标签:
由于HTTP协议是无状态的,而服务器端的业务必须是要有状态的。Cookie诞生的最初目的是为了存储web中的状态信息,以方便服务器端使用。比如判断用户是否是第一次访问网站。目前最新的规范是RFC 6265,它是一个由浏览器服务器共同协作实现的规范。
Cookie的处理分为:
服务器端像客户端发送Cookie是通过HTTP响应报文实现的,在Set-Cookie中设置需要像客户端发送的cookie,cookie格式如下:
Set-Cookie: "name=value;domain=.domain.com;path=/;expires=Sat, 11 Jun 2016 11:29:42 GMT;HttpOnly;secure"其中name=value是必选项,其它都是可选项。Cookie的主要构成如下:
最好为cookie的name和value进行url编码如果客户端和服务器端时间不一致,使用expires就会存在偏差。document.cookie去更改这个值,同样这个值在document.cookie中也不可见。但在http请求张仍然会携带这个cookie。注意这个值虽然在脚本中不可获取,但仍然在浏览器安装目录中以文件形式存在。这项设置通常在服务器端设置。就算设置了secure 属性也并不代表他人不能看到你机器本地保存的 cookie 信息,所以不要把重要信息放cookie就对了var http = require(‘http‘);
var fs = require(‘fs‘);
http.createServer(function(req, res) {
res.setHeader(‘status‘, ‘200 OK‘);
res.setHeader(‘Set-Cookie‘, ‘isVisit=true;domain=.yourdomain.com;path=/;max-age=1000‘);
res.write(‘Hello World‘);
res.end();
}).listen(8888);
console.log(‘running localhost:8888‘)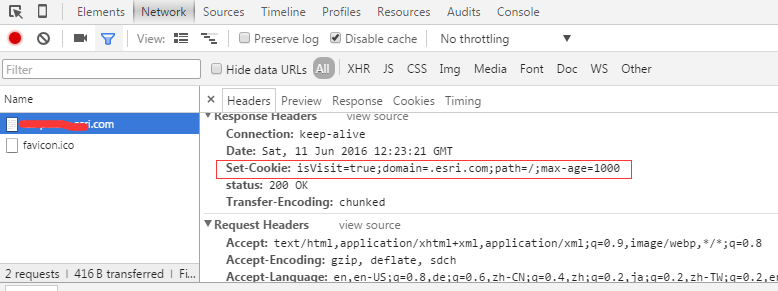
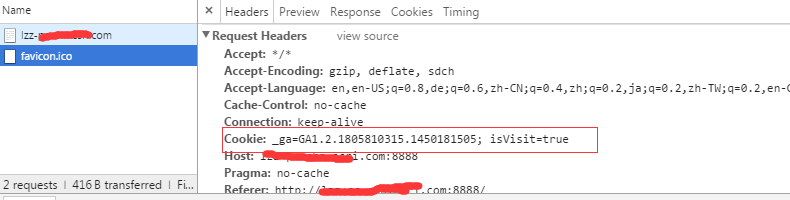
直接设置Set-Cookie过于原始,我们可以对cookie的设置过程做如下封装:
var serilize = function(name, val, options) {
if (!name) {
throw new Error("coolie must have name");
}
var enc = encodeURIComponent;
var parts = [];
val = (val !== null && val !== undefined) ? val.toString() : "";
options = options || {};
parts.push(enc(name) + "=" + enc(val));
// domain中必须包含两个点号
if (options.domain) {
parts.push("domain=" + options.domain);
}
if (options.path) {
parts.push("path=" + options.path);
}
// 如果不设置expires和max-age浏览器会在页面关闭时清空cookie
if (options.expires) {
parts.push("expires=" + options.expires.toGMTString());
}
if (options.maxAge && typeof options.maxAge === "number") {
parts.push("max-age=" + options.maxAge);
}
if (options.httpOnly) {
parts.push("HTTPOnly");
}
if (options.secure) {
parts.push("secure");
}
return parts.join(";");
}需要注意的是,如果给cookie设置一个过去的时间,浏览器会立即删除该cookie;此外domain项必须有两个点,因此不能设置为localhost:
something that wasn‘t made clear to me here and totally confused me for a while was that domain names must contain at least two dots (.),hence ‘localhost‘ is invalid and the browser will refuse to set the cookie!
