标签:
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来创建list的生成式。
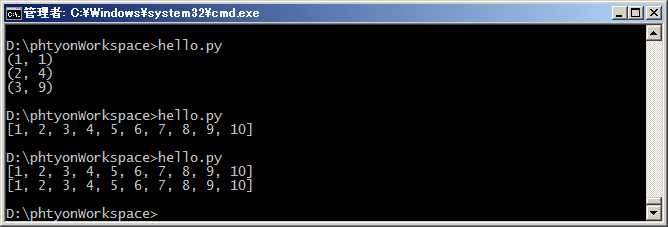
举个例子,要生成list [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]可以用list(range(1, 11)):
#coding=utf-8 print range(1,11) print list(range(1,11))
但如果要生成[1x1, 2x2, 3x3, ..., 10x10]怎么做?方法一是循环:
#coding=utf-8 l = [] for x in range(1,11): l.append(x * x) print l
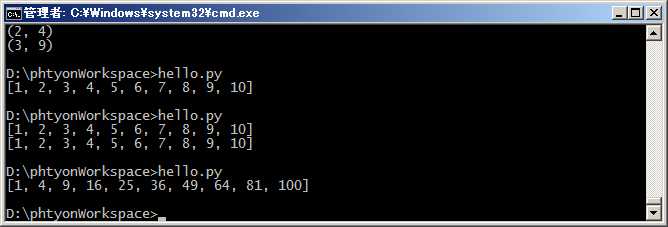
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
#coding=utf-8 print [x * x for x in range(1,11)]
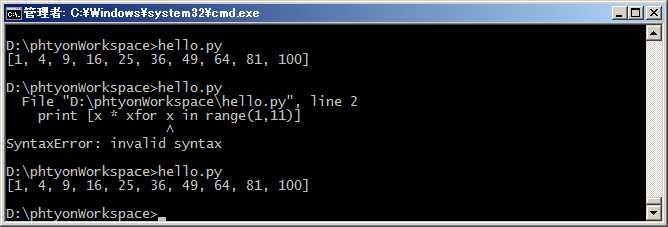
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来,十分有用,多写几次,很快就可以熟悉这种语法。
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
#coding=utf-8 print [x * x for x in range(1,11) if x%2 == 0]
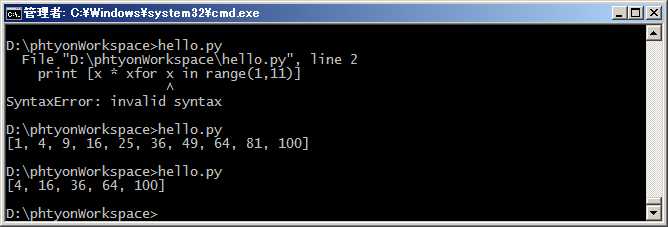
还可以使用两层循环,可以生成全排列:
#coding=utf-8 print [m + n for m in ‘ABC‘ for n in ‘XYZ‘]
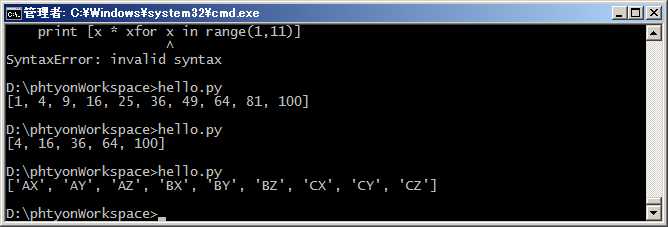
三层和三层以上的循环就很少用到了。
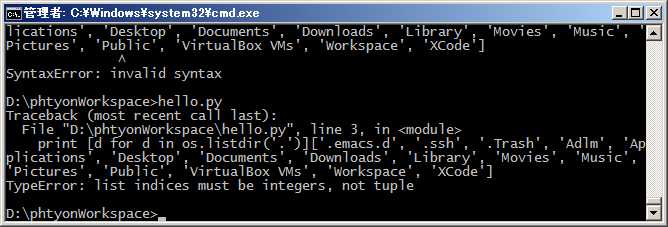
运用列表生成式,可以写出非常简洁的代码。例如,列出当前目录下的所有文件和目录名,可以通过一行代码实现:
#coding=utf-8 import os #导入os模块 print [d for d in os.listdir(‘.‘)][‘.emacs.d‘, ‘.ssh‘, ‘.Trash‘, ‘Adlm‘, ‘Applications‘, ‘Desktop‘, ‘Documents‘, ‘Downloads‘, ‘Library‘, ‘Movies‘, ‘Music‘, ‘Pictures‘, ‘Public‘, ‘VirtualBox VMs‘, ‘Workspace‘, ‘XCode‘]
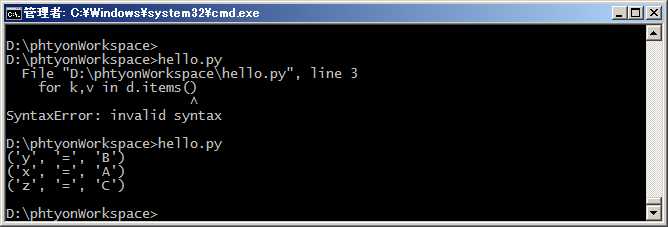
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
