标签:

1、回归的多面性
(1)OLS回归的使用情境
OLS回归是通过预测变量(即解释变量)的加权和来预测量化的因变量(即响应变量),其中权重是通过数据估计而得的参数。
2、OLS回归
OLS回归拟合模型的形式:

(1)用lm()拟合回归模型:



画真实样本和拟合曲线的图用到的函数:
abline()
lines()
(2)简单线性回归
fit<-lm(weight~height,data=women)
plot(women$height,women$weight)
abline(fit)
(3)多项式回归
形式:y=a+b1x+b2x^2+b3x^3
fit2<-lm(weight~height+I(height^2),data=women)
plot(women$height,women$weight)
lines(women$height,fitted(fit2))

car包中的scatterplot()函数,可以很容易、方便地绘制二元关系图。既提供了身高与体重的散点图、线性拟合曲线和平滑拟合(loess)曲线,还在相应边界展示了每个变量的箱线图。可以借此发现拟合线性or多项式回归更合适。
(4)多元线性回归
因为lm()函数需要一个数据框(state.x77数据集是矩阵),所以要对对象使用as.data.frame()函数进行转化。
多元回归分析中,第一步最好检查一下变量间(包括解释变量和被解释变量)的相关性。cor()函数提供了二变量之间的相关系数,car包中scatterplotMatrix()函数则会生成散点图矩阵。
(5)有交互项的多元线性回归

3、回归诊断
使用lm()函数拟合OLS回归模型,依赖于模型满足在多OLS模型统计假设。summary()函数对模型有了整体的描述,但是它没有提供关于模型在多大程度上满足统计假设的任何信息。所以下面要进行回归诊断。
(1)标准方法
R基础安装中提供了大量检验回归分析中统计假设的方法。最常见的方法就是对lm()函数返回的对象使用plot()函数,可以生成评价模型拟合情况的四幅图形。
OLS回归的统计假设:
*正态性。当预测变量值固定时,因变量呈正态分布,则残差也应该是一个均值为0的正态分布。正态QQ图是在正态分布对应的值下标准化残差的概率图。若满足正态分布,则图上的点应该落在呈45度角的直线上。
*独立性。因变量值间相互独立(或残差间相互独立),从这四张图中无法辨别,可从收集的数据中验证。
*线性。在这叫线性有些片面。如果建立的OLS回归模型拟合的好,那么残差值与模型拟合值不具有相关性。也就是说模型把提取了全部信息,剩下的残差是一个白噪声。在“残差图与拟合图”(Residuals vs Fitted)图中查看。
*同方差性。因变量的方差不会随着自变量的变化而变化。若满足同方差性的假设,在位置尺度图(scale-Location Graph)中水平线周围的点应该随机分布。
第四幅图:残差与杠杆图(Residuals vs Leverage)提供了你可能关注的单个观测点的信息。离群点、高杠杆值点和强影响点。

