标签:
1、python 函数式+面向对象
2、函数式编程,面向对象编程实现:发送邮件的功能
# 函数
def mail(email, message):
print("去发吧")
return True
mail("alex3714@126.com", "好人")
面向对象:类,对象
class Foo:
# 方法
def mail(self, email, message):
print(‘去发吧‘)
return True
# 调用
1、创建对象,类名()
obj = Foo()
2、通过对象去执行方法
obj.mail("alex3714@126.com", "好人")
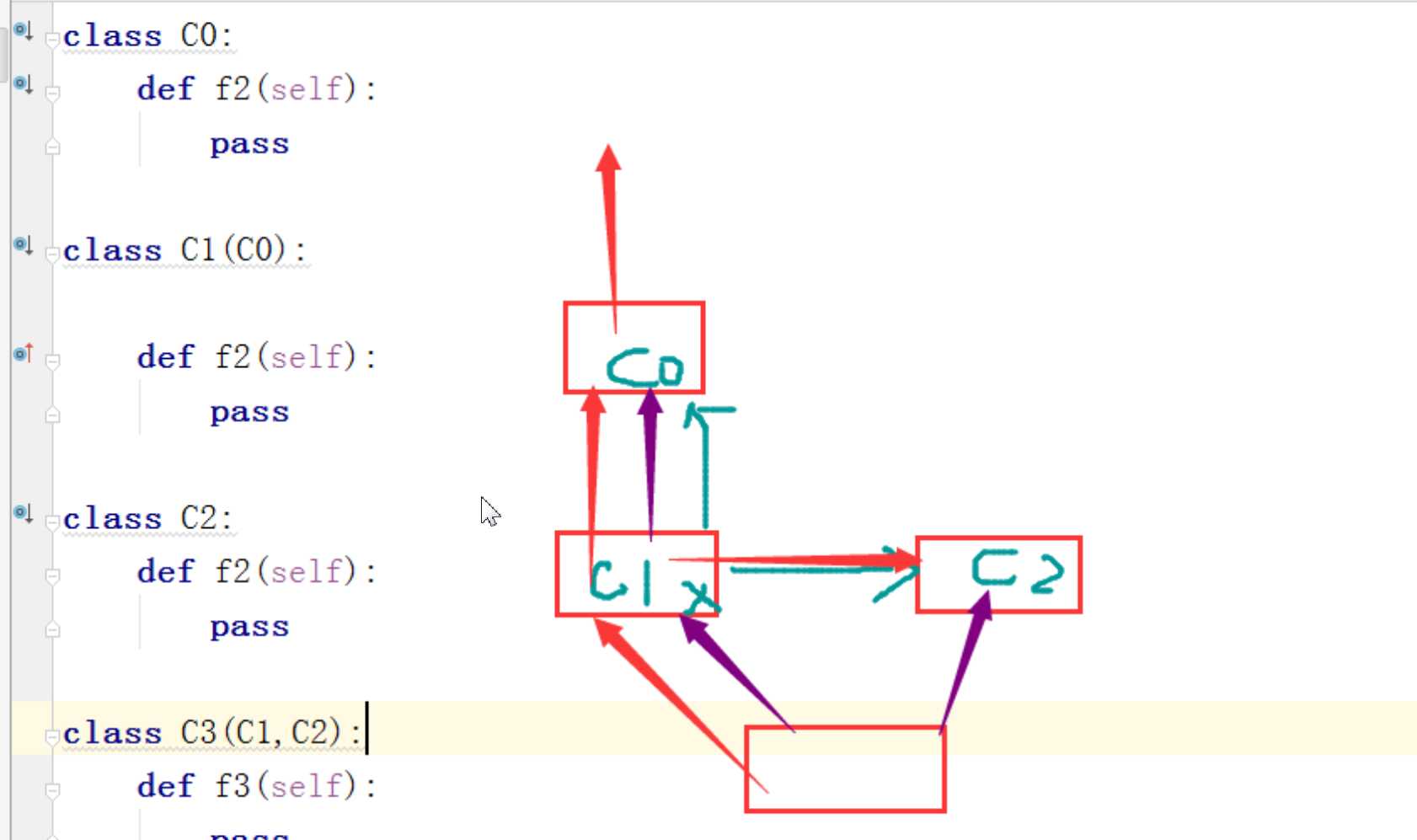
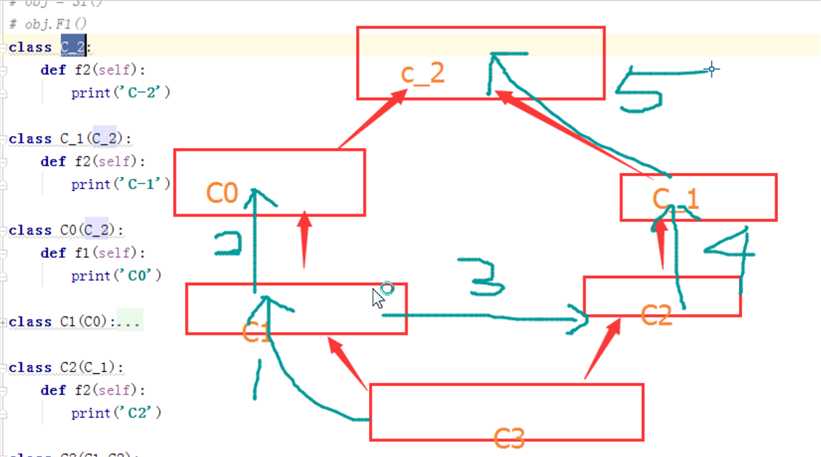
