标签:
目标:简单了解框架、技术(算法)、通过storyflow了解可视化技术。细读
StoryFlow:
特点:实时可交互、美观、展现实体层次关系,并且通过细节层次绘制(LOD)来解决了大量线条存在的干扰与性能下降问题。
解决方案:看为一个最优解问题,结合离散(discrete)和连续最优化方法的混合最优策略。离散策略通过排序(ordering)、校准(aligning)线实体来创建最初的故事流布局(layout)。连续策略则是基于二次凸优化(quadratic convex optimization)来优化故事流布局。
背景:最早是出现在Munroe绘制的电影叙事流程上,在于展示一个故事发展过程中各个实体之间的关系。线条比较近的则是故事中角色在相同地点或者背景下。
(基于故事线的可视化,是将不同的人物利用线来表示,横轴表示时间,当两人有某种联系(同时出场、有交集等)会在一定的时间范围内相邻,这种方法最早见于手绘xkcd的项目。之后UC Davis的Tanahashi等人成功地将storyline的形式用计算机自动生成,并符合一些美学的标准,可以处理例如《李尔王》等复杂情节故事的可视化。但之前的工作具有以下的一些值得研究的问题,例如视觉美观和生成时间两者是一个矛盾权衡,如果要生成美观的图片,以前的方法都会耗时很久(对一部复杂的小说大概几十个小时),无法做到交互,但往往支持实时交互的作品却难以得到满意的视觉效果。还有就是之前的一些工作并没有考虑对象的层次性,例如地域的层次性(国家、省、市),而仅仅是扁平化的人物关系。并且当线条多了以后容易造成遮挡(Clutter),也并不可扩展。)[1]
Storyflow在整个可视化设计中主要考虑三点:1.线的交叉(crossing);2.线的摆动(wiggle);3.摇摆距离(wiggle distance)和空白区域(white space)
整个系统工作流程如下:
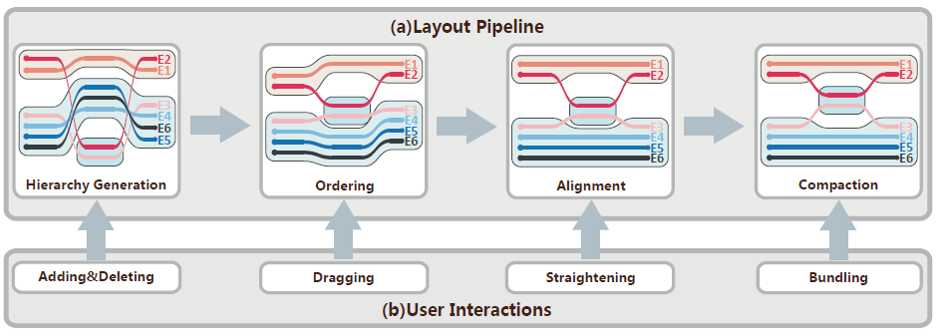
首先系统输入是一个XML文件,包含session表,地点树(location tree).session表存储实体之间的动态关系,地点树描述地点的层次关系。
接下来
1.基于每个时间帧生成关系树。
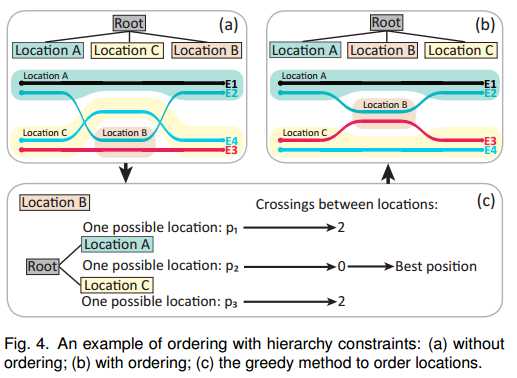
2.排序(ordering),
贪心算法排序地点节点:基本想法是在相同父节点在的子节点,首先放具有最多实体(Entity)的节点,接下来就从下至上每一步都选择最小交叉的地方放置。不考虑整体最优。复杂度o(n);
接下来session和entity排序则是相当于DAG的扫描算法(directed acyclic graph sweeping algorithm)。首先首先结算第一时间帧的初始排序,接着作为第二时间帧的输入,循环迭代到最后一步的结果作为第一步的结果重新迭代,直至线交叉的数量一定或者达到最大循环次数。在每步sweep中,采用重心在计算树节点权值。
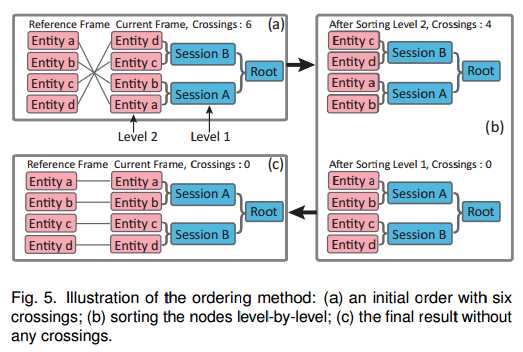
初始交叉数为6(3+2+1),在第一步排序中,先把dc,ba对调,则交叉数减到了4(2+2),第二步,排序session,B的权值是3.5((4+3)/2),A的权值是1.5((1+2)/2),所以对调。最后结果如c所示,交叉数为0;
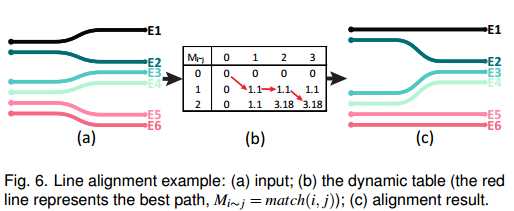
3.校准(Alignment)
计算每个段之间的相似度,类似于LCS问题/最长公共子序列问题。
通过动态规划解决。
4.压缩(Compaction)
减少摇摆距离和空白区域。
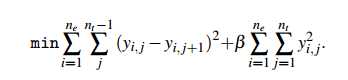
转换为一个线性约束二次规划问题【这个地方其实没太看懂,准备复习下这些算法。。全忘了】
在后面也对用户之间交互提供了很多增删改查的操作。
在文章最后也对storyFlow进行了案例分析,这个具体可以看中文介绍那一篇。
参考内容:
[1]中文简介来源文章:http://vis.pku.edu.cn/blog/storyflow-%E8%BF%BD%E8%B8%AA%E6%95%85%E4%BA%8B%E7%9A%84%E5%8F%91%E5%B1%95%E8%84%89%E7%BB%9C%EF%BC%88storyflow%EF%BC%9Atracking-the-evolution-of-stories%EF%BC%89/
[2]StoryFlow主页:http://storyflow.net/
[3]Liu S, Wu Y, Wei E, et al. Storyflow: Tracking the evolution of stories[J]. Visualization and Computer Graphics, IEEE Transactions on, 2013, 19(12): 2436-2445.
StoryFlow: Tracking the Evolution of Stories-1.可视化文献阅读
标签:
原文地址:http://www.cnblogs.com/Zhich/p/5591646.html