(2)改进的方法

*正态性:
以下2种方法检验残差的正态性。
car包的qqPlot()函数画出了n-p-1个自由度的t分布下的学生化残差图
residplot()函数生成学生化残差柱状图,并添加正态曲线、核密度曲线、轴须图。
*误差的独立性:即检验误差的自相关性
DW检验
car包提供的durbinWatsonTest()函数检验误差的序列相关性。
*线性:
通过成分残差图(component plus residual plot)也称偏残差图(partial residual plot),你可以看看因变量与各个自变量之间是否呈非线性关系,也可以看看是否有不同于已设定线性模型的系统偏差(若图形存在非线性,则说明你可能对预测变量的函数形式建模不够充分,那么就需要添加一些曲线成分),图形可用car包中的crPlots()函数绘制。
*同方差性:
判断误差方差是否恒定,car包提供2个函数。
ncvTest()函数生成一个计分检验,零假设为误差方差不变,备择假设为误差方差随着拟合值水平的变化而变化。
spreadLevelPlot()函数创建一个添加了最佳拟合曲线的散点图,展示标准化残差绝对值与拟合值的关系。
如果存在异方差,则建议幂次变换(suggested power transformation)。其含义是,经过p次幂(Y p)变换,非恒定的误差方差将会平稳。例如,若图形显示出了非水平趋势,建议幂次转换为0.5,在回归等式中用根号Y 代替Y,可能会使模型满足同方差性。
(3)线性模型假设的综合验证
gvlma包中的gvlma()函数能对线性模型假设进行综合验证,同时还能做偏斜度、峰度和异方差性的评价。换句话说,它给模型假设提供了一个单独的综合检验(通过/不通过)。如果没有通过,则使用前面的方法来判断哪些假设没有被满足。
(4)多重共线性
对于多元回归要检测解释变量间是否存在相关性。
情境:当F检验显著,但解释变量的回归系数不显著,则考虑是否存在多重共线性。
回归系数测量的是当其他预测变量不变时,某个预测变量对响应变量的影响。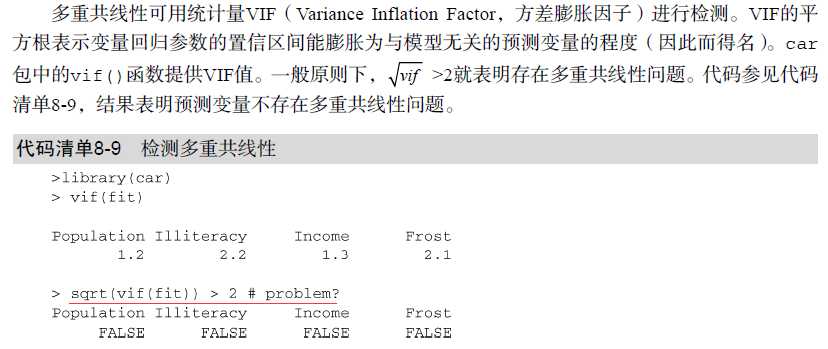
4、异常观测值
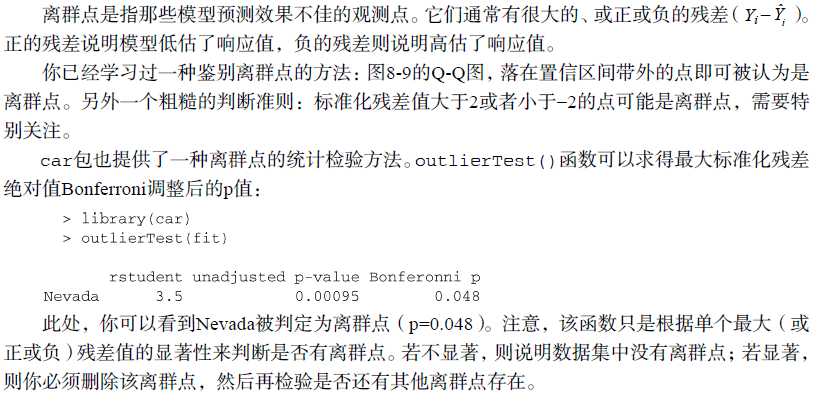
(1)离群点
(2)高杠杆值点
高杠杆值观测点,即是与其他预测变量有关的离群点。换句话说,它们是由许多异常的预测变量值组合起来的,与响应变量值没有关系。
高杠杆值的观测点可通过帽子统计量(hat statistic)判断。对于一个给定的数据集,帽子均值为p/n,其中p 是模型估计的参数数目(包含截距项),n 是样本量。一般来说,若观测点的帽子值大于帽子均值的2或3倍,即可以认定为高杠杆值点。
hatvalues()函数
高杠杆值点可能会是强影响点,也可能不是,这要看它们是否是离群点。
(3)强影响点
强影响点,即对模型参数估计值影响有些比例失衡的点。
有两种方法可以检测强影响点:Cook距离,或称D统计量,以及变量添加图(added variable plot)。一般来说,Cook’s D值大于4/(n?k ?1),则表明它是强影响点,其中n 为样本量大小,k 是预测变量数目。
未读
5、改进措施

