标签:
可持久化数据结构(Persistent data structure)就是利用函数式编程的思想使其支持询问历史版本、同时充分利用它们之间的共同数据来减少时间和空间消耗。
因此可持久化线段树也叫函数式线段树又叫主席树。
在算法执行的过程中,会发现在更新一个动态集合时,需要维护其过去的版本。这样的集合称为是可持久的。
实现持久集合的一种方法时每当该集合被修改时,就将其整个的复制下来,但是这种方法会降低执行速度并占用过多的空间。
考虑一个持久集合S。
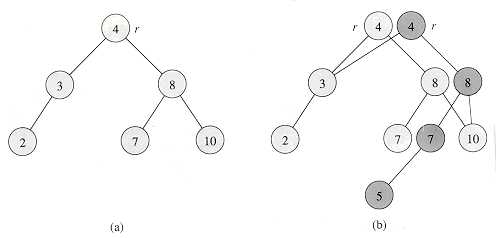
如图所示,对集合的每一个版本维护一个单独的根,在修改数据时,只复制树的一部分。
称之为可持久化数据结构。
离散化
但是,有一个很重要的问题!题目的空间限制肯定是有的,假设所输入的数的范围为int,你总不可能开一个大小为int的树吧?而且还要多棵线段树。此时此刻,我们就可以引入一个新知识了——离散化。看起来很高端,其实很简单,其实你脑补一下map(属于STL)就行了,或者回忆一下高中数学必修一集合那一章,有一个叫映射的东西,和离散化意思差不多(起码在这道题上的作用是一模一样的),所以不详细阐述,在源代码中会有小小的注释。
好了,目前有一个数列:{2,8,19,6}。假设我们已经离散化结束了,结果为2→1;6→2;8→3;19→4。那么以后我们进行数据的处理时,1就表示2了,2就表示6了,3就表示8了。。。是不是和映射一个意思?这样的好处在于,我们不需要依赖就弄个[1,2147483647]的线段树了,若题目规定n<=100000,则最大只需要一棵[1,10000]的线段树了。如下图(其实没有蛮多含义,真正的变化在后面):
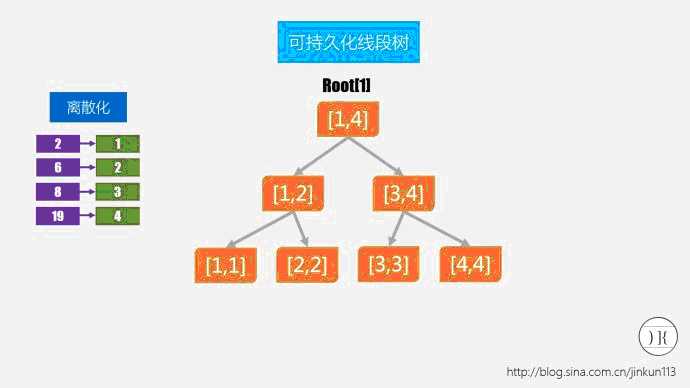
【若是建一棵[1,19]的线段树,你想想是多么浪费空间 = =。】
历史版本的作用
这么多棵线段树,我们也不可能建立多个结构体来保存。我们可以把所有线段树的节点全部放在tree结构体中,设当前有m个节点,每执行一次插入操作,新增了x个节点,则存放在tree中的第(m+1)个节点至第(m+x)个节点(当然也有别的编号方式)。同时,我们需要一个root数组,其中root[i]表示第i棵线段树的根节点的编号。 这样我们就构建完了,来想想——为什么需要历史版本?回到我们一开始的问题,求区间第k大,假设当前询问为求[x,y]的第k大,则我们所需要用到的线段树为第x+1棵到第y棵。从根节点开始,我们将第y棵树和第x+1棵树一一对应的节点所维护的值进行相减,其所得到的数就是在所询问的[x,y]中,当前节点表示的子区间的那几个数值在整个区间中出现的次数,用t表示,即t=root[y].[1,mid]-root[x-1].[1,mid]。先判断t是否大于k,如果t大于k,那么说明在区间[x,y]内存在[1,mid]的数的个数大于k,也就是第k大的值在[1,mid]中,否则在[mid+1,r]中。(有点绕,慢慢看 →_→)

缩小空间
其实必要的知识已经讲得差不多了,但是我们最后还要面临一个问题——加入一个数,就新建一棵线段树。我们假设有100000个数吧,且有100000次询问,试想这一大片庞大的线段树森林是要占用多大的内存?一定会MLE的(当然数据小就无所谓)。我们有什么办法缩小空间需求?我们注意到,每次我们加入一个被离散化后的数x,则从根结点开始向下更新,我们真正相对于前面一棵线段树的差异之处是很少的!设有一颗[1,4]的线段树,若当前插入值为3,则[1,4]的左儿子[1,2]没有丝毫改动!如果又新建一个,完全是浪费。这样子,我们就有一个方法缩小冗余的空间了——将没有区别的部分直接指回去!如图所示:
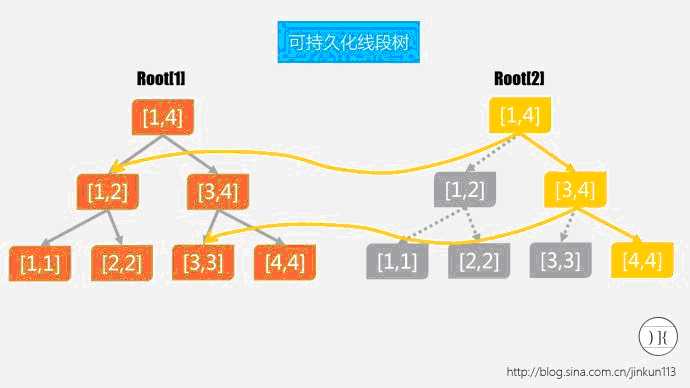
空间是不是小多了!是的。后面的线段树也以此类推。
令 T 表示一个结点,它的左儿子是 left(T),右儿子是 right(T)。
若 T 的范围是 [L,R],那么 left(T) 的范围是 [L,mid],right(T) 的范围是 [mid+1,R]。
我们要修改一个叶子结点的值,并且不能影响旧版本的结构。
在从根结点递归向下寻找目标结点时,将路径上经过的结点都复制一份。
找到目标结点后,我们新建一个新的叶子结点,使它的值为修改后的版本,并将它的地址返回。
对于一个非叶子结点,它至多只有一个子结点会被修改,那么我们对将要被修改的子结点调用修改函数,那么就得到了它修改后的儿子。
在每一步都向上返回当前结点的地址,使父结点能够接收到修改后的子结点。
在这个过程中,只有对新建的结点的操作,没有对旧版本的数据进行修改。
