如果是初创型公司,机器规模和工作流转没有那么复杂的情况下。运维监控和报警,都利用 Zabbix 和一些报警聚合服务。
先来说说,我们公司如何利用 Zabbix 监控和报警的吧。
Zabbix 配置报警
其实线上的教程很多:
Zabbix 的图文安装教程 。
下面自己 Zabbix 在添加服务器监控以及监控报警方面总结下心得体会吧。
Zabbix 默认的语言是英语如果觉得使用不习惯可以自己汉化下,同样网上有相关的解决方法这里就不多说了。接下就先介绍下添加主机监控的流程。
一、
系统配置--->主机--->Create host
 二、设置主机名字--->监控主机所属组--->监控主机IP地址--->所属模板
二、设置主机名字--->监控主机所属组--->监控主机IP地址--->所属模板
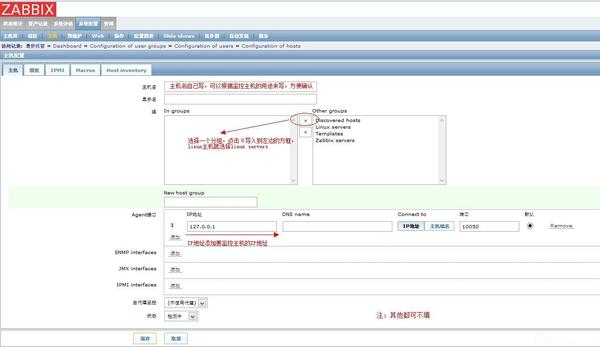


自此在 Zabbix 中就成功添加了一台新的服务器。下面介绍下 Zabbix 如何配置监控报警。
在告警这块 Zabbix 默认只支持邮件,如果需要短信告警还需要进行短信网关对接,复杂度较高。同时我认为短信的告警并非是一个好的方式,虽然发送了告警信息,同样会存在疏漏的情况,而且这种情况发生的概率并不是很低。所以这里就以邮件配置为例来介绍下。
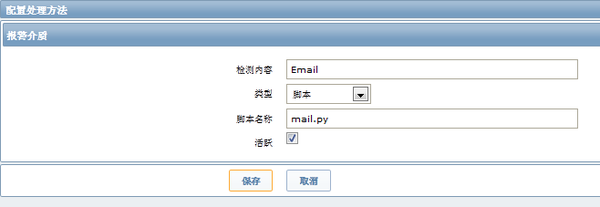
一:添加报警的处理方法
1、打开zabbix的管理--->处理方法--->create media type
这里为了方便就以脚本发邮件的方式来报警,脚本名字为mail.py。这里需要重点关注一下的是脚本存放位置,我的脚本是放在/usr/local/zabbix/bin/目录下面,这里偷下懒 就不写绝对路径了,脚本的路径设置是在zabbix服务器端的配置文件中设置的,在zabbix_server.conf配置文件中设置:AlertScriptsPath=/usr/local/zabbix/bin/
 二:添加zabbix用户和组,设置其邮箱地址等信息
二:添加zabbix用户和组,设置其邮箱地址等信息
1、打开zabbix的管理--->用户--->选择用户组下拉--->create user group:
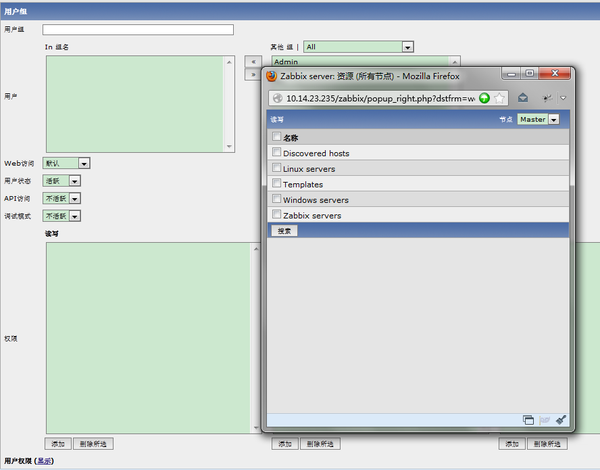
这里主要就是写下组名,设置自己需要的权限然后保存就可以了。
2、打开zabbix的管理--->用户--->选择用户下拉--->create user:
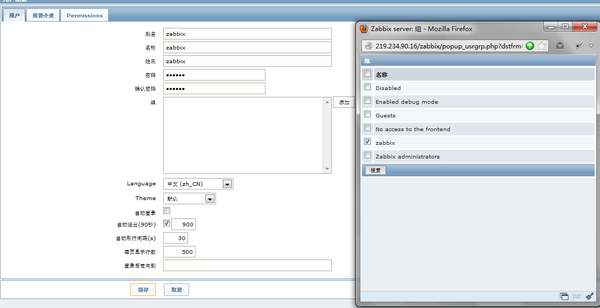
设置好组与用户后就要添加报警介质,其实就是报警方式,由于设置的是报警,所以 “信息" 那项就不用勾选,信息一般就是服务器信息发生变化时报警,这个一般没有什么意义,所以不勾选。
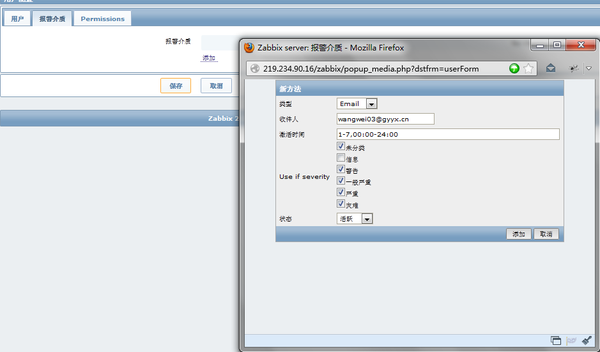 三、报警触发器触发的动作设置