cookie可以设置不同的域与路径,所以对于同一个name value,在不同域不同路径下是可以重复的,浏览器会按照与当前请求url或页面地址最佳匹配的顺序来排定先后顺序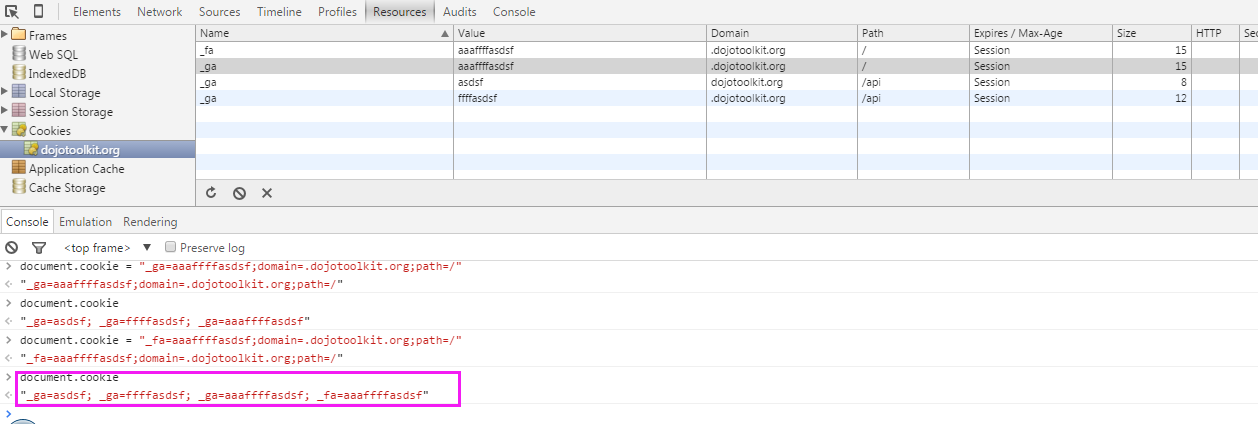
所以当前端传递到服务器端的cookie有多个重复name value时,我们只需要最匹配的那个,也就是第一个。服务器端解析代码如下:
var parse = function(cstr) {
if (!cstr) {
return null;
}
var dec = decodeURIComponent;
var cookies = {};
var parts = cstr.split(/\s*;\s*/g);
parts.forEach(function(p){
var pos = p.indexOf(‘=‘);
// name 与value存入cookie之前,必须经过编码
var name = pos > -1 ? dec(p.substr(0, pos)) : p;
var val = pos > -1 ? dec(p.substr(pos + 1)) : null;
//只需要拿到最匹配的那个
if (!cookies.hasOwnProperty(name)) {
cookies[name] = val;
}/* else if (!cookies[name] instanceof Array) {
cookies[name] = [cookies[name]].push(val);
} else {
cookies[name].push(val);
}*/
});
return cookies;
}浏览器将后台传递过来的cookie进行管理,并且允许开发者在JavaScript中使用document.cookie来存取cookie。但是这个接口使用起来非常蹩脚。它会因为使用它的方式不同而表现出不同的行为。
当用来获取属性值时,document.cookie返回当前页面可用的(根据cookie的域、路径、失效时间和安全设置)所有的字符串,字符串的格式如下:
"name1=value1;name2=value2;name3=value3";当用来设置值的时候,document.cookie属性可设置为一个新的cookie字符串。这个字符串会被解释并添加到现有的cookie集合中。如:
document.cookie = "_fa=aaaffffasdsf;domain=.dojotoolkit.org;path=/"设置document.cookie并不会覆盖cookie,除非设置的name value domain path都与一个已存在cookie重复。