从要查询的版本的根节点开始,像查询普通的线段树那样查询即可。
...
有n个数,多次询问一个区间[L,R]中第k小的值是多少。
我们先对数据进行离散化,然后按值域建立线段树,线段树中维护某个值域中的元素个数。
在线段树的每个结点上用cnt记录这一个值域中的元素个数。
那么要寻找第K小值,从根结点开始处理,若左儿子中表示的元素个数大于等于K,那么我们递归的处理左儿子,寻找左儿子中第K小的数;
若左儿子中的元素个数小于K,那么第K小的数在右儿子中,我们寻找右儿子中第K-(左儿子中的元素数)小的数。
我们按照从1到n的顺序依次将数据插入可持久化的线段树中,将会得到n+1个版本的线段树(包括初始化的版本),将其编号为0~n。
可以发现所有版本的线段树都拥有相同的结构,它们同一个位置上的结点的含义都相同。
考虑第i个版本的线段树的结点P,P中储存的值表示[1,i]这个区间中,P结点的值域中所含的元素个数;
假设我们知道了[1,R]区间中P结点的值域中所含的元素个数,也知道[1,L-1]区间中P结点的值域中所包含的元素个数,显然用第一个个数减去第二个个数,就可以得到[L,R]区间中的元素个数。
因此我们对于一个查询[L,R],同步考虑两个根root[L-1]与root[R],用它们同一个位置的结点的差值就表示了区间[L,R]中的元素个数,利用这个性质,从两个根节点,向左右儿子中递归的查找第K小数即可。
注意可持久化数据结构的内存开销非常大,因此要注意尽可能的减少不必要的空间开支。

1 const int maxn=100001; 2 struct Node{ 3 int ls,rs; 4 int cnt; 5 }tr[maxn*20]; 6 int cur,rt[maxn]; 7 void init(){ 8 cur=0; 9 } 10 inline void push_up(int o){ 11 tr[o].cnt=tr[tr[o].ls].cnt+tr[tr[o].rs].cnt; 12 } 13 int build(int l,int r){ 14 int k=cur++; 15 if (l==r) { 16 tr[k].cnt=0; 17 return k; 18 } 19 int mid=(l+r)>>1; 20 tr[k].ls=build(l,mid); 21 tr[k].rs=build(mid+1,r); 22 push_up(k); 23 return k; 24 } 25 int update(int o,int l,int r,int pos,int val){ 26 int k=cur++; 27 tr[k]=tr[o]; 28 if (l==pos&&r==pos){ 29 tr[k].cnt+=val; 30 return k; 31 } 32 int mid=(l+r)>>1; 33 if (pos<=mid) tr[k].ls=update(tr[o].ls,l,mid,pos,val); 34 else tr[k].rs=update(tr[o].rs,mid+1,r,pos,val); 35 push_up(k); 36 return k; 37 } 38 int query(int l,int r,int o,int v,int kth){ 39 if (l==r) return l; 40 int mid=(l+r)>>1; 41 int res=tr[tr[v].ls].cnt-tr[tr[o].ls].cnt; 42 if (kth<=res) return query(l,mid,tr[o].ls,tr[v].ls,kth); 43 else return query(mid+1,r,tr[o].rs,tr[v].rs,kth-res); 44 }
一种在常数上减小内存消耗的方法:
插入值时候先不要一次新建到底,能留住就留住,等到需要访问子节点时候再建下去。
这样理论内存复杂度依然是O(Nlg^2N),但因为实际上很多结点在查询时候根本没用到,所以内存能少用一些。
每一棵线段树是维护每一个序列前缀的值在任意区间的个数,如果还是按照静态的来做的话,那么每一次修改都要遍历O(n)棵树,时间就是O(2*M*nlogn)->TLE。
考虑到前缀和,我们通过树状数组来优化,即树状数组套主席树,每个节点都对应一棵主席树,那么修改操作就只要修改logn棵树,O(nlognlogn+Mlognlogn)时间是可以的,但是直接建树要nlogn*logn(10^7)会MLE。