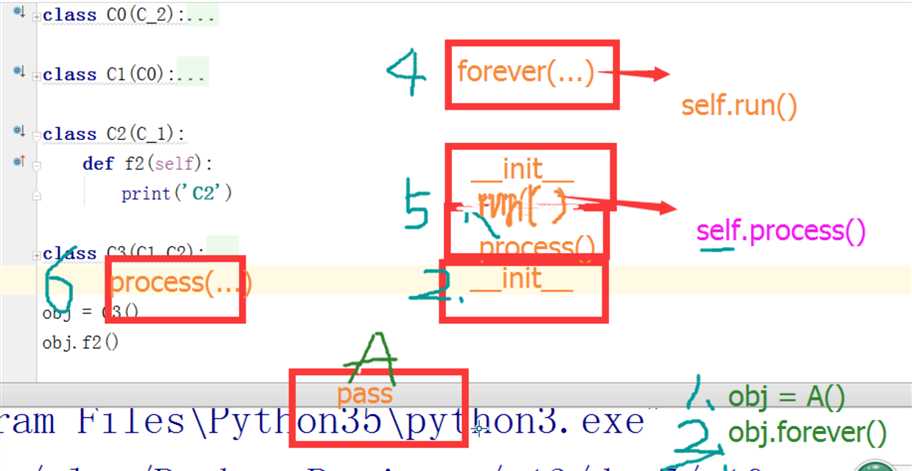
3、类和对象
a. 创建类
class 类名:
def 方法名(self,xxxx):
pass
b. 创建对象
对象 = 类名()
c. 通过对象执行方法
对象.方法名(123)
4、函数式 与 面向对象 对比
函数式:
def fetch(host, username, password, sql):
pass
def create(host, username, password, sql):
pass
def remove(host, username, password, nid):
pass
def modify(host, username, password, name):
pass
...
fetch(....)