由于cookie的读写非常不方便,我们可以自己封装一些函数来处理cookie,主要是针对cookie的添加、修改、删除。
var cookieUtils = {
get: function(name){
var cookieName=encodeURIComponent(name) + "=";
//只取得最匹配的name,value
var cookieStart = document.cookie.indexOf(cookieName);
var cookieValue = null;
if (cookieStart > -1) {
// 从cookieStart算起
var cookieEnd = document.cookie.indexOf(‘;‘, cookieStart);
//从=后面开始
if (cookieEnd > -1) {
cookieValue = decodeURIComponent(document.cookie.substring(cookieStart + cookieName.length, cookieEnd));
} else {
cookieValue = decodeURIComponent(document.cookie.substring(cookieStart + cookieName.length, document.cookie.length));
}
}
return cookieValue;
},
set: function(name, val, options) {
if (!name) {
throw new Error("coolie must have name");
}
var enc = encodeURIComponent;
var parts = [];
val = (val !== null && val !== undefined) ? val.toString() : "";
options = options || {};
parts.push(enc(name) + "=" + enc(val));
// domain中必须包含两个点号
if (options.domain) {
parts.push("domain=" + options.domain);
}
if (options.path) {
parts.push("path=" + options.path);
}
// 如果不设置expires和max-age浏览器会在页面关闭时清空cookie
if (options.expires) {
parts.push("expires=" + options.expires.toGMTString());
}
if (options.maxAge && typeof options.maxAge === "number") {
