标签:
上一篇介绍了最基础的使用方法,也是最自由最灵活的方式,但是其实大多数情况下是可以用模型配置的方式实现一个爬虫的。我们做框架,肯定要尽可能的把一些重复性的工作帮你们做掉,当然灵活性等也会打折扣,但肯定有存在的意义。
另,爬虫已经对dotnet core rc2 做了适配,可以在dotnet core rc2环境下运行啦

[Schema("test", "sku", TableSuffix.Today)]
[TypeExtractBy(Expression = "//li[@class=‘gl-item‘]/div[contains(@class,‘j-sku-item‘)]", Multi = true)]
[Indexes(Index = new[] { "category" }, Unique = new[] { "category,sku", "sku" })]
public class Product : ISpiderEntity
{
[StoredAs("category", DataType.String, 20)]
[PropertyExtractBy(Expression = "name", Type = ExtractType.Enviroment)]
public string CategoryName { get; set; }
[StoredAs("cat3", DataType.String, 20)]
[PropertyExtractBy(Expression = "cat3", Type = ExtractType.Enviroment)]
public int CategoryId { get; set; }
[StoredAs("url", DataType.Text)]
[PropertyExtractBy(Expression = "./div[1]/a/@href")]
public string Url { get; set; }
[StoredAs("sku", DataType.String, 25)]
[PropertyExtractBy(Expression = "./@data-sku")]
public string Sku { get; set; }
[StoredAs("commentscount", DataType.String, 32)]
[PropertyExtractBy(Expression = "./div[5]/strong/a")]
public long CommentsCount { get; set; }
[StoredAs("shopname", DataType.String, 100)]
[PropertyExtractBy(Expression = ".//div[@class=‘p-shop‘]/@data-shop_name")]
public string ShopName { get; set; }
[StoredAs("name", DataType.String, 50)]
[PropertyExtractBy(Expression = ".//div[@class=‘p-name‘]/a/em")]
public string Name { get; set; }
[StoredAs("venderid", DataType.String, 25)]
[PropertyExtractBy(Expression = "./@venderid")]
public string VenderId { get; set; }
[StoredAs("jdzy_shop_id", DataType.String, 25)]
[PropertyExtractBy(Expression = "./@jdzy_shop_id")]
public string JdzyShopId { get; set; }
[StoredAs("run_id", DataType.Date)]
[PropertyExtractBy(Expression = "Monday", Type = ExtractType.Enviroment)]
public DateTime RunId { get; set; }
[PropertyExtractBy(Expression = "Now", Type = ExtractType.Enviroment)]
[StoredAs("cdate", DataType.Time)]
public DateTime CDate { get; set; }
}
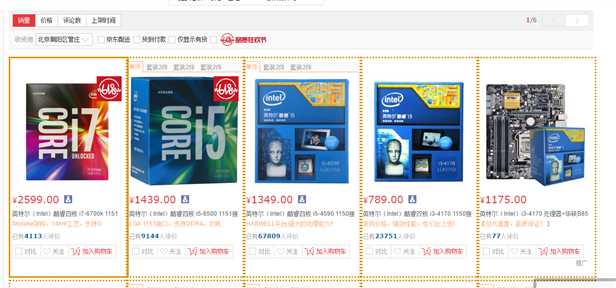
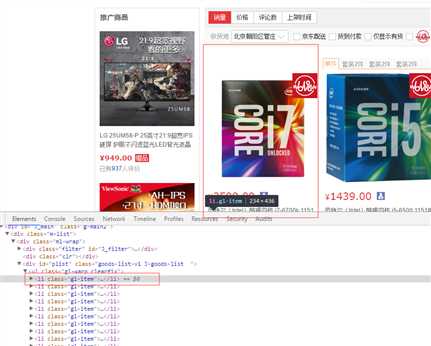
每个商品为一个li, 并且我们需要存为一行数据,因此TypeExtractBy我们可以指定为XPATH, 并且填上能够把所有元素查询出来表达式://li[@class=‘gl-item‘], 同时把Multi设置为True以告诉爬虫这个表达式查询结果为List. 当你熟练度够了之后,这个表达式还可以改成我上面的
//li[@class=‘gl-item‘]/div[contains(@class,‘j-sku-item‘)]
原因是京东有一个DIV藏了好几个套装的情况,每个套装又是一个SKU,以上XPATH可以尽可能多的取到数据
5. 定义数据列:首先定义一个public的属性,在属性上添加StoreAs用于定义在数据库中的存储类型,同时定义该属性的抽取规则PropertyExtractBy,这时候要注意的是,属性的抽取是要计算相对行上面数据行的PATH,而不是绝对的。如下,
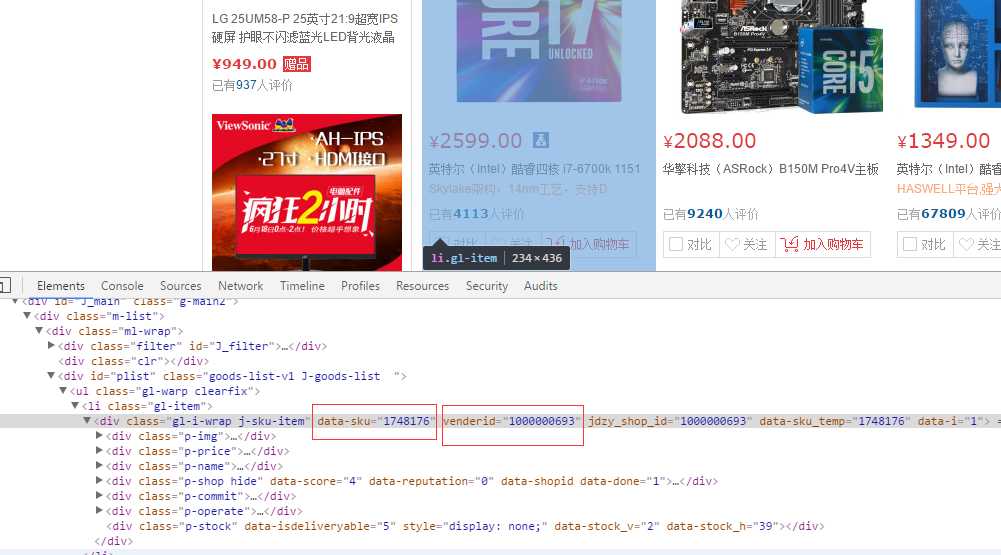
我们行首先已经定位到了gl-i-warp j-sku-item这个DIV,假设你想从这个DIV的attribute中取得sku数据,这时你应该这么定义(.表示当前节点,具体可以去w3school学一下XPATH)
