标签:
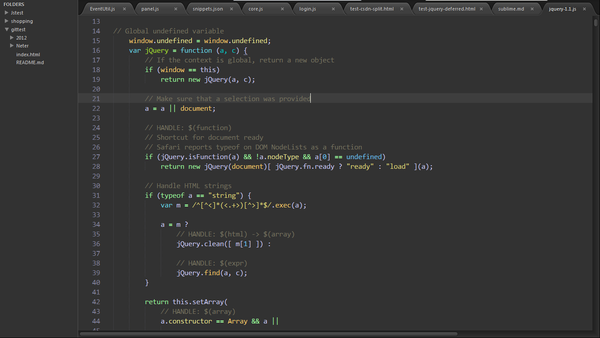
 看到没有,上面是知识,下面是能力,通过知识来积累编程的能力,不是通过工具来限制你思考的速度或深度。
看到没有,上面是知识,下面是能力,通过知识来积累编程的能力,不是通过工具来限制你思考的速度或深度。.
看了一圈,都是编程人员在回答,我就作为一个非编程人员来说点不同的视点吧。
既然说的是「文本编辑器」,最重要的当然是「编辑文本」,而不局限于编程。
我一直在使用的文本编辑器是 vim(windows 下用 gvim,OS X 下用 MacVim),偶尔写代码,主要用来做文本处理。Sublime Text、Emacs(包括纯 evil mode 和 spacemacs)、Atom、VS Code、em editor、notepad++ 等等都用过,最后还是回到 vim 。
究其原因,很多文本编辑器是针对编程来优化的,而不是「文本处理」,于是在文本处理上,远没有 vim 来得方便。
我用 vim 主要做的事情有这几件:
作为 markdown 编辑器写文章
vim 用来写文章的一个很大的优势就是 VOoM 插件。这是一个大纲列表,可以根据特定的标记符号生成像左边这样的文章大纲窗口。在 em editor 中你也可以找到类似的功能。这个插件默认是支持 markdown 的,能够识别出文章的标题。
#一级标题
##二级标题
###三级标题
####四级标题
#####五级标题
######六级标题
#一级标题
##二级标题
###三级标题

并且能够在大纲窗口中通过 ctrl + ↑、ctrl + ↓ 这样的快捷键操作,对标题(及下面所属的内容)进行上下移动,也能进行升级。对于写文章时列大纲、把握文章整体构造还有调整文章结构来说都是十分有利的功能。Emacs 的 org-mode 本身的功能虽然十分出色,但是唯独缺少这样方便的大纲功能,还是比较遗憾的。网上有一些通过 Emacs 的 mini buffer 来实现类似功能的建议,但是对于不熟悉 elisp 的非程序员来说,要自己来实现一个确实太困难了。
特定的格式化文本处理
得益于 vim 的 ex mode 和 viml( vim language ),我可以简单地编写一些脚本命令来进行重复的文本格式化处理。
比如说,我需要处如下的列表式文本,把左右列分开:
原作 - 川原礫(電撃文庫 / アスキー·メディアワークス刊)
原作イラスト·キャラクターデザイン原案 - abec
監督 - 伊藤智彦
キャラクターデザイン - 足立慎吾
美術監督 - 竹田悠介
色彩設計 - 中島和子
コンセプトアート - 堀壮太郎
撮影監督 - 廣岡岳
CG監督 - 雲藤隆太
編集 - 西山茂
音響監督 - 岩浪美和
音楽 - 梶浦由記
アニメーション制作 - A-1 Pictures
原作
原作イラスト·キャラクターデザイン原案
監督
キャラクターデザイン
美術監督
色彩設計
コンセプトアート
撮影監督
CG監督
編集
音響監督
音楽
アニメーション制作
川原礫(電撃文庫 / アスキー·メディアワークス刊)
abec
伊藤智彦
足立慎吾
竹田悠介
中島和子
堀壮太郎
廣岡岳
雲藤隆太
西山茂
岩浪美和
梶浦由記
A-1 Picture
:%s/ - /\r\t
:g/^\t/m$
因为我需要频繁用到这样的需求,所以不想频繁重复地写这样的命令。所以我就可以写一个函数来处理:
function ListSplit()
:%s/ - /\r\t
:g/^\t/m$
endfunction