parts.push("max-age=" + options.maxAge);
}
if (options.httpOnly) {
parts.push("HTTPOnly");
}
if (options.secure) {
parts.push("secure");
}
document.cookie = parts.join(";");
},
delete: function(name, options) {
options.expires = new Date(0);// 设置为过去日期
this.set(name, null, options);
}
}
缓存优点
通常所说的Web缓存指的是可以自动保存常见http请求副本的http设备。对于前端开发者来说,浏览器充当了重要角色。除此外常见的还有各种各样的代理服务器也可以做缓存。当Web请求到达缓存时,缓存从本地副本中提取这个副本内容而不需要经过服务器。这带来了以下优点:
缓存可以是单个用户专用的,也可以是多个用户共享的。专用缓存被称为私有缓存,共享的缓存被称为公有缓存。
私有缓存只针对专有用户,所以不需要很大空间,廉价。Web浏览器中有内建的私有缓存——大多数浏览器都会将常用资源缓存在你的个人电脑的磁盘和内存中。如Chrome浏览器的缓存存放位置就在:C:\Users\Your_Account\AppData\Local\Google\Chrome\User Data\Default中的Cache文件夹和Media Cache文件夹。
公有缓存是特殊的共享代理服务器,被称为缓存代理服务器或代理缓存(反向代理的一种用途)。公有缓存会接受来自多个用户的访问,所以通过它能够更好的减少冗余流量。
下图中每个客户端都会重复的向服务器访问一个资源(此时还不在私有缓存中),这样它会多次访问服务器,增加服务器压力。而使用共享的公有缓存时,缓存只需要从服务器取一次,以后不用再经过服务器,能够显著减轻服务器压力。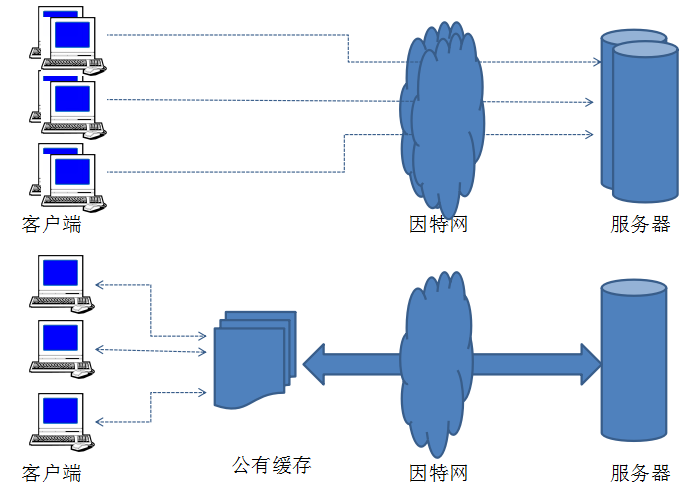
事实上在实际应用中通常采用层次化的公有缓存,基本思想是在靠近客户端的地方使用小型廉价缓存,而更高层次中,则逐步采用更大、功能更强的缓存在装载多用户共享的资源。
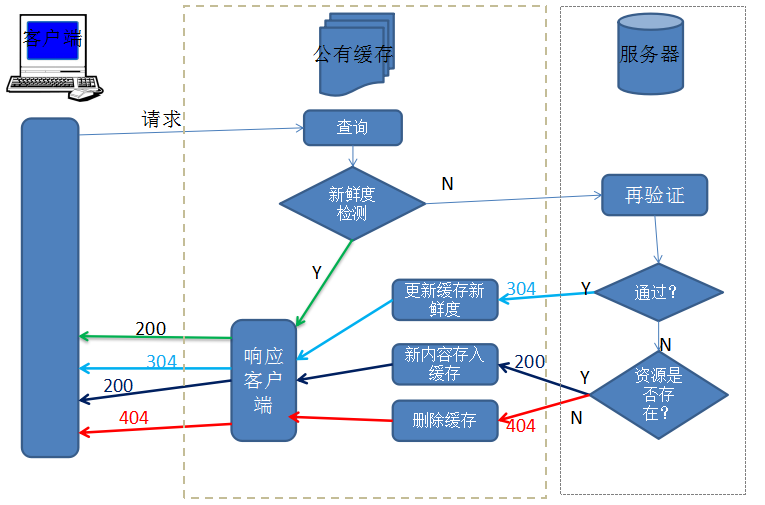
而对于前端开发者来说,我们主要跟浏览器中的缓存打交道,所以上图流程简化为: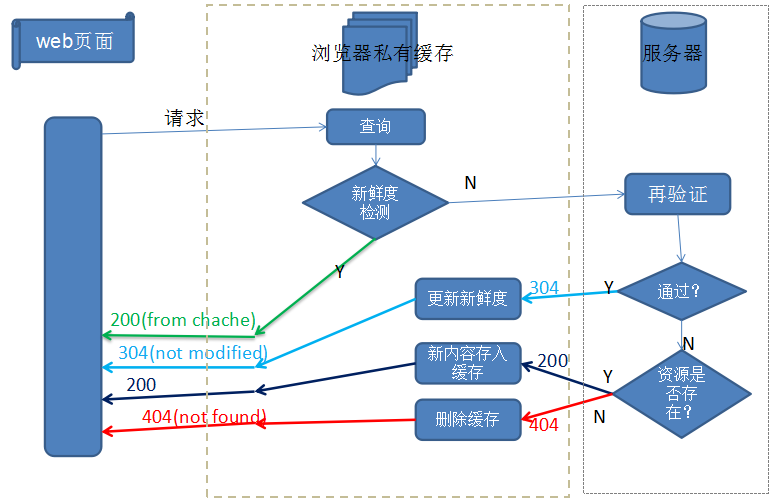
下面这张图展示了某一网站,对不同资源的请求结果,其中可以看到有的资源直接从缓存中读取,有的资源跟服务器进行了再验证,有的资源重新从服务器端获取。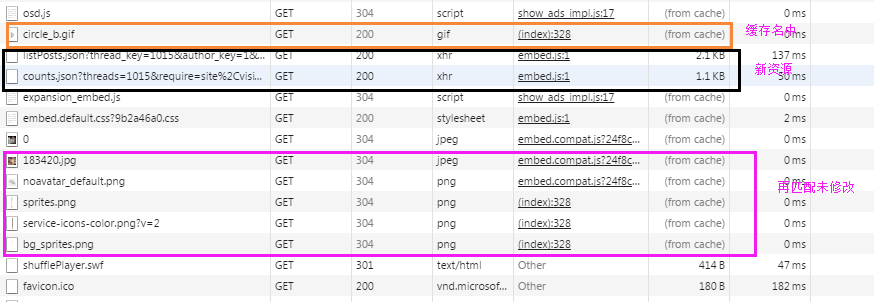