我们发现对于静态的建树我们只要nlogn个节点就可以了,而且对于修改操作,只是修改M次,每次改变俩个值(减去原先的,加上现在的)也就是说如果把所有初值都插入到树状数组里是不值得的,所以我们分两部分来做,所有初值按照静态来建,内存O(nlogn),而修改部分保存在树状数组中,每次修改logn棵树,每次插入增加logn个节点O(M*logn*logn+nlogn)。
入门题,求区间第K小数。
1 #include <iostream> 2 #include <cstdio> 3 #include <cstring> 4 #include <algorithm> 5 using namespace std; 6 const int maxn=100001; 7 struct Node{ 8 int ls,rs; 9 int cnt; 10 }tr[maxn*20]; 11 int cur,rt[maxn]; 12 void init(){ 13 cur=0; 14 } 15 inline void push_up(int o){ 16 tr[o].cnt=tr[tr[o].ls].cnt+tr[tr[o].rs].cnt; 17 } 18 int build(int l,int r){ 19 int k=cur++; 20 if (l==r) { 21 tr[k].cnt=0; 22 return k; 23 } 24 int mid=(l+r)>>1; 25 tr[k].ls=build(l,mid); 26 tr[k].rs=build(mid+1,r); 27 push_up(k); 28 return k; 29 } 30 int update(int o,int l,int r,int pos,int val){ 31 int k=cur++; 32 tr[k]=tr[o]; 33 if (l==pos&&r==pos){ 34 tr[k].cnt+=val; 35 return k; 36 } 37 int mid=(l+r)>>1; 38 if (pos<=mid) tr[k].ls=update(tr[o].ls,l,mid,pos,val); 39 else tr[k].rs=update(tr[o].rs,mid+1,r,pos,val); 40 push_up(k); 41 return k; 42 } 43 int query(int l,int r,int o,int v,int kth){ 44 if (l==r) return l; 45 int mid=(l+r)>>1; 46 int res=tr[tr[v].ls].cnt-tr[tr[o].ls].cnt; 47 if (kth<=res) return query(l,mid,tr[o].ls,tr[v].ls,kth); 48 else return query(mid+1,r,tr[o].rs,tr[v].rs,kth-res); 49 } 50 int b[maxn]; 51 int sortb[maxn]; 52 int main() 53 { 54 int n,m; 55 int T; 56 //scanf("%d",&T); 57 //while (T--){ 58 while (~scanf("%d%d",&n,&m)){ 59 init(); 60 for (int i=1;i<=n;i++){ 61 scanf("%d",&b[i]); 62 sortb[i]=b[i]; 63 } 64 sort(sortb+1,sortb+1+n); 65 int cnt=1; 66 for (int i=2;i<=n;i++){ 67 if (sortb[i]!=sortb[cnt]){ 68 sortb[++cnt]=sortb[i]; 69 } 70 } 71 rt[0]=build(1,cnt); 72 for (int i=1;i<=n;i++){ 73 int p=lower_bound(sortb+1,sortb+cnt+1,b[i])-sortb; 74 rt[i]=update(rt[i-1],1,cnt,p,1); 75 } 76 for (int i=0;i<m;i++){ 77 int a,b,k; 78 scanf("%d%d%d",&a,&b,&k); 79 int idx=query(1,cnt,rt[a-1],rt[b],k); 80 printf("%d\n",sortb[idx]); 81 } 82 } 83 return 0; 84 }
标签:
原文地址:http://www.cnblogs.com/shenben/p/5598371.html
