标签:
. The ResourceManager (RM) is responsible for tracking the resources in a cluster, and scheduling applications (e.g., MapReduce jobs). Prior to Hadoop 2.4, the ResourceManager is the single point of failure in a YARN cluster. The High Availability feature adds redundancy in the form of an Active/Standby ResourceManager pair to remove this otherwise single point of failure.
RM负责跟踪集群中的资源,然后调度类似于MR这样具体的应用程序。在Hadoop2.4版本以前,RM在YARN集群中的一个可能造成集群故障的单点。通过以主备RM的方式增加冗余,高可用性功能 规避了单点问题导致的集群不可用。
ResourceManager HA is realized through an Active/Standby architecture - at any point of time, one of the RMs is Active, and one or more RMs are in Standby mode waiting to take over should anything happen to the Active. The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic-failover is enabled.
RM HA功能是通过主从备份架构实现的:在任何时候,多个RM中的一个作为主RM提供服务,另有一个或者多个RM处于待命状态,当有主RM出事了以后,待命的RM能够进行接管。如果要触发切换到主RM事务,可以由管理员从命令行的输入,也可在自动failover功能开关打开以后,通过集成failover控制器触发。
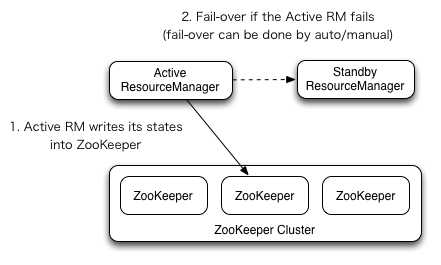
When automatic failover is not enabled, admins have to manually transition one of the RMs to Active. To failover from one RM to the other, they are expected to first transition the Active-RM to Standby and transition a Standby-RM to Active. All this can be done using the “yarn rmadmin” CLI.
当自动failover功能未打开时候,管理员必须手工设置多个RM中的一个到主服务状态。为了实现从一个RM 到另外一个的failover切换,需要首先把主RM设置从active状态切换到standby状态,然后把一个standby的切换到active。这些操作可以通过yarn rmadmin 命令行进行。
The RMs have an option to embed the Zookeeper-based ActiveStandbyElector to decide which RM should be the Active. When the Active goes down or becomes unresponsive, another RM is automatically elected to be the Active which then takes over. Note that, there is no need to run a separate ZKFC daemon as is the case for HDFS because ActiveStandbyElector embedded in RMs acts as a failure detector and a leader elector instead of a separate ZKFC deamon.
RM有个选项去嵌入一个基于Zookeeper的主备选举器,它能够决定哪个RM应该是active的。当主RM挂掉或者无法响应,另外一个RM会自动的被选举为主RM,随后去接管。注意,没有必要去启动一个独立的ZKFC守护进程,因为对HDFS来说,嵌入在RM里面的主从选举器能够作为一个故障检测模块和一个领袖选举器工作,而非一个独立的ZKFC守护进程。
When there are multiple RMs, the configuration (yarn-site.xml) used by clients and nodes is expected to list all the RMs. Clients, ApplicationMasters (AMs) and NodeManagers (NMs) try connecting to the RMs in a round-robin fashion until they hit the Active RM. If the Active goes down, they resume the round-robin polling until they hit the “new” Active. This default retry logic is implemented as org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider. You can override the logic by implementing org.apache.hadoop.yarn.client.RMFailoverProxyProvider and setting the value of yarn.client.failover-proxy-provider to the class name.
当有多个资源管理器的时候,被节点和客户端所使用的配置(yarn-site.xml)需要列举出全部资源管理器。客户端、应用主节点们和节点管理器们尝试以轮询方式连接资源管理器们,一直到访问的主资源管理器。如果主资源管理器挂掉,他们继续执行循环查询一直找到新的主节点。默认的重试逻辑是在org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider中实现的。可通过实现org.apache.hadoop.yarn.client.RMFailoverProxyProvider类来重写重试逻辑,然后把类名替换到yarn.client.failover-proxy-provider的值中。
With the ResourceManger Restart enabled, the RM being promoted to an active state loads the RM internal state and continues to operate from where the previous active left off as much as possible depending on the RM restart feature. A new attempt is spawned for each managed application previously submitted to the RM. Applications can checkpoint periodically to avoid losing any work. The state-store must be visible from the both of Active/Standby RMs. Currently, there are two RMStateStore implementations for persistence - FileSystemRMStateStore and ZKRMStateStore. The ZKRMStateStore implicitly allows write access to a single RM at any point in time, and hence is the recommended store to use in an HA cluster. When using the ZKRMStateStore, there is no need for a separate fencing mechanism to address a potential split-brain situation where multiple RMs can potentially assume the Active role. When using the ZKRMStateStore, it is advisable to NOT set the “zookeeper.DigestAuthenticationProvider.superDigest” property on the Zookeeper cluster to ensure that the zookeeper admin does not have access to YARN application/user credential information.
在资源管理器重启功能打开情况下,被设置为激活状态的资源管理器,尽最大可能的从前一个激活的资源管理器停止的地方加载其内部状态并恢复操作。资源管理器会尝试把之前提交到资源管理器的中的每个被管理的应用都重新提交。应用程序通过定期设置检查点规避丢失掉任务。不管是对激活的还是备用的资源管理器,状态储存对他们都必须是可见的。当前,有两种实现了持久化存储的资源管理器状态存储:FileSystemRMStateStore 和 ZKRMStateStore。 ZKRMStateStore允许即时向单个的资源管理器更新状态,所以也是在高可用集群中的推荐的一种存储办法。当使用ZKRMStateStore的时候,没有必要设置单独的防御机制,去处理可能出现的多个资源管理器潜在的把自己设置为激活状态的脑裂状态。当使用ZKRMStateStore的时候,建议在Zookeeper集群中不设置zookeeper.DigestAuthenticationProvider.superDigest这个配置,确保Zookeeper管理员不会获取到YARN用户和应用程序的机密信息。
原文见:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
ResourceManager Restart:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/ResourceManagerRestart.html
标签:
原文地址:http://www.cnblogs.com/laodageblog/p/5592030.html