标签:
前言:
有一家印刷企业专为米兰新娘,微微新娘,金夫人这样的影楼印刷婚纱相册。通过一个B2B销售终端软件,把影楼的相片上传到印刷公司的服务器,服务器对这些图片进行处理。
比如:
1)为每个图片生成订单条码,生产码;
2)为每个图片进行色彩修正,图像处理(拉长腿,去红眼,去色斑等功能),其中用到了Perfectly Clear商业组件。^_^
3)把属于一本相册的所有图片转换为一个PDF文件。
4)用Enfocus Switch软件,检测PDF的完整性。
5)把生成PDF的文件合成上10G的PDF文件(今天要说的也是这儿),方便印刷机台的操作。
6)……
方法:
处理:对PDF的处理,有一个比较牛的插件叫iTextSharp。这儿用这个插件对PDF文件进行文档合并。这个插件是用C++开发的,但是有Java版,C#版。
测试环境:
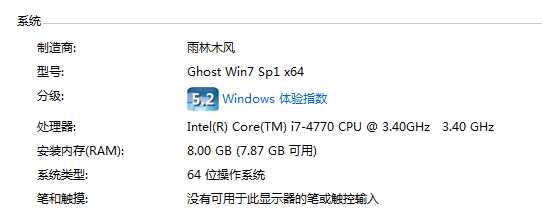
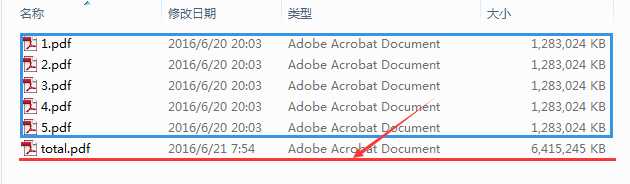
测试数据(把5个1.2G的PDF合并为一个6G的PDF):
合并代码:
Java版:
/**********************************************************/ import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.util.ArrayList; import java.util.List; import com.lowagie.text.Document; import com.lowagie.text.DocumentException; import com.lowagie.text.pdf.PdfContentByte; import com.lowagie.text.pdf.PdfImportedPage; import com.lowagie.text.pdf.PdfReader; import com.lowagie.text.pdf.PdfWriter; public class ItextMerge { public static void main(String[] args) { List<InputStream> list = new ArrayList<InputStream>(); try { // Source pdfs list.add(new FileInputStream(new File("f:/1.pdf"))); list.add(new FileInputStream(new File("f:/2.pdf"))); // Resulting pdf OutputStream out = new FileOutputStream(new File("f:/result.pdf")); doMerge(list, out); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (DocumentException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } /** * Merge multiple pdf into one pdf * * @param list * of pdf input stream * @param outputStream * output file output stream * @throws DocumentException * @throws IOException */ public static void doMerge(List<InputStream> list, OutputStream outputStream) throws DocumentException, IOException { Document document = new Document(); PdfWriter writer = PdfWriter.getInstance(document, outputStream); document.open(); PdfContentByte cb = writer.getDirectContent(); for (InputStream in : list) { PdfReader reader = new PdfReader(in); for (int i = 1; i <= reader.getNumberOfPages(); i++) { document.newPage(); //import the page from source pdf PdfImportedPage page = writer.getImportedPage(reader, i); //add the page to the destination pdf cb.addTemplate(page, 0, 0); } } outputStream.flush(); document.close(); outputStream.close(); } } /*********************************************/
C#版:
private void Button_Click(object sender, RoutedEventArgs e) { Stopwatch sw1 = new Stopwatch(); sw1.Start(); string[] pdfList = new string[5]; pdfList[0] = @"D:\PDF文件合并\Test\1.pdf"; pdfList[1] = @"D:\PDF文件合并\Test\2.pdf"; pdfList[2] = @"D:\PDF文件合并\Test\3.pdf"; pdfList[3] = @"D:\PDF文件合并\Test\4.pdf"; pdfList[4] = @"D:\PDF文件合并\Test\5.pdf"; //pdfList[5] = @"D:\PDF文件合并\Test\6.pdf"; //pdfList[6] = @"D:\PDF文件合并\Test\7.pdf"; //pdfList[7] = @"D:\PDF文件合并\Test\8.pdf"; //pdfList[8] = @"D:\PDF文件合并\Test\9.pdf"; //pdfList[9] = @"D:\PDF文件合并\Test\10.pdf"; mergePDFFiles(pdfList); sw1.Stop(); string xx = sw1.ElapsedMilliseconds.ToString(); //116715 } void mergePDFFiles(string[] pdfList) { string mergePDFFiles = @"D:\PDF文件合并\Test\total.pdf"; Document DOC = new Document(); //getInstance PdfWriter writer = PdfWriter.GetInstance(DOC, new FileStream(mergePDFFiles, FileMode.Create)); DOC.Open(); PdfContentByte cb = writer.DirectContent; PdfImportedPage newPage; for (int i = 0; i < pdfList.Length; i++) { PdfReader reader = new PdfReader(pdfList[i]); int iPageNum = reader.NumberOfPages; for (int j = 1; j <= iPageNum; j++) { DOC.NewPage(); //DOC.newPage(); newPage = writer.GetImportedPage(reader, j); //newPage = writer.getImportedPage(reader, j); cb.AddTemplate(newPage, 0, 0); //cb.addTemplate(newPage, 0, 0); } } DOC.Close(); }
合并结果:
116毫秒,合并6G文件。
分享6个一流PPT资源:http://www.cnblogs.com/xcj26/p/5590647.html 。
有东西,全部分享了,放在硬盘里没用。
标签:
原文地址:http://www.cnblogs.com/xcj26/p/5602402.html