标签:
这篇文章主要关注的是资源加载之后的性能,因为大多数用户关注的不是应用如何加载而是具体的使用。所以要快速响应用户,尤其是无线端,我们有必要了解浏览器渲染性能。
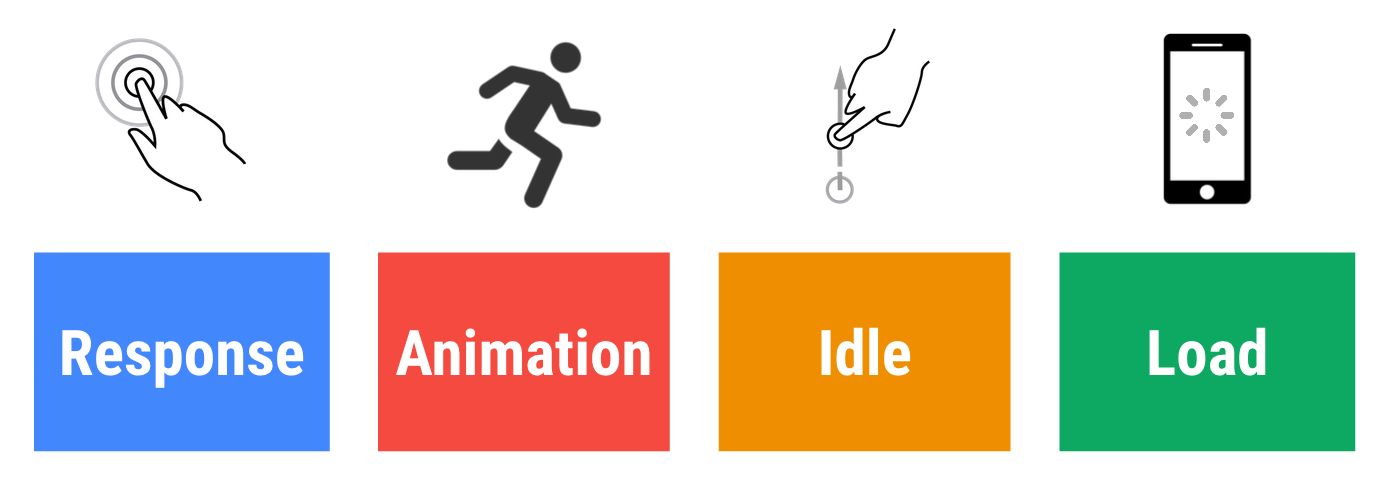
首先一个需要思考的问题,怎样的网站是顺畅的?我们可能可以给一个大概的感觉,如:秒级响应等。其实,也可以给出一个很讨巧的答案:用户觉得顺畅的网站它就是顺畅的。因为几乎所有网站都希望将用户留在页面上,当然以用户为中心建立性能模型是必要的。下面是 Google 提出的一个以用户为中心的性能模型,里面的数据不是 Google 首创,有一些论文做类似研究(如:100ms 响应用户是一个很合适的时间等)。
上图是 RAIL 的具体含义,这里有一些关键性的数据指标:
应用要达到上面的性能模型需要从哪些方面入手呢?如果我们知道浏览器是如何渲染一个页面的,并且去优化渲染过程中的关键步骤,是不是就能事半功倍呢?
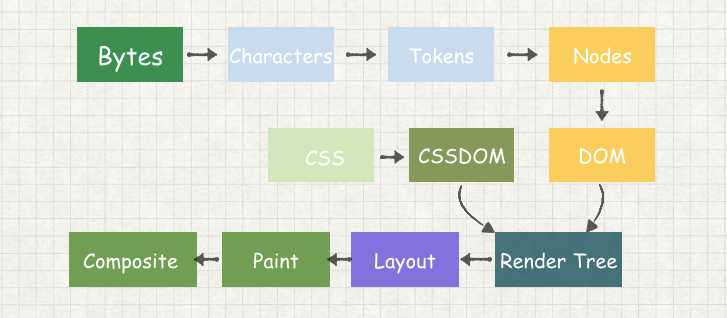
上图是浏览器渲染的关键路径,首先,让我们从浏览器解析一个页面开始吧。
如果我们是做一个动画,一般会用 JS 更改相应样式,接着浏览器就会经历 JS 运行、样式计算、布局、绘制、合成等多个重要步骤(后面还会讲到这个步骤实际过程中可以更长或者更短)。那么要做的优化就是在这几个步骤中进行优化并且尽量去掉中间的耗时步骤。
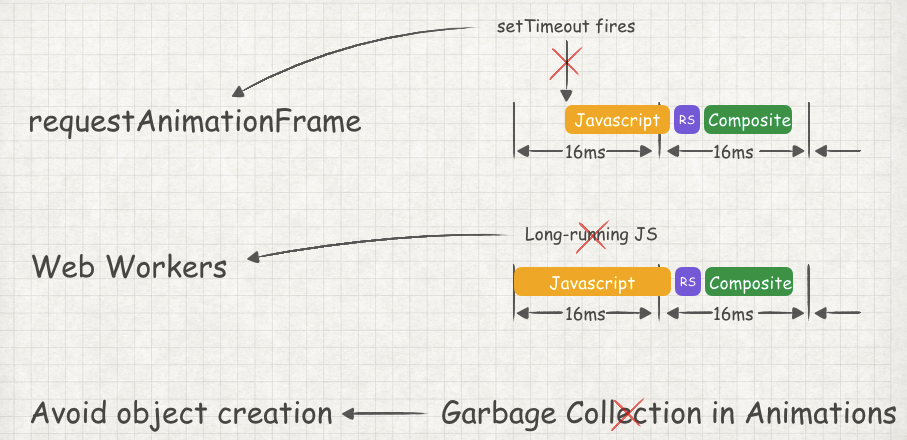
上图描述的四个场景都是有可能对响应用户输入或者动画造成影响的。函数的输入事件处理、不合时机的 JS 、长时间的 JS 运行以及垃圾回收。
首先,我们要知道的一个事实就是浏览器是由多个处理进程的:Compositor、Tile Worker、Main。当用户进行输入操作(滚动、点击等),如滚动时,Compositor 进程会接收到这个事件(实际它可以接受任何用户输入事件),如果可以的话,它将不会通知主进程,直接说:滚吧,牛宝宝。于是,页面就滚动了。当然,这其中包含更新层定位以及让 GPU 绘制帧,而主线程处于空闲状态。但是,事情往往并非如此。如果输入事件上绑定了 JS 处理事件的话,Compositor 进程就没办法主动跳过主进程了。
如上图,当 JS 处理事件过长时,输入事件的响应会一直处于阻塞状态,直到 JS 处理完成。当响应超过 100ms 时,用户就会感受到延时。所以当处理用户事件时,我们应该做到:
其他优化:
添加或移除一个 DOM 元素、修改元素属性和样式类、应用动画效果等操作,都会引起 DOM 结构的改变,从而导致浏览器需要重新计算每个元素的样式、对页面或其一部分重新布局(多数情况下)。
计算样式的第一步是创建一套匹配的样式选择器,浏览器就是靠它们来对一个元素应用样式的。第二步是根据匹配的样式选择器来获取对应的具体样式规则,计算出最终具体有哪些样式是要应用在 DOM 元素上的。所以样式的优化也是这两步:
如何减小选择器的复杂性?
.box:nth-last-child(-n+1) .title {
/* styles */
}
.final-box-title {
/* styles */
}
上面代码都是选择同一个元素,当元素很多时,第二个选择器的性能会明显优于第一个。BEM 规范有做类似事情,按照特性直接由一个选择器选择元素的性能往往会更优。
因为元素的计算量和被改变的元素的数量成正比,所以你只需要注意一点,减少无效元素。
<div>
<div>
<p>多层无意义的标签</p>
</div>
</div>
像上面的例子,有时候创建了一些冗余的标签。当改变外层的样式时,冗余的标签也需要进行样式计算,浪费性能。
浏览器计算 DOM 元素的几何信息的过程:元素大小和在页面中的位置。每个元素都有一个显式或隐式的大小信息,决定于其 CSS 属性的设置、或是元素本身内容的大小、或者是其父元素的大小。在 Blink/WebKit 内核的浏览器和 IE 中,这个过程称为 Layout。在基于 Gecko 的浏览器(比如 Firefox)中,这个过程称为 Reflow。
目前,transform 和 opacity 只会引起合成,不会引起布局和重新绘制。整个流程中比较耗费性能的布局和绘制流程将直接跳过,性能显然是很好的。其他的 CSS 属性改变引起的流程会有所不同,有些属性也会跳过布局,具体可以查看 CSS Triggers。所以,优化的第一步就是尽可能避免触发布局。
Flexbox 布局方案性能会优于以前的布局方案,而且目前浏览器对 Flexbox 支持度相当高了:
首先是执行 JS 脚本,然后是样式计算,然后是布局。但是,我们还可以强制浏览器在执行 JS 脚本之前先执行布局过程,这就是所谓的强制同步布局。在 JS 脚本运行的时候,它能获取到的元素样式属性值都是上一帧画面的,都是旧的值。因此,如果你想在这一帧开始的时候,读取一个元素的 height 属性,你可以会写出这样的 JS 代码:
function logBoxHeight() {
box.classList.add(‘super-big‘);
// Gets the height of the box in pixels
// and logs it out.
console.log(box.offsetHeight);
}
为了给你返回 box 的 height 属性值,浏览器必须首先应用 box 的属性修改(因为对其添加了 super-big 样式),接着执行布局过程。在这之后,浏览器才能返回正确的 height 属性值。这样就造成了同步布局事件,是非常消耗性能的。大多数情况下,你应该都不需要先修改然后再读取元素的样式属性值,使用上一帧的值就足够了。过早地同步执行样式计算和布局是潜在的页面性能的瓶颈之一。
function logBoxHeight() {
// Gets the height of the box in pixels
// and logs it out.