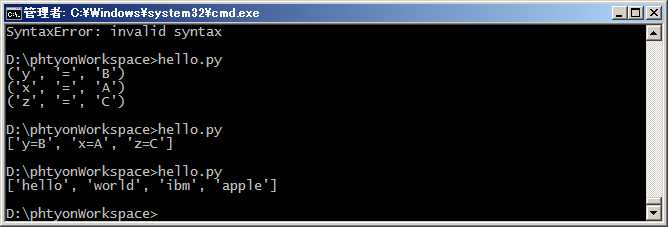
#coding=utf-8 d = {‘x‘: ‘A‘, ‘y‘: ‘B‘, ‘z‘: ‘C‘ } for k,v in d.items(): print (k, ‘=‘,v)
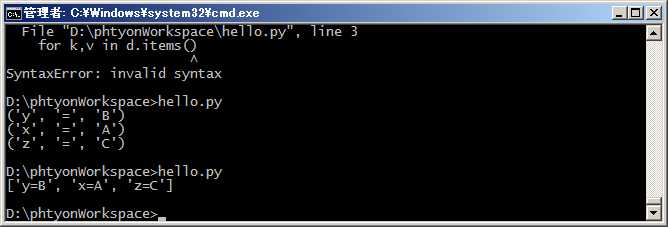
因此,列表生成式也可以使用两个变量来生成list:
#coding=utf-8 d = {‘x‘: ‘A‘, ‘y‘: ‘B‘, ‘z‘: ‘C‘ } print [k + ‘=‘ + v for k, v in d.items()]
最后把一个list中所有的字符串变成小写:
#coding=utf-8 L = [‘Hello‘, ‘World‘, ‘IBM‘, ‘Apple‘] print [s.lower() for s in L]
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
#coding=utf-8 L = [x * x for x in range(10)] print L g = (x * x for x in range(10)) print g
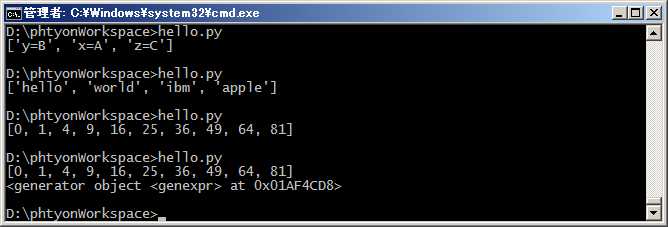
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。
我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
#coding=utf-8 L = [x * x for x in range(10)] print L g = (x * x for x in range(10)) print next(g) print next(g) print next(g) print next(g) print next(g)
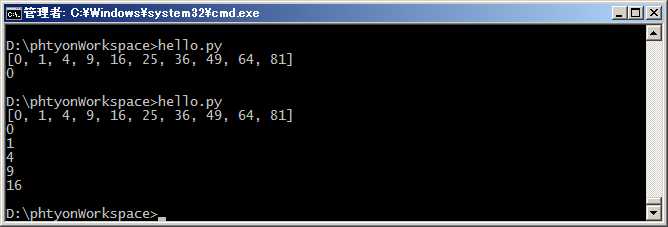
我们讲过,generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象:
#coding=utf-8 g = (x * x for x in range(10)) for n in g: print (n)
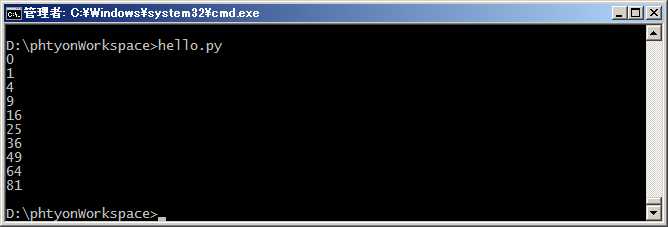
所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
#coding=utf-8 def fib(max): n, a, b = 0,0,1 while n < max: print(b) a, b = b , a+b n = n+1 return ‘done‘ print fib(6)
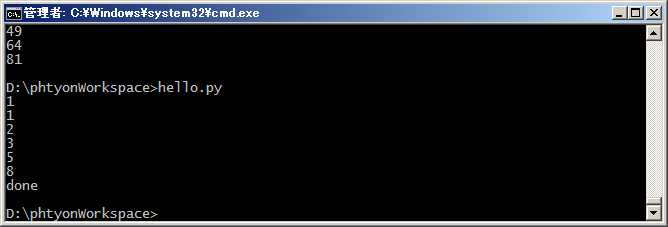
仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
标签:
原文地址:http://www.cnblogs.com/tingbogiu/p/5591798.html