注意,我们讨论的所有关于缓存资源的问题,都仅仅针对GET请求。而对于POST, DELETE, PUT这类行为性操作通常不做任何缓存
HTTP通过缓存将服务器资源的副本保留一段时间,这段时间称为新鲜度限值。这在一段时间内请求相同资源不会再通过服务器。HTTP协议中Cache-Control和 Expires可以用来设置新鲜度的限值,前者是HTTP1.1中新增的响应头,后者是HTTP1.0中的响应头。二者所做的事时都是相同的,但由于Cache-Control使用的是相对时间,而Expires可能存在客户端与服务器端时间不一样的问题,所以我们更倾向于选择Cache-Control。
下面我们来看看Cache-Control都可以设置哪些属性值:
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no" />
<meta http-equiv="X-UA-Compatible" content="IE=EDGE" />
<title>Web Cache</title>
<link rel="shortcut icon" href="./shortcut.png">
<script>
</script>
</head>
<body class="claro">
<img src="./cache.png">
</body>
</html>var http = require(‘http‘);
var fs = require(‘fs‘);
http.createServer(function(req, res) {
if (req.url === ‘/‘ || req.url === ‘‘ || req.url === ‘/index.html‘) {
fs.readFile(‘./index.html‘, function(err, file) {
console.log(req.url)
//对主文档设置缓存,无效果
res.setHeader(‘Cache-Control‘, "no-cache, max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘text/html‘);
res.writeHead(‘200‘, "OK");
res.end(file);
});
}
if (req.url === ‘/cache.png‘) {
fs.readFile(‘./cache.png‘, function(err, file) {
res.setHeader(‘Cache-Control‘, "max-age=" + 5);//缓存五秒
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.writeHead(‘200‘, "Not Modified");