[StoredAs("sku", DataType.String, 25)]
[PropertyExtractBy(Expression = "./@data-sku")]
public string Sku { get; set; }
6. 环境变量:我们经常用到的一个场景是,抓取SKU的链接是从category过来的,我们想保留category的信息到SKU表中,这时候如何把category的信息传递到数据对象中呢? 需要做两步:
第一是在初始化的StartUrl时要添加信息
context.AddStartUrl("http://list.jd.com/list.html?cat=9987,653,655&page=2&JL=6_0_0&ms=5#J_main", new Dictionary<string, object> { { "name", "手机" }, { "cat3", "655" } });
第二是定义环境变量属性抽取规则:
[StoredAs("category", DataType.String, 20)]
[PropertyExtractBy(Expression = "name", Type = ExtractType.Enviroment)]
public string CategoryName { get; set; }
7. 特殊数据:大多会用到当天时间,或者星期一等特殊时间,我们也可以使用环境变量来实现
[StoredAs("run_id", DataType.Date)]
[PropertyExtractBy(Expression = "Monday", Type = ExtractType.Enviroment)]
public DateTime RunId { get; set; }
[PropertyExtractBy(Expression = "Now", Type = ExtractType.Enviroment)]
[StoredAs("cdate", DataType.Time)]
public DateTime CDate { get; set; }
定义一个类,继承SpiderBuilder
protected override SpiderContext GetSpiderContext()
{
SpiderContext context = new SpiderContext();
context.SetSpiderName("JD sku/store test " + DateTime.Now.ToString("yyyy-MM-dd HHmmss"));
context.AddTargetUrlExtractor(new Extension.Configuration.TargetUrlExtractor
{
Region = new Extension.Configuration.Selector { Type = ExtractType.XPath, Expression = "//span[@class=\"p-num\"]" },
Patterns = new List<string> { @"&page=[0-9]+&" }
});
context.AddPipeline(new MysqlPipeline
{
ConnectString = "Database=‘test‘;Data Source=;User ID=root;Password=;Port=4306"
});
context.AddStartUrl("http://list.jd.com/list.html?cat=9987,653,655&page=2&JL=6_0_0&ms=5#J_main", new Dictionary<string, object> { { "name", "手机" }, { "cat3", "655" } });
context.AddEntityType(typeof(Product));
return context;
}
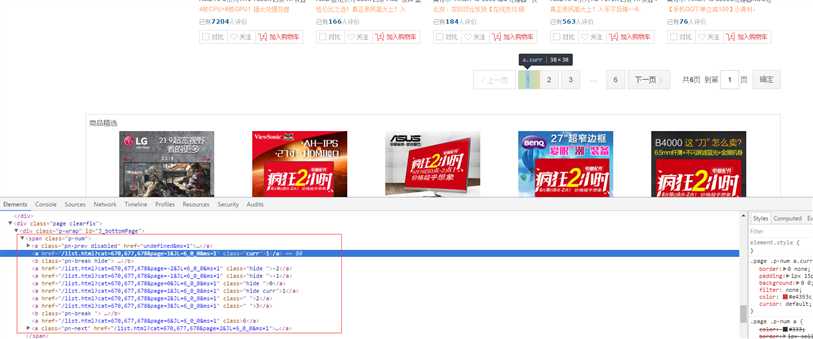
3. 配置URL调度,如果不配置则默认使用内存Queue, 可以使用已经实现的Queue或者RedisScheduler(用于分布式)
context.SetScheduler(new RedisScheduler
{
Host = "",
Password = "",
Port = 6379
});
4. 我们添加一个MySql的数据管道,只需要配置好你的连接字符串即可
5. 添加StartUrl, 这里可以添加额外数据用于传递到目标数据对象
6. 添加目标数据对象:
context.AddEntityType(typeof(Product));
7. 运行爬虫:
JdSkuSampleSpider spiderBuilder = new JdSkuSampleSpider();
spiderBuilder.Run("rerun");
8. 额外配置:大家可以自己查看API,可以配置线程数SetThreadNum, 在广义搜索爬取时控制深度(SetDeep), 设置Pipeline的数据提交频次SetCachedSize等
https://raw.githubusercontent.com/zlzforever/DotnetSpider/master/src/Java2Dotnet.Spider.Test/Example/JdSkuSample.cs
可以看到,只需区区几行代码就可以实现一个爬虫,帮你建表、分表,抓取、抽取数据,还是比较简单的
介绍如何抓取一些API,JSONPATH的数据
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5597132.html