标签:
为什么要用装饰器???
在实际的开发环境中应遵循开发封闭原则,虽然在这个原则是用的面向对象开发,但也适用于函数式编程,简单地说,它规定已经实现的功能代码不是允许修改的,但是可以被扩展:
封闭:已实现的功能代码块
开发:对扩展开发
装饰器功能:
1)自动执行装饰器下面的函数,并将被装饰器函数的函数名当做参数传递给装饰器函数
2)装饰器函数的返回值,重新赋值给被装饰函数
#装饰器格式:@+函数名
#装饰器格式:@+函数名
def outer(func):
def inner(arg): #原函数传递一个参数
print(‘before‘)
# func() #func:表示原函数
# return func() 程序遇到return时则不执行下面函数
ret = func(arg) #func:表示获取原函数返回值
print(‘after‘)
return ret #打印原函数返回值
return func #当函数名在带()时表示,此时函数名代表整个函数,如加()-》表示执行函数
#自动执行outer函数并且将下面的函数名F1当做参数传递
#将ouetr函数的返回值,重新赋值给F1
def outer(func):
def inner(*arg,**kwargs):
print(‘before‘)
# func() #func:表示原函数
# return func() 程序遇到return时则不执行下面函数
ret = func(*arg,**kwargs) #func:表示获取原函数返回值
print(‘after‘)
return ret #打印原函数返回值
return func #当函数名在带()时表示,此时函数名代表整个函数,如加()-》表示执行函数
@outer
def f1(arg): #f1:原函数 #当f1里面传递几个参数时,那么装饰器中的函数体inner也需要传递给几个参数
print(arg)
@outer
def f2(arg1,arg2): #传递多个参数时
print("F2")
1)、功能:利用代码的可重复性,实现复杂的功能(即:在不修改源程序前提下,通过修改装饰器传递参数达到执行函数的效果)
USER_INFO={} #定义一个空的字典
USER_INFO[‘is_login‘] #字典取值形式为key, Value形式,如果此时只取key,不取value时,系统则报错
#字典取值形式为key, Value形式,如果此时字典中没有value时,可定义一个None值,这样当取不到字典中的value值,则系统返回None值
USER_INFO.get(‘is_login‘,None)
#定义一个装饰器
def check_login(func): #03此时func只的是check_admin中inner函数
def inner(*args,**kwargs):
if USER_INFO.get(‘is_login‘,None): #默认情况下,用户不存在,则返回值为None
ret1 = func(*args,**kwargs) # 04此时func代表指的check_admin-》inner函数下
return ret1 #注意ret后面不能加(),如添加():表示执行函数
else:
print("请登入!!!")
#及判断登入和权限
def check_admin(func):
def inner(*args,**kwargs):
if USER_INFO.get(‘user_type‘,None)==2: #2表示超级管理员
ret2 = func(*args,**kwargs) #此时func为原来index函数
return ret2 #此时ret2返回值传输给check_login装饰器中的ret2
else:
print("无权限查看")
return inner
#双层装饰器==》嵌套函数,装饰器是从下往上解释,执行是从上往下执行
@check_login #02 装饰器接着把check_admin和(check_admin、index)当做一个参数传递给check_login下面inner函数
@check_admin #01 装饰器把将check_admin和index当做一个参数传递给inner函数,
def index():
"""
管理员功能
:return:
"""
print(‘Index‘)
可以加参数的装饰器@filter(before,Agter),用于web程序
Python中字符串格式化有两种方式:%百分号方式、format方式
1、%百分号方式
%百分号方式相对而言比较老。而format方式则是比较先进的方式,Pyhton两者并存
百分号方式传值方式:%[(name)][flags][width].[precision]typecode
name:可选,用于选择指定的key
flags:可选,可选择的值有
1)+:右对齐:正数前加正好,负数前加符号
#向右对齐且宽度为10个字节
s = "i am %(name)+10s,%(age)d"%{‘name‘:‘lcj‘,‘age‘:123} #将字典中的元素按照key,value形式传递name,age
print(s)
2)-:左对齐:正数前无符号,负数前加符号
#向左对齐且宽度为10个字节
s = "i am %(name)-10s,%(age)d"%{‘name‘:‘lcj‘,‘age‘:123} #将字典中的元素按照key,value形式传递name,age
print(s)
3)空格:右对齐:正数前加空格,负数前加负号
4)0:右对齐:正数前无符号,负数前加负号:用0填充空白处
typecode:选项
•s,获取传入对象的__str__方法的返回值,并将其格式化到指定位置
•r,获取传入对象的__repr__方法的返回值,并将其格式化到指定位置
•c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
