标签:
看完了BeautifulSoup的官方文档, 今天试着爬了一波自家学校moodle, 写了一个简陋查分器, 还算是成功, 代码已经扔在github上了, 感兴趣的朋友可以去看看.
https://github.com/zhang77595103/web-crawler
今天模仿大神xlzd, 准备先写一个爬取豆瓣电影top250, 主要也是想看看反爬虫的机制, 毕竟不是每个网站都像我们学校的官网这样, 爬虫随进随出...
因为目前我还有没有看过requests这个库的官方文档, 所以有现在暂且是有一个知识点记一个知识点吧...
import requests homePageResponse = requests.get("https://movie.douban.com/") print(type(homePageResponse.content)) print(type(homePageResponse.text)) --------------------------------------------------------------- /Library/Frameworks/Python.framework/Versions/3.5/bin/python3.5 /Users/zhangzhimin/PycharmProjects/PythonAgain/test2.py <class ‘bytes‘> <class ‘str‘> Process finished with exit code 0
这是.content和.text的区别, 那么这里有个知识是, 在py3中, bytes解码(decode())会变成str, str编码会变成bytes(encode)...
所以总的来说.content.decode()就相当于.text...
按照大神的思路, 剧本应该是这样的 :
<html> <head><title>403 Forbidden</title></head> <body bgcolor="white"> <center><h1>403 Forbidden</h1></center> <hr><center>dae</center> </body> </html>
产生403的原因,一般可能是因为需要登录的网站没有登录或者被服务器认为是爬虫而拒绝访问,这里很显然属于第二种情况。一般,浏览器在向服务器发送请求的时候,会有一个请求头——
User-Agent,它用来标识浏览器的类型.当我们使用requests来发送请求的时候,默认的User-Agent是python-requests/2.8.1(后面的数字可能不同,表示版本号)。那么,我们试试看如果将User-Agent伪装成浏览器的,会不会解决这个问题呢?
然后遗憾的是, 并没有出现大神所谓的403, 这让我很尴尬... 不过还是耐着性子继续爬吧..
我先假装我的网页出了403(其实我发现我不加头也完美爬取了), 然后我们来给自己的爬虫User-Agent吧...
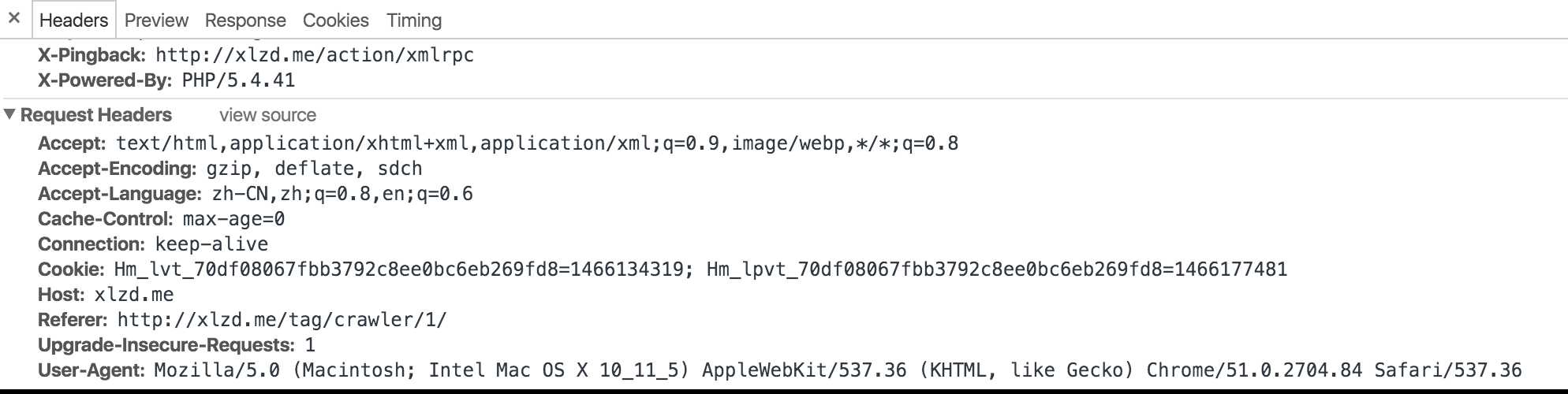
我随便找个一个网站, 打开检查之后, 刷新了一下... 可以看到最后一行就是我们需要的UA...
最后的代码如下...
1 import requests 2 from bs4 import BeautifulSoup 3 4 5 def pageCheck(url, headers): 6 homePageResponse = requests.get(url, headers=headers) 7 homePageSoup = BeautifulSoup(homePageResponse.content, ‘lxml‘) 8 for li in homePageSoup.find("ol", class_ = "grid_view").find_all("li"): 9 link = li.find("div", class_ = "hd").a 10 print(link.span.string + " : " + link[‘href‘]) 11 12 13 url = "https://movie.douban.com/top250" 14 start = 25 15 headers = { 16 ‘User-Agent‘:‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) 17 AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36‘ 18 } 19 for cnt in range(0, 10): 20 print("\n\nThis is page " + str(cnt+1) + " ...\n\n") 21 if cnt == 0: 22 curUrl = url 23 else: 24 curUrl = url + "?start=" + str(start * cnt) + "&filter" 25 pageCheck(curUrl, headers)
标签:
原文地址:http://www.cnblogs.com/nzhl/p/5595455.html