我们可以看到,这个所谓的函数,实际上就是只是把 ex mode 中输入的命令写上去而已。我平常是怎么在 vim 的进行操作的,就可以怎样很直觉地把这些操作整合成一个函数。对于没有编程基础的用户来说,这比起 elisp 这种过分强大的的语言来说简单明了得多。
在 Emacs 中,你是无法如此简单地把一般的操作转化为一个函数、一个脚本的。而在其他编辑器中,你甚至无法找到一个如此轻量化的解决方案。
完成定义之后,我就能用简单的调用函数来执行这两句命令:
:call ListSplit()
如果这样还觉得麻烦,那么可以为函数定一个自定义命令,省去写「 call 」的麻烦。
command! ListSplit call ListSplit()
如果连命令都懒得输,绑定一个快捷键也十分简单:
nmap <F1> :call ListSplit()<cr>
这样就可以用 F1(当然也可以是其他快捷键,配合 键甚至可以有更灵活的配置)调用这个函数。
制作 epub 电子书
制作一本简单的 epub 电子书,有两大部分工作:整理文本,和对文本进行打包。
整理文本是 vim 的拿手好戏,而把文本打包成 epub 文件,就涉及到了很多的 I/O 操作,viml 确实是搞不定的,这部分我用了 python 来写,因为 vim 本身有 python 接口。
这是我用来制作 epub 的小插件:dotvim/bundle/epub-build/plugin at master · zecy/dotvim · GitHub
说是插件,实际上里面只有一堆相互独立的函数,而函数的内部基本上都是大量的替换命令。如果是其他编辑器,你要自行制作同样的文本整理功能,就逃不了正儿八经的编程了。相对而言,用 viml 来做这个事情,远远要简单得多。
以下我说明里面的两个小函数。
function SymbolChange()
silent %s/\v(1|2|3|4|5|6|7|8|9|0)/\={‘1‘:‘1‘,‘2‘:‘2‘,‘3‘:‘3‘,‘4‘:‘4‘,‘5‘:‘5‘,‘6‘:‘6‘,‘7‘:‘7‘,‘8‘:‘8‘,‘9‘:‘9‘,‘0‘:‘0‘}[submatch(0)]/ge
silent %s/\v(A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|X|Y|Z)/\={‘A‘:‘A‘,‘B‘:‘B‘,‘C‘:‘C‘,‘D‘:‘D‘,‘E‘:‘E‘,‘F‘:‘F‘,‘G‘:‘G‘,‘H‘:‘H‘,‘I‘:‘I‘,‘J‘:‘J‘,‘K‘:‘K‘,‘L‘:‘L‘,‘M‘:‘M‘,‘N‘:‘N‘,‘O‘:‘O‘,‘P‘:‘P‘,‘Q‘:‘Q‘,‘R‘:‘R‘,‘S‘:‘S‘,‘T‘:‘T‘,‘U‘:‘U‘,‘V‘:‘V‘,‘W‘:‘W‘,‘X‘:‘X‘,‘Y‘:‘Y‘,‘Z‘:‘Z‘}[submatch(0)]/ge
python << EOF
# -*- coding: UTF-8 -*-
import vim
import string
import re
b = vim.current.buffer
t = u‘\n‘.encode("UTF-8").join(b)
t = t.decode("UTF-8")
def symbolchange(t):
t = re.sub(u‘( |\t| )+‘, u‘ ‘, t)
t = re.sub(u‘[\[“【]‘, u‘「‘, t)
t = re.sub(u‘[\]”】]‘, u‘」‘, t)
t = re.sub(u‘‘‘, u"『", t)
t = re.sub(u‘’‘, u"』", t)
# t = re.sub(u‘[‘’]‘, u"‘", t)
t = string.replace(t, "&", "&")
t = re.