console.log(box.offsetHeight);
box.classList.add(‘super-big‘);
}
还有一种情况比强制同步布局更糟:连续快速的多次执行它。
function resizeAllParagraphsToMatchBlockWidth() {
// Puts the browser into a read-write-read-write cycle.
for (var i = 0; i < paragraphs.length; i++) {
paragraphs[i].style.width = box.offsetWidth + ‘px‘;
}
}
上述代码对一组段落标签执行循环操作,设置 p 标签的width属性值,使其与 box 元素的宽度相同。看上去这段代码是没问题的,但问题在于,在每次循环中,都读取了 box 元素的一个样式属性值,然后立即使用该值来更新 p 元素的 widt h属性。在下一次循环中读取 box 元素 offsetwidth 属性的时候,浏览器必须先使得上一次循环中的样式更新操作生效,也就是执行布局过程,然后才能响应本次循环中的样式读取操作。布局过程将在每次循环中发生。优化代码:
// Read.
var width = box.offsetWidth;
function resizeAllParagraphsToMatchBlockWidth() {
for (var i = 0; i < paragraphs.length; i++) {
// Now write.
paragraphs[i].style.width = width + ‘px‘;
}
}
如果你想确保编写的读写操作是安全的,你可以使用 FastDOM。它能帮你自动完成读写操作的批处理,还能避免意外地触发强制同步布局或快速连续的布局。
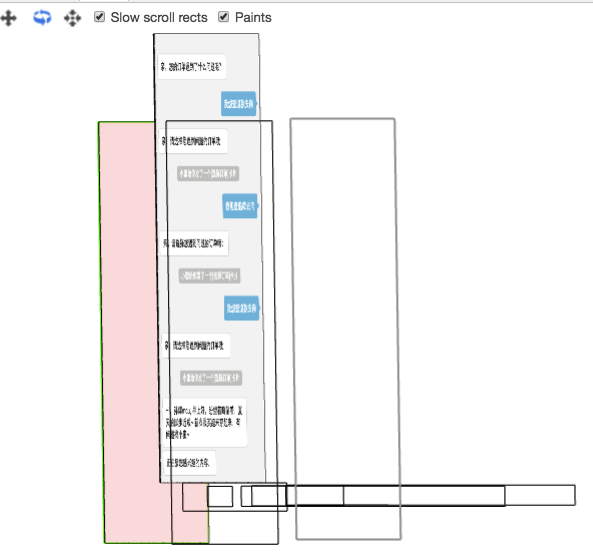
绘制并非总是在内存中的单层画面里完成的。实际上,浏览器在必要时将会把一帧画面绘制成多层画面,然后将这若干层画面合并成一张图片显示到屏幕上。通过渲染层提升可以减小绘制区域,我们可以用调试工具查看到绘制层:
在页面中新建一个渲染层最好的方式就是使用 will-change 属性,同时再与 transform 属性一起使用,就会创建一个新的组合层:
.element {
will-change: transform;
}
对于那些目前还不支持 will-change 属性、但支持创建渲染层的浏览器,可以使用一个 3D transform 属性来强制浏览器创建一个新的渲染层:
.element {
transform: translateZ(0);
}
注意: 别盲目创建渲染层,一定要分析其实际性能表现。因为创建渲染层是有代价的,每创建一个新的渲染层,就意味着新的内存分配和更复杂的层的管理。并且在移动端 GPU 和 CPU 的带宽有限制,创建的渲染层过多时,合成也会消耗跟多的时间。
有时候,尽管把元素提升到了一个单独的渲染层,浏览器会把两个相邻区域的渲染任务合并在一起进行,这将导致整个屏幕区域都会被绘制。所以可以使用调试工具查看,仔细规划动画。
不同的 CSS 属性绘制的成本是不一样的,绘制一个阴影就比绘制边框更费时。当然,这个浏览器也在不停优化中,现在的耗时渲染属性随时都可能被改变,所以需要多关注一下。
渲染层的合并,就是把页面中完成了绘制过程的部分合并成一层,然后显示在屏幕上。下面和合成相关的两点前面也有提到过。
前面已经提到过 transform/opacity 的优势,应用了 transforms/opacity 属性的元素必须独占一个渲染层。为了对这个元素创建一个自有的渲染层,你必须提升该元素。
创建一个新的渲染层需要消耗额外的内存和管理资源。而在内存资源有限的设备上,由于过多的渲染层来带的开销而对页面渲染性能产生的影响,甚至远远超过了它在性能改善上带来的好处。由于每个渲染层的纹理都需要上传到 GPU 处理,因此我们还需要考虑 CPU 和 GPU 之间的带宽问题、以及有多大内存供 GPU 处理这些纹理的问题。
标签:
原文地址:http://www.cnblogs.com/ppforever/p/5602567.html