标签:style blog http color 使用 strong io 数据
这章节介绍CUDA编程模型的主要的概念。
2.1.kernels(核函数)
CUDA C扩展了C语言,允许程序员定义C函数,称为kernels(核函数)。并行地在N个CUDA线程中执行N次。
使用__global__说明符声明一个核函数,调用使用<<<...>>>,并且指定执行的CUDA线程数目。执行的每个线程都有一个独一的ID,在核函数中可以通过变量threadIdx获取。
例子,两个向量的加,A加B,并把结果存入C,A、B和C的长度为N。
__global__ void addKernel(int *c, const int *a, const int *b) { int i = threadIdx.x; c[i] = a[i] + b[i]; } int main() { ... // Launch a kernel on the GPU with one thread for each element. addKernel<<<1, N>>>(c, a, b); ... }
其中,每一个线程都会在数组中的每个元素上执行addKernel这个核函数。
2.2.线程层次
threadIdx是一个3元组,因此线程可以被一维、二维和三维的threadIdx标识,形成一维、二维和三维的线程块。
线程的索引和ID之间的关系:对于一维的线程块,索引和ID是相同的;对于大小为(Dx,Dy)的二维的线程块,索引为(x,y),而ID为x+y*Dx;对于大小为(Dx,Dy,Dz)的三维线程块,索引为(x,y,z),ID为(x+y*Dx+z*Dx*Dy)。
例子,二维矩阵加,N*N大小的A和B相加,结果存入C。
// Kernel definition __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = threadIdx.x; int j = threadIdx.y; C[i][j] = A[i][j] + B[i][j]; } int main() { ... // Kernel invocation with one block of N * N * 1 threads int numBlocks = 1; dim3 threadsPerBlock(N, N); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ... }
其中,因为一个block的线程一般会在同一个处理核心中,并且共享有限的内存,所以一个块的线程的个数是有限制的。在当前的GPU,块中的线程数目最大为1024。
然而,一个核函数可以在多个相同大小的线程块中执行,所以总的线程数等于线程块的个数乘以每个线程块中线程的个数。
线程块被组织进一维、二维或者三维的grid中,如图6所示。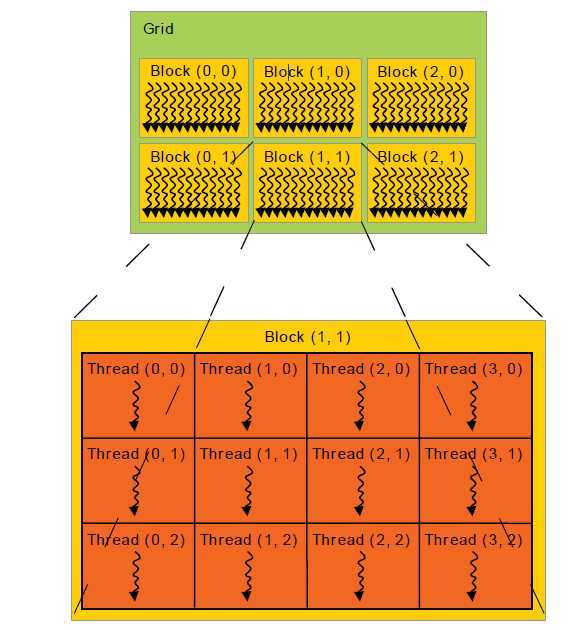