•o,将整数转换成 八 进制表示,并将其格式化到指定位置
•x,将整数转换成十六进制表示,并将其格式化到指定位置
•d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
•e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
•E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
•f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
•F,同上
•g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
•G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
•%,当字符串中存在格式化标志时,需要用 %%表示一个百分号
注:Python中百分号格式化是不存在自动将整数转换成二进制表示的方式
常用格式化:
#将元素传递给占位符
n1 = "i am is %s" %"lcj"
print(n1)
#将元祖中的元祖依次传递给占位符%s %d
n2 = "i am %s age %d"%("lcj",18)
print(n2)
#将字典中的每一个元素指定传递给占位符
n3 = "i am %(name)s age%(age)d"%{"name":"lcj","age":18}
print(n3)
#取小数点前2位并按照四舍五入取值
n4 = "percent %.2f"%99.885
print(n4)
#定点取小数
n5 = "i am %(pp).2f"%{"pp":123.45621,}
print(n5)
#
n6 = "i am %.2f %%"%{"pp":123.4732,}
print(n6)
#c:将数字转换至unicode对应的值,10进制范围为0<=i<=114111(py27则只支持0-255),字符:将字符添加至指定位置
n7 = "lcj %c----%o----%x---%e"%(65,15,15,1000000000)
print(n7)
n8 = "lcj %"
print(n8)
#在格式化字符串中,出现占位符(%s %d %f),那么需要用了两个%%号输出时表示一个%号(转移效果)
n9 ="name %s %%"%("lcj")
print(n9)
顺序传值:
s = "i am name %s,age %d"%(‘lcj‘,123) #lcj传递给name,123传递给age
print(s)
指定元素进行传值:
#指定传值
s = "i am %(name)s,%(age)d"%{‘name‘:‘lcj‘,‘age‘:123} #将字典中的元素按照key,value形式传递name,age
print(s)
2、format方式
格式:[[fill]align][sign][#][0][width][,][.precision][type]
#基本格式化 n1 = "l---{0}----c-{0}---j--{1}".format(123,‘xialuo‘) print(n1) #指定传值将字符串传给s,数字传给d n2 = "i am--name-{name:s}--age-{age:d}".format(name="xiaoluo",age=19) print(n2) #":"冒号前加参数,则是按照命名方式进行传值,如不添加参数,则顺序传值 n3 = "{:*^23s}===".format("clj") print(n3) #^内容居中,<:内容向左对齐,打印元素“*”只能用一个字符代替,不能用数据替换 n4 = "{:*<23s}===".format("clj") print(n4) #^内容居中,>:内容向右对齐(默认),打印元素“*”只能用一个字符代替,不能用数据替换 n5 = "{:*>23s}===".format("clj") print(n5) #^内容居中,= # n6 = "{:*=23s}===".format("clj") # print(n6) #format中单个%表示百分符号即把传递参数向前进2位并保留小数位 n7 = "---{:%}".format(0.33333) print(n7) #保留小数点前两位 n8 = "---{:.2%}".format(0.33333) print(n8)
•传入” 字符串类型 “的参数 •s,格式化字符串类型数据
•空白,未指定类型,则默认是None,同s
•传入“ 整数类型 ”的参数
•b,将10进制整数自动转换成2进制表示然后格式化
•c,将10进制整数自动转换为其对应的unicode字符
•d,十进制整数
•o,将10进制整数自动转换成8进制表示然后格式化;
•x,将10进制整数自动转换成16进制表示然后格式化(小写x)
•X,将10进制整数自动转换成16进制表示然后格式化(大写X)
•传入“ 浮点型或小数类型 ”的参数 •e, 转换为科学计数法(小写e)表示,然后格式化;
•E, 转换为科学计数法(大写E)表示,然后格式化;
•f , 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
•F, 转换为浮点型(默认小数点后保留6位)表示,然后格式化;
•g, 自动在e和f中切换
•G, 自动在E和F中切换
•%,显示百分比(默认显示小数点后6位)
常用格式化:
#format顺序传值给站位符{}
n1 = "i am {},age{},{}".format("lcj",15,‘yxy‘)
print(n1)
#将列表中的每一个元素顺序添加至占位符中,如果列表前不添加*号,则把列表中所有元素当做一个元素进行传值