三、报警触发器触发的动作设置
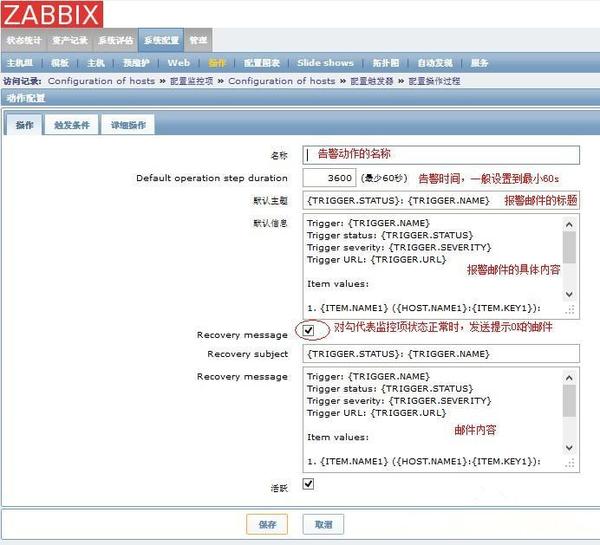
此步操作的意义是,当监控项中的触发器达到你设置的报警值之后,需要执行操作来发送邮件等动作。具体操作如下。
1、打开zabbix的系统配置--->操作--->选择事件源为触发器--->create action:
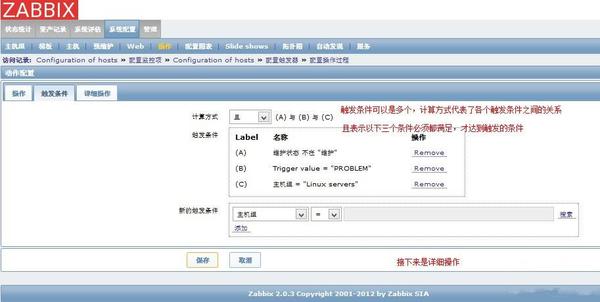
 2、配置出发条件
2、配置出发条件
 3、详细操作设置
3、详细操作设置
即满足触发条件之后执行的动作,这里一般设置为发邮件之类的,设置收邮件的用户时,建议每个组对应一个用户,这样发邮件的时候容易设置发送对象。

到这里告警的设置工作就完成了。
说了这么多 Zabbix 监控和告警的配置,我想聊一下在使用 Zabbix 过程中的一些感受吧。
Zabbix 功能特点:
- 自动发现服务器和网络设备
- 分布式监控网络,集中式管理(agent 、server 分开)
- 监控指标模版丰富
- 可灵活地分配用户权限
Zabbix 不足
- 安装配置相对比较复杂,后期维护成本高
- 数据是只读的、不能对监控数据进行聚合
- 告警机制不够灵活 :不同的指标需要不同的脚本;告警渠道单一
- 不同的监控需求,需要不同的脚本来完成
使用报警聚合工具,聚合报警
如果机器数量成长到一定规模的时候,会发现根本来不及处理报警。人力部门又不给力,迟迟找不上来人。
好在国外有一些报警聚合服务,
pagerduty、
bigpanda 等等。
这类工具主要功能是实现了在一个平台中接收所有监控系统的告警,从而实现报警聚合的服务,让运维人员集中处理IT事件,避免多平台切换,提升运维效率。同时只需要少于 15分钟的时间就可以将Nagios、Zabbix等主流监控平台的告警自动整合进来,而无需其它配置。以Bigpanda为例我们可以看下他集成的监控平台

与此同时 bigpanda 会将大量重复的告警事件压缩为一条有真正意义的告警。而后通过机器学习等算法把相关的告警合并起来,为运维人员提供分析、甄选之后的最重要的告警。
从这些角度来看,国外在监控领域的发展已经从 Zabbix 这种 1.0 时代 ,进入一体化监控解决方案 的 2.0 时代。他们开始选择基于
StatsD 技术的监控工具或解决方案。例如
Datadog
、
Boundary 等第三方监控服务提供商。
这些公司的理念就是为了提供一个一体化的解决方案:如何集成不同的操作系统、数据库、中间件监控的问题,你不需要担心;用就行了。
监控聚合 + 报警聚合
由于 Zabbix 的监控是针对每一台主机的某一项指标来设置报警,并通过模板来快速创建报警。如果想要将一组机器的 CPU 利用率,或者管理集群来报警,就得自己写脚本了。
有没有聚合数据来监控,从而报警自然而然也是聚合的方案呢?
