Scrapy,Python开发的一个web抓取框架。
1,引言
Python即时网络爬虫启动的目标是一起把互联网变成大数据库。单纯的开放源代码并不是开源的全部,开源的核心是“开放的思想”,聚合最好的想法、技术、人员,所以将会参照众多领先产品,比如,Scrapy,ScrapingHub,Import.io等。
本文简单讲解一下Scrapy的架构。没错,通用提取器gsExtractor就是要集成到Scrapy架构中。
请注意,本文不想复述原文内容,而是为了开源Python爬虫的发展方向找参照,而且以9年来开发网络爬虫经验作为对标,从而本文含有不少笔者主观评述,如果想读Scrapy官方原文,请点击Scrapy官网的Architecture。
2,Scrapy架构图
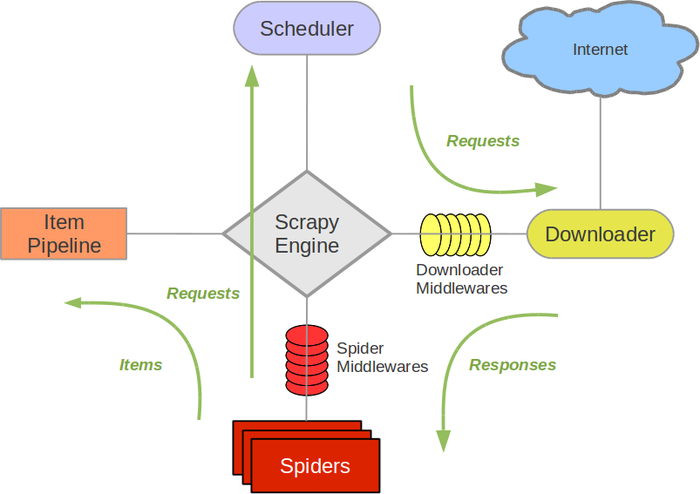
Spiders就是针对特定目标网站编写的内容提取器,这是在通用网络爬虫框架中最需要定制的部分。使用Scrapy创建一个爬虫工程的时候,就会生成一个Spider架子,只需往里面填写代码,按照它的运行模式填写,就能融入Scrapy整体的数据流中。Python即时网络爬虫开源项目的目标是节省下程序员一半以上的时间,关键就是提高Spider的定义和测试速度,解决方案参看1分钟快速生成网页内容提取器,让整个Scrapy爬虫系统实现快速定制的目标。
3,Scrapy的数据流(Data Flow)
Scrapy中的数据流由执行引擎控制,下面的原文摘自Scrapy官网,我根据猜测做了点评,为进一步开发GooSeeker开源爬虫指示方向:
The Engine gets the first URLs to crawl from the Spider and schedules them in the Scheduler, as Requests.
URL谁来准备呢?看样子是Spider自己来准备,那么可以猜测Scrapy架构部分(不包括Spider)主要做事件调度,不管网址的存储。看起来类似GooSeeker会员中心的爬虫罗盘,为目标网站准备一批网址,放在罗盘中准备执行爬虫调度操作。所以,这个开源项目的下一个目标是把URL的管理放在一个集中的调度库里面。
The Engine asks the Scheduler for the next URLs to crawl.
看到这里其实挺难理解的,要看一些其他文档才能理解透。接第1点,引擎从Spider中把网址拿到以后,封装成一个Request,交给了事件循环,会被Scheduler收来做调度管理的,暂且理解成对Request做排队。引擎现在就找Scheduler要接下来要下载的网页地址。
The Scheduler returns the next URLs to crawl to the Engine and the Engine sends them to the Downloader, passing through the Downloader Middleware (request direction).
从调度器申请任务,把申请到的任务交给下载器,在下载器和引擎之间有个下载器中间件,这是作为一个开发框架的必备亮点,开发者可以在这里进行一些定制化扩展。
Once the page finishes downloading the Downloader generates a Response (with that page) and sends it to the Engine, passing through the Downloader Middleware (response direction).
下载完成了,产生一个Response,通过下载器中间件交给引擎。注意,Response和前面的Request的首字母都是大写,虽然我还没有看其它Scrapy文档,但是我猜测这是Scrapy框架内部的事件对象,也可以推测出是一个异步的事件驱动的引擎,就像DS打数机的三级事件循环一样,对于高性能、低开销引擎来说,这是必须的。
The Engine receives the Response from the Downloader and sends it to the Spider for processing, passing through the Spider Middleware (input direction).
再次出现一个中间件,给开发者足够的发挥空间。
The Spider processes the Response and returns scraped items and new Requests (to follow) to the Engine.
每个Spider顺序抓取一个个网页,完成一个就构造另一个Request事件,开始另一个网页的抓取。
The Engine passes scraped items and new Requests returned by a spider through Spider Middleware (output direction), and then sends processed items to Item Pipelines and processed Requests to the Scheduler.
引擎作事件分发。
The process repeats (from step 1) until there are no more requests from the Scheduler.
持续不断地运行。
4,接下来的工作
接下来,我们将进一步研读Scrapy的文档,实现Python即时网络爬虫与Scrapy的集成。
5,文档修改历史
2016-06-11:V1.0,首次发布
本文出自 “fullerhua的博客” 博客,谢绝转载!
原文地址:http://gooseeker.blog.51cto.com/11579528/1788037