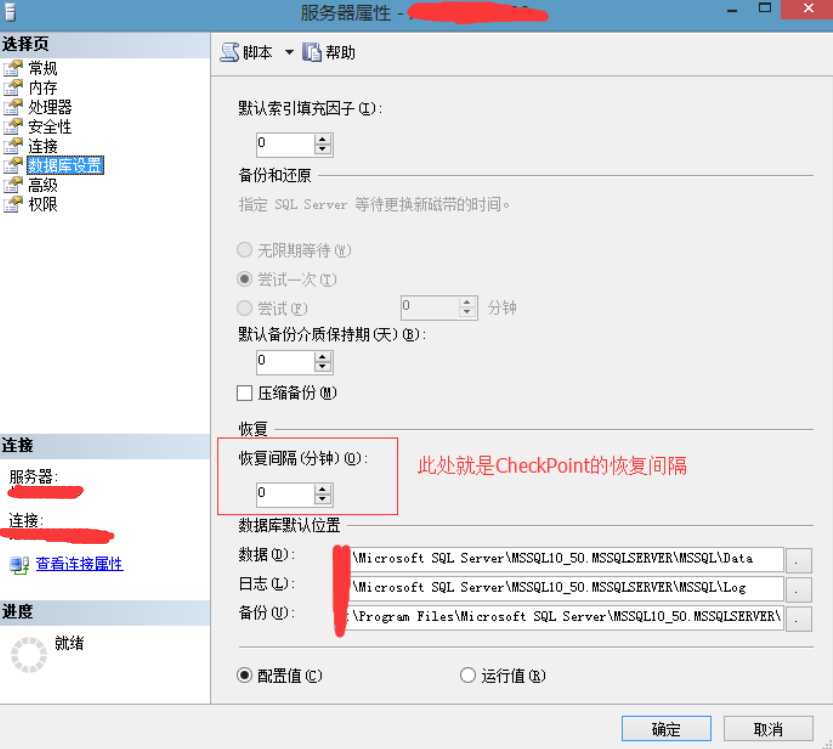
默认值是0,意味着由SQL Server来管理这个回复间隔。
也可以SQL语句实现这个功能:
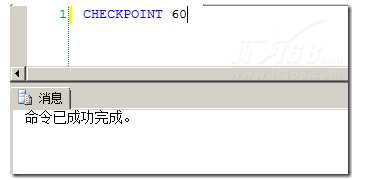
方案3:
增大日志文件大小。
总结:
日志文件是一个双刃剑,WAL机制很好的保证了数据的一致性和维护性。但是也产生了额外的性能和维护的成本的上升。需要我们根据实际情况去处理这些不同的情景。需要注意的是在TempDB中是不会产生日志的,除非手动执行。除此之外,并非所有的时间间隔后都会产生日志,因为当数据很少的时候有可能不触发Checkpoint执行。
标签:
原文地址:http://www.cnblogs.com/wenBlog/p/5569911.html