n2 = "i am {},age{},{}".format(*["lcj",18,‘yxy‘])
print(n2)
#按照索引方式进行传值
n3 = "i am {0},age{1},really{0}".format("lcj",13)
print(n3)
#将列表中的元素按照索引方式进行传值
n4 = "i am {0},age{1},really{0}".format(*["lcj",13])
print(n4)
#指定参数进行传值
n5 = "i am {name},age{age},really{age}".format(name="lcj",age = 12)
print(n5)
#将字典中元素指定传值
n6 = "i am {name},age{age},really{name}".format(**{"name":"lcj","age":12})
print(n6)
#按照索引中索引进行传值:0-》表示第一个列表,第二个0:》表示取第一个列表中的第一个元素
n7= "i am {0[0]},age{0[1]},really{0[2]}".format([1,2,3,],[4,5,6,])
print(n7)
#依次给站位符传递“字符串”,“数字”,“浮点数”
n8 = "i am {:s},age{:d},really{:.2f}".format("lcj",19,19.823)
print(n8)
#将列表中各元素按照字符串和数字依次进行传递,参数传递给%s %d的位置要一致
n9 = "i am {:s},age{:d}".format(*["lcj",19])
print(n9)
#给占位符s,d指定参数
n10 = "i am {name:s},age{age:d}".format(name=‘lcj‘,age=20)
print(n10)
#给占位符按照字典方式进行传值
n11 = "i am {name:s},age{age:d}".format(**{"name":"xiaoluo","age":19})
print(n11)
#把传递参数按照“b:二进制,o:八进制,d:十进制,x:十六机制”方式进行传给占位符
n12 = "number:{:b},{:o},{:d},{:x},{:X}".format(15,15,15,15,15,15.876,12)
print(n12)
#按照下标对占位符进行传值
n13 = "number:{0:b},{0:o},{0:d},{0:x},{0:X}".format(16)
print(n13)
#给站位符指定参数进行传值
n14 = "number:{num:b},{num:o},{num:d},{num:x},{num:X},{num:%}".format(num=17)
print(14)
[更多操作格式更多格式化操作:https://docs.python.org/3/library/string.html]
format占位符号为:{}
%百分号于format之间的区别?
1)format支持二进制方式,%百分号则不支持
2)format中的单个%则输出
#format中单个%表示百分符号即把传递参数向前进2位并保留小数位
n7 = "---{:%}".format(0.33333)
print(n7)
#保留小数点前两位
n8 = "---{:.2%}".format(0.33333)
print(n8)

python中有两个模块序列化方式:
json:用于字符串和python基本数据类型之间的转换
pickle:用于python特定的类型和python基本数据类型之间的转换
1、json
常用的元素:dumps、dump,loads、load
dumps:将python基本数子格式转化至字符串
loads:将字符串格式转换至python基本数子格式
序列化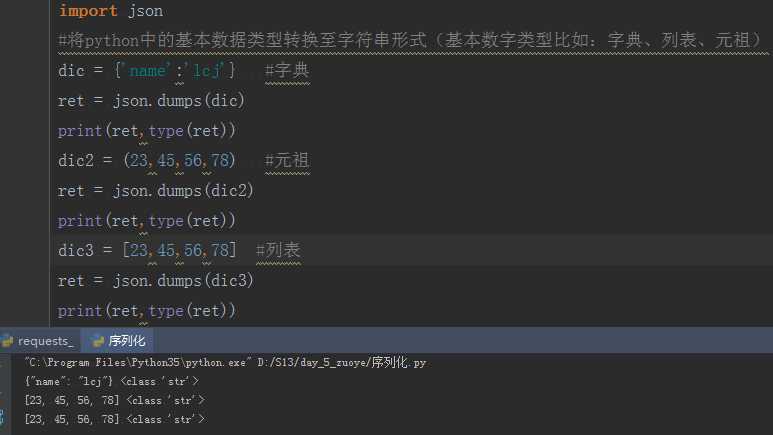
反序列化:
#json.loads [使用loads进行反序列化时,基本数字必须用双引号]
import json
#将python中字符串形式转化成基本数据类型
s1 = ‘{"name":"lcj"}‘
ret = json.loads(s1)
print(ret,type(ret))
dump:把python基本数据类型转化为字符串形式,并把转化的字符串写入文件
load:把字符串形式的数据转化python基本数据类型,并从文件中读取出来

import json
#将基本数据类型转换字符串形式, 并存入文件
li = {"name":"lcj"}
ret = json.dump(li,open("db",‘w+‘))
print(ret,type(ret))
#打开文件,并将python中文件字符存转换至基本数据类型,
li =json.load(open(‘db‘,‘r‘))
print(li)
2、pickle
pickle序列化只适合用于python,其他语言不能调用,json则是任何语言都一个调用或交互
常用的元素:dumps、dump,loads、load
json与pickle之间对比:
A:json:更加适合跨语言,字符串、基本数据类型
B:pickle:python中复杂类型的序列化,缺点:仅适用于Python(python各版本之间各有差异)
import pickle
#将python基本数据类型转化为字符串形式
li =[22,33,44,55,]
ret = pickle.dump(li,open("test.txt",‘wb‘)) #将列表中的元素,按照自己方式写入文件
print(ret,type(ret))
#按照字节方式将文件中的字符串形式转化至列表
ret = pickle.load(open("test.txt",‘rb‘))
print(ret,type(ret))
什么是模块呢?