(1)删除观测点
谨慎操作
(2)变量变换
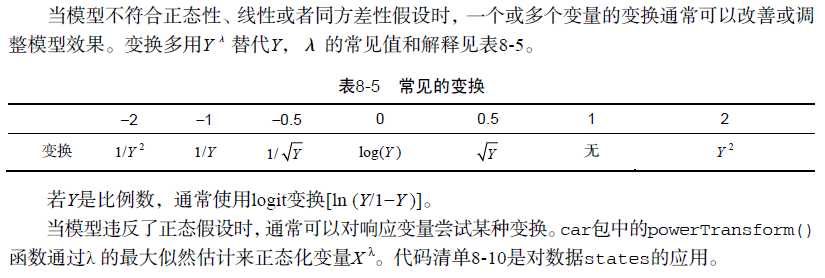
当违反了线性假设时,对预测变量进行变换常常会比较有用。car包中的boxTidwell()函数通过获得预测变量幂数的最大似然估计来改善线性关系。
响应变量变换还能改善异方差性(误差方差非恒定)你可以看到car包中spreadLevelPlot()函数提供的幂次变换应用。
(3)增删变量

(4)尝试其他方法

6、选择“最佳”的回归模型
模型没有最佳,根据工作者实际评判。最终回归模型的选择是会涉及预测精度(模型拟合优度)与模型简洁度的调和问题。
(1)模型的比较
方法一:用基础安装中的anova()函数可以比较两个嵌套模型的拟合优度。所谓嵌套模型,即它的一些项完全包含在另一个模型中。
方法二:AIC(Akaike Information Criterion,赤池信息准则)也可以用来比较模型,它考虑了模型的统计拟合度以及用来拟合的参数数目。AIC值越小的模型要优先选择,它说明模型用较少的参数获得了足够的拟合度。
(2)变量选择
从大量候选变量中选择最终的预测变量有以下两种流行的方法:逐步回归法(stepwisemethod)和全子集回归(all-subsets regression)。
*逐步回归

结果中的<none>中的AIC值表示没有变量被删除时模型的AIC。
缺点:逐步回归可能不能评价所有可能的模型,所以最终找到的好的模型不一定是最佳模型。所以产生了全子集回归法。
*全子集回归
方法一:

方法二:
Mallows Cp统计量也用来作为逐步回归的判停规则。广泛研究表明,对于一个好的模型,它的Cp统计量非常接近于模型的参数数目(包括截距项)。
用car包中的subsets()函数绘制。
大部分情况中,全子集回归要优于逐步回归,因为考虑了更多模型。但是,当有大量预测变量时,全子集回归会很慢。一般来说,变量自动选择应该被看做是对模型选择的一种辅助方法,而不是直接方法。拟合效果佳而没有意义的模型对你毫无帮助,主题背景知识的理解才能最终指引你获得理想的模型。
7、深层次分析
介绍评价模型泛化能力和变量相对重要性的方法。
(1)交叉验证
通过交叉验证法,我们评价回归方程的泛化能力。即:回归方程对新观测样本预测表现如何。
所谓交叉验证,即将一定比例的数据挑选出来作为训练样本,另外的样本作保留样本,先在训练样本上获取回归方程,然后在保留样本上做预测。由于保留样本不涉及模型参数的选择,该样本可获得比新数据更为精确的估计。
(2)相对重要性
哪个解释变量对预测最重要
若预测变量不相关,过程就相对简单得多,你可以根据预测变量与响应变量的相关系数来进行排序。但大部分情况中,预测变量之间有一定相关性,这就使得评价变得复杂很多。
方法一:
最简单的莫过于比较标准化的回归系数,它表示当其他预测变量不变时,该预测变量一个标准差的变化可引起的响应变量的预期变化(以标准差单位度量)。在进行回归分析前,可用scale()函数将数据标准化为均值为0、标准差为1的数据集,这样用R回归即可获得标准化的回归系数。(注意,scale()函数返回的是一个矩阵,而lm()函数要求一个数据框,你需要用一个中间步骤来转换一下。)
方法二:
相对权重。
标签:
原文地址:http://www.cnblogs.com/yaofang/p/5578387.html