标签:
介绍:
RDD--Resilient Distributed Dataset
Spark中RDD是一个不可变的分布式对象集合。每个RDD被分为多个分区,这些分区运行在集群的不同的节点上。
RDD可以包含Python、Java、Scala中的任意类型的对象,以及自定义的对象。
创建RDD的两种方法:
1 读取一个数据集(SparkContext.textFile()) : lines = sc.textFile("README.md")
2 读取一个集合(SparkContext.parallelize()) : lines = sc.paralelize(List("pandas","i like pandas"))
RDD的两种操作:
1 转化操作(transformation) : 由一个RDD生成一个新的RDD
2 行动操作(action) : 对RDD中的元素进行计算,并把结果返回
RDD的惰性计算:
可以在任何时候定义新的RDD,但Spark会惰性计算这些RDD。它们只有在第一次行动操作中用到的时候才会真正的计算。
此时也不是把所有的计算都完成,而是进行到满足行动操作的行为为止。
lines.first() : Spark只会计算RDD的第一个元素的值
常见的转化操作:
对一个RDD的转化操作:
原始RDD:
scala> val rdd = sc.parallelize(List(1,2,3,3)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
map() : 对每个元素进行操作,返回一个新的RDD
scala> rdd.map(x => x +1 ).collect() res0: Array[Int] = Array(2, 3, 4, 4)
flatMap() : 对每个元素进行操作,将返回的迭代器的所有元素组成一个新的RDD返回
scala> rdd.flatMap(x => x.to(3)).collect() res2: Array[Int] = Array(1, 2, 3, 2, 3, 3, 3)
filter() : 最每个元素进行筛选,返回符合条件的元素组成的一个新RDD
scala> rdd.filter(x => x != 1).collect() res3: Array[Int] = Array(2, 3, 3)
distinct() : 去掉重复元素
scala> rdd.distinct().collect() res5: Array[Int] = Array(1, 2, 3)
sample(withReplacement,fration,[seed]) : 对RDD采样,以及是否去重
第一个参数如果为true,可能会有重复的元素,如果为false,不会有重复的元素;
第二个参数取值为[0,1],最后的数据个数大约等于第二个参数乘总数;
第三个参数为随机因子。
scala> rdd.sample(false,0.5).collect() res7: Array[Int] = Array(3, 3) scala> rdd.sample(false,0.5).collect() res8: Array[Int] = Array(1, 2) scala> rdd.sample(false,0.5,10).collect() res9: Array[Int] = Array(2, 3)
对两个RDD的转化操作:
原始RDD:
scala> val rdd1 = sc.parallelize(List(1,2,3)) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[13] at parallelize at <console>:27 scala> val rdd2 = sc.parallelize(List(3,4,5)) rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[14] at parallelize at <console>:27
union() :合并,不去重
scala> rdd1.union(rdd2).collect() res10: Array[Int] = Array(1, 2, 3, 3, 4, 5)
intersection() :交集
scala> rdd1.intersection(rdd2).collect() res11: Array[Int] = Array(3)
subtract() : 移除相同的内容
scala> rdd1.subtract(rdd2).collect() res12: Array[Int] = Array(1, 2)
cartesian() :笛卡儿积
scala> rdd1.cartesian(rdd2).collect() res13: Array[(Int, Int)] = Array((1,3), (1,4), (1,5), (2,3), (2,4), (2,5), (3,3), (3,4), (3,5))
常见的行动操作:
原始RDD:
scala> val rdd = sc.parallelize(List(1,2,3,3)) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27
collect() :返回所有元素
scala> rdd.collect() res14: Array[Int] = Array(1, 2, 3, 3)
count() :返回元素个数
scala> rdd.count() res15: Long = 4
countByValue() : 各个元素出现的次数
scala> rdd.countByValue() res16: scala.collection.Map[Int,Long] = Map(1 -> 1, 2 -> 1, 3 -> 2)
take(num) : 返回num个元素
scala> rdd.take(2) res17: Array[Int] = Array(1, 2)
top(num) : 返回前num个元素
scala> rdd.top(2) res18: Array[Int] = Array(3, 3)
takeOrdered(num)[(ordering)] :按提供的顺序,返回最前面的num个元素(需要好好再研究一下)
scala> rdd.takeOrdered(2) res28: Array[Int] = Array(1, 2) scala> rdd.takeOrdered(3) res29: Array[Int] = Array(1, 2, 3)
takeSample(withReplacement,num,[seed]) :采样
scala> rdd.takeSample(false,1) res19: Array[Int] = Array(2) scala> rdd.takeSample(false,2) res20: Array[Int] = Array(2, 3) scala> rdd.takeSample(false,2,20) res21: Array[Int] = Array(3, 3)
reduce(func) :并行整合RDD中的所有数据(最常用的)
scala> rdd.reduce((x,y) => x + y) res22: Int = 9
aggregate(zeroValue)(seqOp,combOp) :先使用seqOp将RDD中每个分区中的T类型元素聚合成U类型,再使用combOp将之前每个分区聚合后的U类型聚合成U类型, 特别注意seqOp和combOp都会使用zeroValue的值,zeroValue的类型为U
scala> rdd.aggregate((0,0))((x, y) => (x._1 + y, x._2 +1), (x,y) => (x._1 + y._1, x._2 + y._2)) res24: (Int, Int) = (9,4)
fold(zero)(func) :将aggregate中的seqOp和combOp使用同一个函数op
scala> rdd.fold(0)((x, y) => x + y) res25: Int = 9
foreach(func):对每个元素使用func
scala> rdd.foreach(x => println(x*2)) 4 6 6 2
持久化:
因为RDD是惰性求值的,有时我们需要多次使用同一个RDD,为了避免多次计算同一个RDD,可以让Spark对数据进行持久化。
用persist()把数据以序列化的形式缓存到JVM的堆空间中(先序列化再做其他操作)
持久化级别
org.apache.spark.storage.StorageLevel中的持久化级别,想保存两份持久化数据的话,在持久化级别末尾加上"_2"
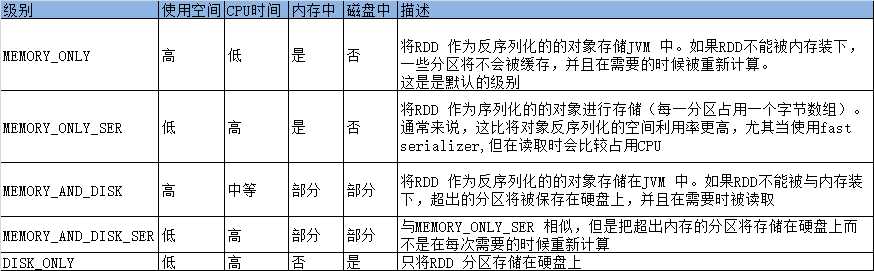
如果缓存的数据太多,内存不足的话,spark会利用LRU策略把老的分区从内存中移除,对于使用存放在内存中的缓存级别,下次再使用这些数据需要从新计算,
对于使用内存和磁盘的缓存级别,移除的分区会写入磁盘。
scala> val result = rdd.map(x => x * x)
result: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[36] at map at <console>:29
scala> result.persist(org.apache.spark.storage.StorageLevel.DISK_ONLY)
res30: result.type = MapPartitionsRDD[36] at map at <console>:29
scala> println(result.count())
4
scala> println(result.collect())
[I@381d7867
scala> println(result.collect().mkString(","))
1,4,9,9
最后,用unpersist()手动把持久化的RDD从缓存中移除。
参照于《Spark快速大数据分析》
标签:
原文地址:http://www.cnblogs.com/grufield/p/5608818.html