简单的来说模块代买实现了某一个功能的代码集合。
类似于函数编程和面向对象过程编程,函数式编程则完成一个功能,ITA代码用来调用即可,提供了代码的重用性和代码间的耦合,二对对于一个复杂的功能来可能需要多个模块函数才能完成(函数即可在不用的.py模块中),n个.py文件组成的代码集合就称为模块。
1、模块分为三类:
1)、内置模块
python内置模块含:
A:sys模块:
用于提供python解释器相关的操作:
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0)
sys.version 获取Python解释程序的版本信息
sys.maxint 最大的Int值
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
sys.stdin 输入相关
sys.stdout 输出相关
sys.stderror 错误相关
B:os模块
用于提供对Python解释器相关的操作:
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: (‘.‘)
os.pardir 获取当前目录的父目录字符串名:(‘..‘)
os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录
os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat(‘path/filename‘) 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
os.pathsep 输出用于分割文件路径的字符串
os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
2)、自定义模块
3)、第三方模块
安装第三方模块方式有两种:
1)pip3安装 :pip3 install requests
2)源码安装:进入源码安装路径,执行python setup.py install
注意:当pip无法安装时:
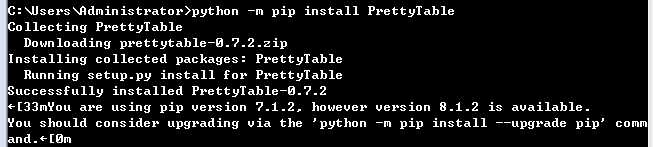
python中requests模块安装方式:(用于http请求时用到模块)
A:python3可用:pip3 install requests
使用requests模块:
无参数:
#无参数下
import requests
import json
requests = requests.get(‘http://wthrcdn.etouch.cn/weather_mini?city=北京‘)
requests.encoding = ‘utf-8‘
dic =json.loads(requests.text) #requests获取天气预报信息
print(dic,type(dic)) #将获取信息转换至一个字典形式
print(dic,list(dic))
#有参数下
import requests
payload = {‘key1‘: ‘value1‘, ‘key2‘: ‘value2‘}
ret = requests.get("http://httpbin.org/get", params=payload)
print(ret.url)
print(ret.text)
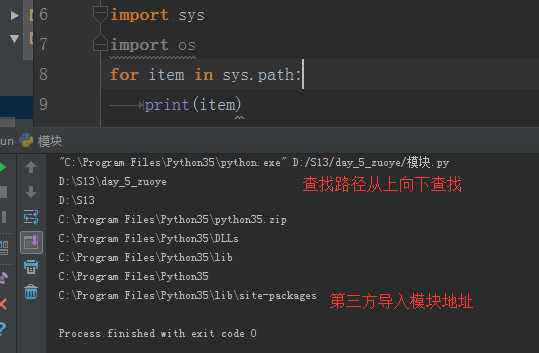
导入模块依据:import sys
导入模块即使告诉Python解释器其解释那个py文件
1)导入一个py文件,解释器解释py文件
2)导入一个包,解释器解释该包下的_init_.py文件【Python2.7】
导入模块路径:
2、模块的优点:
A:进行代码归类
python查找脚本顺序:首先在当前执行脚本的目录下查找脚本,如找不到,则去python内置的路径查找
模块名称重要性:
A:不能个python内置模块名称一样,否则出错
到入模块方式有:
A:import +模块名
B:from(去某个模块带入某个函数)【form s4 import login -->去S4模块导入login函数】
C:在不同模块中导入相同函数时,可以给导入函数取别名
列如:
D:在单模块下推荐:import导入模块
在嵌套文件夹中推荐:from XX import xxx 或者给导入模块取别名
1、迭代器:
迭代器是访问集合元素的一种方式,迭代器对象是从集合的第一个元素开始访问,直到所有的元素被访问完才结束。迭代器只向前访问不会后退。
迭代器特点:不要求是先准备好整个迭代过程中的所有的元素,迭代器仅仅在迭代到某一个元素时才计算该元素,而在这之前之后,元素不存在,适用于遍历一些巨大的或是无限的集合,如几个G的文件
A:反问者不需要关系迭代器内部的结构,仅需通过_next_()方法不断去取下一个内容
B:不能随机访问集合中的某个值,只能从头到尾一次访问
C:访问到一半时不能往回退
D:便于循环比较大的数据集合,节省内存
#生成器标志:yield,使用函数创建
def func():
print(111)
yield 1
print(2222)
yield 2
