标签:
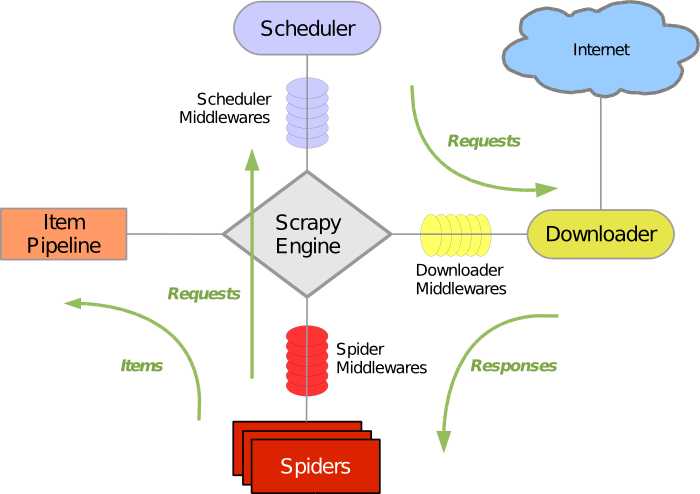
第一点前提,要看了解这张图首先要知道每个不见的含义
第二就是他们之间有什么工作关系
------引擎-------ScrapyEngine -------Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发。
--------------------我的理解就是整个scrapy的 发动机,核心,心脏,大脑,CPU,中转站.......起到连接整个流程的作用,跟代码无关。其实我们主要工作的地方是spider文件夹里面的蜘蛛文件。果然写一写有助于记忆,是不是牛B了就不写了....期待牛B的那一天
-------调度------Scheduler---------(调度程序)...从Scrapy引擎接受请求并排序列入队列,并在Scrapy引擎发出请求后返还给他们。
-----------------------------我的理解是指挥官,引擎从-->蜘蛛那里获得网址——>引擎-->放到调度里面排队,检查是否符合他的要求-->然后....我接着介绍--¥¥¥(其实这个调度也不用我们太操心)
-------Downloader(下载器)--------下载器的主要职责是抓取网页并将网页内容返还给蜘蛛( Spiders)。
--------------------------------------------@然后调度把符合要求的网址-----》发送到下载器-----》获得网页数据
---------spider----(蜘蛛侠)----其实他只是个筛选网页数据的工人,而这个工人是由我们控制的机器蜘蛛虾。-------数据在此进行筛选,并且将结果放到
-----------Item Pipeline(项目管道)---好吧这个名字....就是个管子....吸管..通道....将想要的结果通过这里传到数据库或者保存为文件。我们在这里编写存放结果方法的管子
Downloader middlewares(下载器中间件)
下载中间件是位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。它提供了一个自定义的代码的方式来拓展Scrapy的功能。下载中间器是一个处理请求和响应的钩子框架。他是轻量级的,对Scrapy尽享全局控制的底层的系统。
Spider middlewares(蜘蛛中间件)
蜘蛛中间件是介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。它提供一个自定义代码的方式来拓展Scrapy的功能。蛛中间件是一个挂接到Scrapy的蜘蛛处理机制的框架,你可以插入自定义的代码来处理发送给蜘蛛的请求和返回蜘蛛获取的响应内容和项目。
Scheduler middlewares(调度中间件)
调度中间件是介于Scrapy引擎和调度之间的中间件,主要工作是处从Scrapy引擎发送到调度的请求和响应。他提供了一个自定义的代码来拓展Scrapy的功能。
中间件。。。我不是很理解......感觉...没太深入http://blog.csdn.net/frylion/article/details/8558538 他这里写的比较完整嘿嘿我这个是粗糙版
数据处理流程...加粗
Scrapy的整个数据处理流程有Scrapy引擎进行控制,其主要的运行方式为:
标签:
原文地址:http://www.cnblogs.com/zsl-3/p/5582139.html