res.end(file);
});
}
}).listen(8888)当在5秒内第二次访问页面时,浏览器会直接从缓存中取得资源
no-cache 表示必须先与服务器确认资源是否被更改过(依靠If-None-Match和Etag),然后再决定是否使用本地缓存。
如果上文中关于cache.png的处理改成下面这样,则每次访问页面,浏览器都需要先去服务器端验证资源有没有被更改。
fs.readFile(‘./cache.png‘, function(err, file) {
console.log(req.headers);
console.log(req.url)
if (!req.headers[‘if-none-match‘]) {
res.setHeader(‘Cache-Control‘, "no-cache, max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.setHeader(‘Etag‘, "ffff");
res.writeHead(‘200‘, "Not Modified");
res.end(file);
} else {
if (req.headers[‘if-none-match‘] === ‘ffff‘) {
res.writeHead(‘304‘, "Not Modified");
res.end();
} else {
res.setHeader(‘Cache-Control‘, "max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.setHeader(‘Etag‘, "ffff");
res.writeHead(‘200‘, "Not Modified");
res.end(file);
}
}
});
no-store 绝对禁止缓存任何资源,也就是说每次用户请求资源时,都会向服务器发送一个请求,每次都会下载完整的资源。通常用于机密性资源。
关于Cache-Control的使用,见下面这张图(来自大额)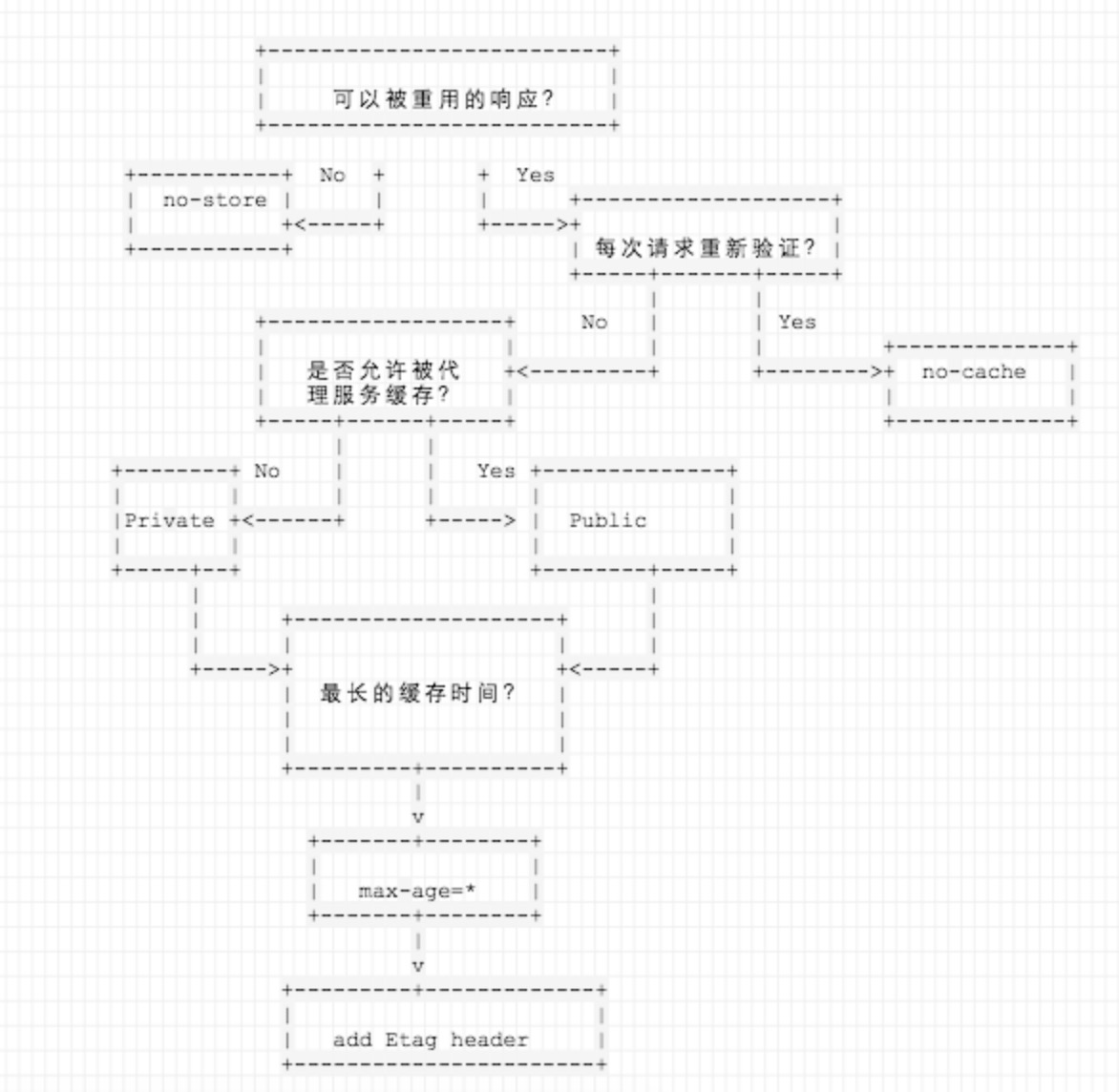
Cache-Control不仅仅可以在响应头中设置,还可以在请求头中设置。浏览器通过请求头中设置Cache-Control可以决定是否从缓存中读取资源。这也是为什么有时候点击浏览器刷新按钮和在地址栏回车,在NetWork模块中看到完全不同的结果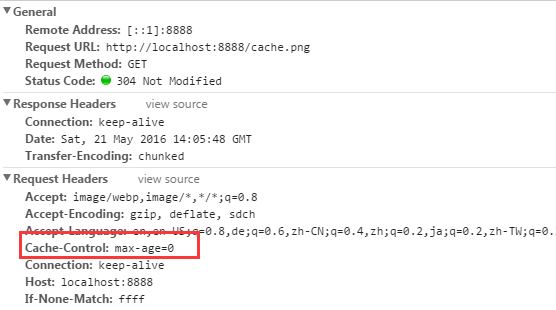
不推荐使用Expires,它指定的是具体的过期日期而不是秒数。因为很多服务器跟客户端存在时钟不一致的情况,所以最好还是使用Cache-Control.