print(33333)
yield 3
ret = func()
r1=ret.__next__()#进入函数找到yield,获取yield后面的数据
print(r1)
r2=ret.__next__()#进入函数找到yield,获取yield后面的数据
print(r2)
r3=ret.__next__()#进入函数找到yield,获取yield后面的数据
print(r3)
2、生成器
一个函数调用时返回一个迭代器,那么这个函数叫做生成器(generator);如何函数中包含yield语法,那么这个函数就会变成生成器
def func():
print(111)
yield 1 #yield表示生成器标识
print(2222)
yield 2
print(33333)
yield 3
什么是递归函数?
如果函数包含了对其自身的调用,那么该函数就是递归函数
def d():
return ‘lcj‘
def c():
r=d()
return r
def b():
r=c()
return r
def a():
r=b()
print(r)
a()
def func(n):
n += 1
if n >=4: #当递归参数大于等于4,则返回end,否则继续
return ‘end‘
return func(n)
ret =func(0)
print(ret)
递归官方解释
(1)递归就是在过程或函数里调用自身;
(2)在使用递归策略时,必须有一个明确的递归结束条件,称为递归出口。
递归算法一般用于解决三类问题:
(1)数据的定义是按递归定义的。(比如Fibonacci函数)
(2)问题解法按递归算法实现。(回溯)
(3)数据的结构形式是按递归定义的。(比如树的遍历,图的搜索)
递归的缺点:递归算法解题的运行效率较低。在递归调用的过程当中系统为每一层的返回点、局部量等开辟了栈来存储。递归次数过多容易造成栈溢出等。
参考:http://www.cnblogs.com/balian/archive/2011/02/11/1951054.html
时间相关的操作,时间含有三张表示方式:
1、time模块
import time
#打印时间戳
print(time.time())#返回值为:1465439178.2469485 unix上线至今秒
#输出当前系统时间
print(time.localtime())
#将时间戳转换至struct_time格式
print(time.gmtime(time.time()))
#截取指定时间段
time_obj = time.gmtime()
print(time_obj)
print("{year}-{month}".format(year=time_obj.tm_year,month=time_obj.tm_mon))
#将时间戳转换至struct_time格式,并返回本地时间
print(time.localtime(time.time()))
#与time.localtime()功能相反,将struct_time格式转换至时间戳格式
print(time.mktime(time.localtime()))
#将struct_time时间对象转成一个指定的时间格式:年月日时分秒
print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime())) #gmtime:转换至格林尼治标准时间
#将字符串格式转换成struct_time格式:
k = time.strptime("2016-06-09","%Y-%m-%d")
print(k)
print("---------------")
#将一个字符串格式的时间转换至一个时间戳
k = time.strptime("2016-06-09","%Y-%m-%d")
print(time.mktime(k))
%Y Year with century as a decimal number.
%m Month as a decimal number [01,12].
%d Day of the month as a decimal number [01,31].
%H Hour (24-hour clock) as a decimal number [00,23].
%M Minute as a decimal number [00,59].
%S Second as a decimal number [00,61].
%z Time zone offset from UTC.
%a Locale‘s abbreviated weekday name.
%A Locale‘s full weekday name.
%b Locale‘s abbreviated month name.
%B Locale‘s full month name.
%c Locale‘s appropriate date and time representation.
%I Hour (12-hour clock) as a decimal number [01,12].
%p Locale‘s equivalent of either AM or PM.