就国内来说我试用过的
Cloudinsight
产品还是不错的,它是利用 Statsd 和 OpenTSDB 实现的一个一体化的监控解决方案。由于其利用到了时间序列数据库,所以数据不再是只读的可以进行聚合分组等功能,这样一来就从不同的数据源中聚合数据,转交给报警处理引擎;引擎根据报警策略中设置的报警条件,对某一固定时间窗口内,对数值进行检查。当引擎检查时间窗口内的数值满足条件时,触发报警事件的生成;并流送至
Cloudinsight 事件流、邮件、
OneAlert 等不同的渠道,进行分发,通知用户。
楼主提出的这个问题,我认为可能是刚刚开始接触运维监控这个领域,所以不妨试一下 CloudInsight 。由于其安装简便,一切就只有两步,安装探针,查看仪表盘。这样就可以进行快速的试错,同时Cloudinsight 集成了数十种互联网流行基础组件的监控,只需要进行最小化的配置就可以实现复杂的基础组件监控, 免除了传统基础组件监控中的复杂流程。这样就可以看看新的技术发展是否能够更好地满足自己的需求。

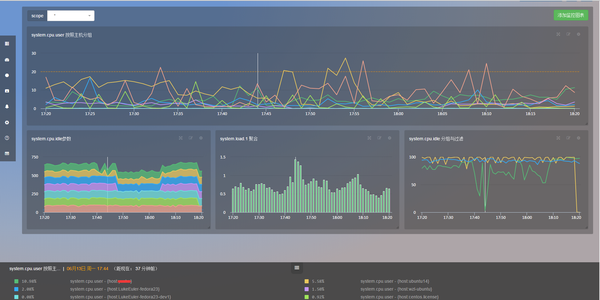
由于平时比较喜欢新鲜事物所以就试用了下,它的可视化效果还是不错的,下面给大家截几张图看看。
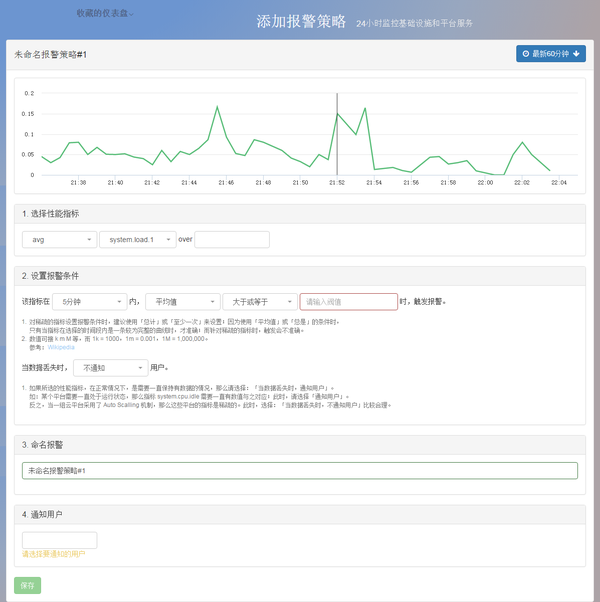
总结一下吧,我认为随着现在云计算的不断发展,服务的模式一定会是未来发展的趋势吧,就像云主机一样以 IaaS 服务代替了一部分传统物理主机与 IDC 的市场份额。照这样的形式来看在监控领域像 Datadog、Boundary、Cloudinsight这种 SaaS 监控服务也会是未来的一种风向标吧。