图6 拥有多个线程块的grid
调用核函数的时候,可以通过<<<...>>>指定每个线程块中线程的个数以及每个grid中线程块的个数,<<<...>>>的类型可以为int何dim3。核函数中可以通过内建的变量blockIdx得到grid中的每个线程块的索引。同时可以通过blockDim获得每个线程块的维数。
例子,扩展先前的矩阵加的例子为多个线程块的。
// Kernel definition __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; } int main() { ... // Kernel invocation dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ... }
其中,线程块的大小为16*16,总共有256个线程。在同一个线程块中线程可以通过shared memory(共享内存)共享数据。可以使用__syncthreads()函数同步线程对共享内存的数据访问。
2.3.内存层次
执行时,核函数可以获取多个内存空间中的数据,如图7所示。每个线程有自己的局部内存。每个线程块拥有共享内存空间,块中的每个线程都可以访问。还有执行核函数的每个线程都可以访问的全局内存空间。
另外,还有两个额外的只读的内存空间:常量和纹理内存空间。全局、常量和纹理内存空间为不同的内存用法做了最佳的优化。纹理模型提供多种的寻址方式。
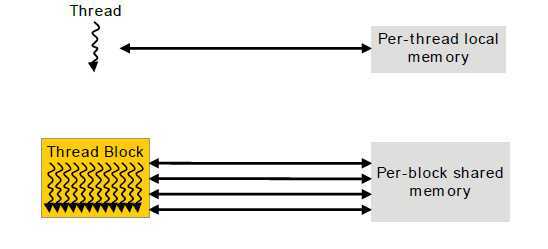
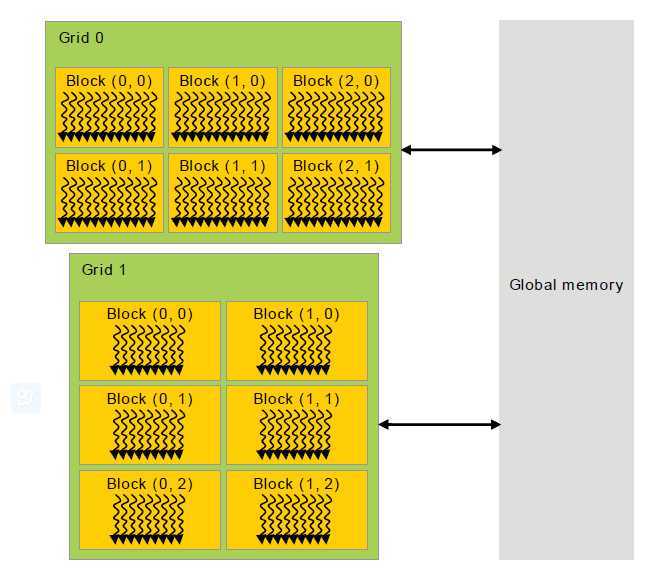
图7 内存层次
2.4.异构编程
如图8所示,CUDA编程模型假设CUDA线程执行在一个与主机的C程序分离的装置上。核函数在GPU上执行,而其他的在CPU上执行。CUDA编程模型同时假设主机和设备独立操作它们在DRAM中的内存空间。因此,程序调用CUDA运行时(在编程接口这一章描述)管理全局、常量和纹理内存空间对核函数的访问性,运行时包括内存分配和回收、主机和设备之间的内存数据的拷贝等。
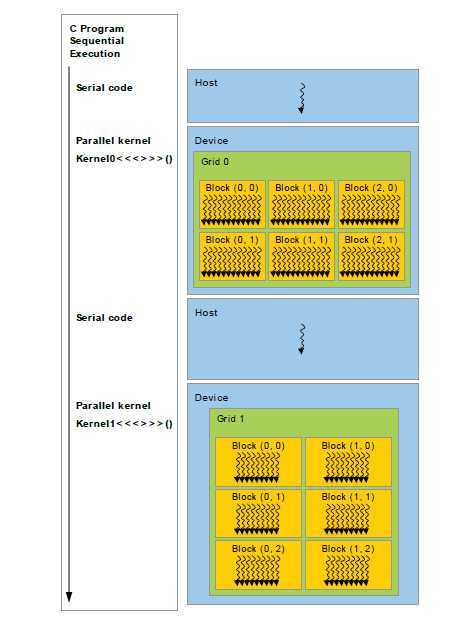
在主机上执行串行的代码,而GPU执行并行的核函数
图8 异构编程
2.5.计算能力
设备的计算能力定义为一个主版本号和一个次的修订号。
相同的主版本号的GPU拥有相同的核心架构。主版号为5的是Maxwell架构,3为Kepler架构,2为Fermi架构,1为Tesla架构。
次修订号相当于核的不断改进和新的特性。
支持CUDA的GPU这一章节列出支持CUDA的所有GPU的计算能力。计算能力这一章节给出每个计算能力的详细技术规格。
CUDA C编程入门-编程模型,布布扣,bubuko.com
标签:style blog http color 使用 strong io 数据
原文地址:http://www.cnblogs.com/zjwzcnjsy/p/3888851.html