2、datetime模块
import datetime
#将时间按照:2016-06-09输出
print(datetime.date.today())
#输出2016-01-26 19:04:30.335935
current_time = datetime.datetime.now()
print(current_time)
#将当前时间返回值struct_time格式
print(current_time.timetuple())
#将当时前时间加10天
print(datetime.datetime.now()+datetime.timedelta(days=10))
#将当时前时间减10天
print(datetime.datetime.now()-datetime.timedelta(days=10))
#将当时前时间加10小时
print(datetime.datetime.now()-datetime.timedelta(hours=10))
#将当时前时间减10小时
print(datetime.datetime.now()-datetime.timedelta(hours=10))
#将当前时间返回值指定时间
# print(current_time.replace(2014,09))
判断时间大小:
#时间大小判断
kk = datetime.datetime.now() #答应当时间
print(kk)
print("-----------")
ww = kk.replace(2015,9) #将当前时间返回至201509
print(ww)
print("=====")
print(kk==ww) #如返回值是True,则两个时间相等,False:则不等
logging模块:
日志模块:python提供了标准的日志接口,常用日志级别有:debug(),info(),waring(),error() 和critical()五个级别。
日志级别大小:DEBUG()<INFO()<WARING()<ERROR()<CRITICAL()
将日志信息打印至文件:
import logging
#把日志级别info以上的日志信息存入example.log文件中
# logging.basicConfig(filename=‘example.log‘,level=logging.INFO)
#添加日志打印时间输出:按照月,天,年,时、分、秒输出,asctime占位符
logging.basicConfig(filename=‘example.log‘,level=logging.INFO,
format=‘%(asctime)s %(message)s‘,datefmt=‘%m/%d/%Y %I:%M:%S %p‘) #按照format将字符串进行拼接
logging.debug(‘This message should go to the log file‘)
logging.info(‘So should this‘)
logging.warning(‘And this, too‘)
%(asctime)s:时间
%(filename)s:将程序文件名写入日志文件中
%(lineno)d:显示日志行号
%(module)s:模块名
%(msecs)d:毫秒
%(pathname)s:路径
%(process)d:进程号
%(processName):进程名
%(thread)d:线程
日志输出格式详细地址:http://images2015.cnblogs.com/blog/425762/201605/425762-20160524044013866-178249755.png
import logging
#create logger
logger = logging.getLogger(‘TEST-LOG‘)#先获取logger对象
logger.setLevel(logging.DEBUG) #设置一个全局日志级别为debug,那么在往屏幕和文件输出日志时,不应比全局定义额日志级别低
# create console handler and set level to debug #handler输出至屏幕或则文件
ch = logging.StreamHandler() #把日志输出至屏幕 waring
ch.setLevel(logging.DEBUG) #把debug及超过bebug级别以上的日志信息,输出至屏幕
# create file handler and set level to warning
fh = logging.FileHandler("access.log") #把日志输出至文件
fh.setLevel(logging.WARNING) #把warning及超过warning级别以上的日志信息,输出至文件
fh_error = logging.FileHandler("error.log") #将出报错信息,打印至error.log文件
fh_error.setLevel(logging.ERROR) #设置错误信息级别为ERROR
# create formatter 创建日志输出格式 %(asctime)s:时间 %(filename)s:将程序文件名写入日志文件中
# %(lineno)d:显示日志行号 %(module)s:模块名 %(msecs)d:毫秒,%(pathname)s:路径,%(process)d:进程号
# %(processName):进程名 ,%(thread)d:线程
formatter = logging.Formatter(‘%(asctime)s - %(levelname)s - %(filename)s - %(lineno)s - %(thread)d - %(message)s‘)
formatter_for_file = logging.Formatter(‘%(asctime)s - %(filename)s - %(lineno)s - %(name)s - %(levelname)s - %(message)s‘)
# add formatter to ch and fh
ch.setFormatter(formatter) #ch屏幕
fh.setFormatter(formatter) #fh文件
fh_error.setFormatter(formatter) #fh文件
# add ch and fh to logger 定义日志输出的地方
logger.addHandler(ch) #指定日信息打印至屏幕
logger.addHandler(fh) #指定日信息打印至文件
logger.addHandler(fh_error) #指定日信息打印至文件
# ‘application‘ code
logger.debug(‘debug message‘)
logger.info(‘info message‘)
logger.warn(‘warn message‘)
logger.error(‘error message‘)
logger.critical(‘critical message‘)
继续完善中、、、、、
本节作业
作业需求:
模拟实现一个ATM + 购物商城程序
day_5装饰器、字符串格式化、序列化、内置模块、生成器、迭代器之篇】
标签:
原文地址:http://www.cnblogs.com/lcj0703/p/5561028.html