浏览器或代理缓存中缓存的资源过期了,并不意味着它和原始服务器上的资源有实际的差异,仅仅意味着到了要进行核对的时间了。这种情况被称为服务器再验证。
If-None-Match/Etag,在HTTP1.0中则使用If-Modified-Since/Last-Modified。根据实体内容生成一段hash字符串,标识资源的状态,由服务端产生。浏览器会将这串字符串传回服务器,验证资源是否已经修改,如果没有修改,过程如下(图片来自浅谈Web缓存):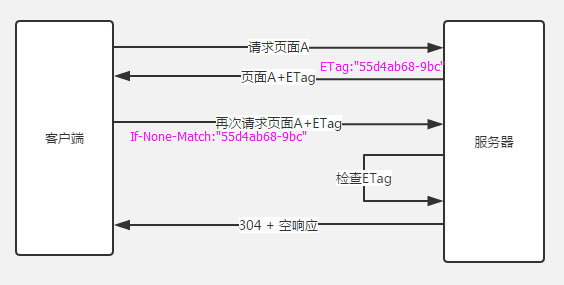
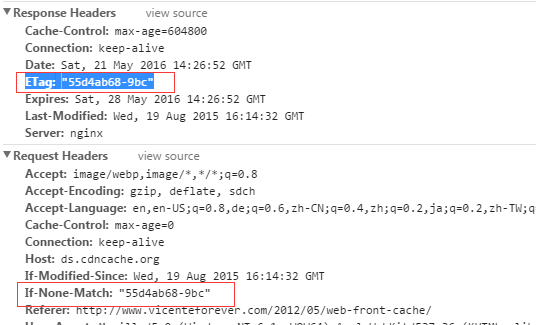
上文的demo中我们见到过服务器端如何验证Etag: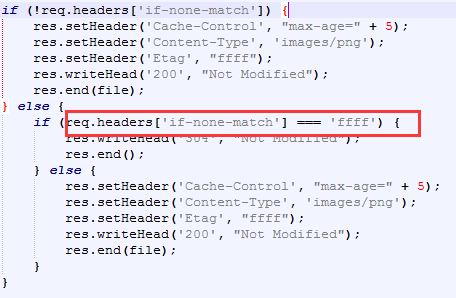
由于Etag有服务器构造,所以在集群环境中一定要保证Etag的唯一性
这两个是HTTP1.0中用来验证资源是否过期的请求/响应头,这两个头部都是日期,验证过程与Etag类似,这里不详细介绍。使用这两个头部来验证资源是否更新时,存在以下问题:
If-Modified-Since不相同,导致不必要的响应。关于缓存的更新问题,请大家看看这里张云龙的回答,本文就不详细展开了。
本文demo代码如下:
<!DOCTYPE HTML>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0, maximum-scale=1.0, user-scalable=no" />
<meta http-equiv="X-UA-Compatible" content="IE=EDGE" />
<title>Web Cache</title>
<link rel="shortcut icon" href="./shortcut.png">
<script>
</script>
</head>
<body class="claro">
<img src="./cache.png">
</body>
</html>var http = require(‘http‘);
var fs = require(‘fs‘);
http.createServer(function(req, res) {
if (req.url === ‘/‘ || req.url === ‘‘ || req.url === ‘/index.html‘) {
fs.readFile(‘./index.html‘, function(err, file) {
console.log(req.url)
//对主文档设置缓存,无效果
res.setHeader(‘Cache-Control‘, "no-cache, max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘text/html‘);
res.writeHead(‘200‘, "OK");
res.end(file);
});
}
if (req.url === ‘/shortcut.png‘) {
fs.readFile(‘./shortcut.png‘, function(err, file) {
console.log(req.url)
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.writeHead(‘200‘, "OK");
res.end(file);
})
}
if (req.url === ‘/cache.png‘) {
fs.readFile(‘./cache.png‘, function(err, file) {
console.log(req.headers);
console.log(req.url)
if (!req.headers[‘if-none-match‘]) {
res.setHeader(‘Cache-Control‘, "max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.setHeader(‘Etag‘, "ffff");
res.writeHead(‘200‘, "Not Modified");
res.end(file);
} else {
if (req.headers[‘if-none-match‘] === ‘ffff‘) {
res.writeHead(‘304‘, "Not Modified");
res.end();
} else {
res.setHeader(‘Cache-Control‘, "max-age=" + 5);
res.setHeader(‘Content-Type‘, ‘images/png‘);
res.setHeader(‘Etag‘, "ffff");
res.writeHead(‘200‘, "Not Modified");
res.end(file);
}
}
});
}
}).listen(8888)标签:
原文地址:http://blog.csdn.net/libin_1/article/details/51668974