面向对象:
class SQLHelper:
def fetch(self, sql):
pass
def create(self, sql):
pass
def remove(self, nid):
pass
def modify(self, name):
pass
obj1 = SQLHelper() #下面三个动态字段封装到obj1对象中,就等于self中封装了这三个值
obj1.hhost = "c1.salt.com"
obj1.uuserane = "alex"
obj1.pwd = "123"
obj1.fetch("select * from A")
obj2 = SQLHelper()
obj2.hhost = "c2.salt.com"
obj2.uuserane = "alex"
obj2.pwd = "123"
obj2.fetch("select * from A")
一. 模块
上一期博客里列出了几个常用模块(os,hashlib,sys,re), 还有几个剩余的,这篇来继续往下走。
1. configparser模块
configparser模块是Python自带模块,主要用于处理特定的文件(ini文件),格式比较像MySQL的配置文件类型,就是文件中有多个section,每个section下面有多个配置项,如下:

[mysqld] basedir = /usr/local/mysql datadir = /data/mysql socket = /data/mysql/mysql.sock [client] host = localhost port = 3306 socket = /data/mysql/mysqld.sock
假定配置文件名字是 my.cnf
(1)获取所有节点(section):使用sections() 方法
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) import configparser config = configparser.ConfigParser() #先把config应用一下configparser,个人感觉有点像logging模块中的logger一样 config.read(‘my.cnf‘,encoding=‘utf-8‘) #读取配置文件,编码类型为utf-8 result = config.sections() #使用sections()方法读取所有section,以列表形式返回 print(result) #结果 [‘mysqld‘, ‘client‘]
(2)获取指定section下所有键值对:items()方法
import configparser config = configparser.ConfigParser() config.read(‘my.cnf‘,encoding=‘utf-8‘) #使用items() 方法列出指定section下所有的键值对,返回一个列表的形式,key和value列表中的一个tuple result = config.items(‘mysqld‘) print(result) #结果: [(‘basedir‘, ‘/usr/local/mysql‘), (‘datadir‘, ‘/data/mysql‘), (‘socket‘, ‘/data/mysql/mysql.sock‘)]
(3)获取指定节点下所有的键, 使用options() 方法
import configparser config = configparser.ConfigParser() config.read(‘my.cnf‘,encoding=‘utf-8‘) #获取指定section下的所有的键,以列表的形式返回 result = config.options(‘mysqld‘) print(result) #结果: [‘basedir‘, ‘datadir‘, ‘socket‘]
(4)获取指定节点下键的值, 使用get() 方法
import configparser config = configparser.ConfigParser() config.read(‘my.cnf‘,encoding=‘utf-8‘) #get方法,mysqld节点下socket键 result = config.get(‘mysqld‘,‘socket‘) print(result) #执行结果: /data/mysql/mysql.sock
(5)检查、删除、添加特定section,方法has_section(), add_section(), remove_section()
import configparser config = configparser.ConfigParser() config.read(‘my.cnf‘,encoding=‘utf-8‘) #检查指定的section是否存在,返回一个布尔值,存在为True result = config.has_section(‘mysqld‘) print(result) #结果: True ####################################### #添加节点 mysqldump config.add_section(‘mysqldump‘) config.write(open(‘my.cnf‘,‘w‘)) #需要使用write方法写入内存数据到配置文件中,不然是不能持久化到文件的 result = config.sections() print(result) #执行sections查看添加后结果: [‘mysqld‘, ‘client‘, ‘mysqldump‘] ####################################### #删除节点,mysqldump config.remove_section(‘mysqldump‘) #使用remove()方法 config.write(open(‘my.cnf‘,‘w‘)) #同样默认是在内存中操作,需要调用write方法,将内存数据写入到文件来持久化存储 result = config.sections() print(result) #执行sections查看添加后结果: [‘mysqld‘, ‘client‘ ]
(6) 检查、删除设置section内的key-value
#检查section mysqld下的socket键值对是否存在 import configparser config = configparser.ConfigParser() config.read(‘my.cnf‘,encoding=‘utf-8‘) #使用has_option方法,返回一个布尔值,存在为True result = config.has_option(‘mysqld‘,‘socket‘) print(result) #执行结果: True ##################################### #在mysqld中添加 键 innodb_file_per_table 值为1 #使用set方法 config.set(‘mysqld‘,‘innodb_file_per_table‘,‘1‘) config.write(open(‘my.cnf‘,‘w‘)) #同样需要写入内存数据到文件,使用write方法 result = config.options(‘mysqld‘) print(result) #执行查看结果: [‘basedir‘, ‘datadir‘, ‘socket‘, ‘innodb_file_per_table‘] ##################################### #删除mysqld下的socket键 #使用remove_option()方法 config.remove_option(‘mysqld‘,‘innodb_file_per_table‘) config.write(open(‘my.cnf‘,‘w‘)) #写入内存数据到文件 result = config.options(‘mysqld‘) print(result) #执行查看结果: [‘basedir‘, ‘datadir‘, ‘socket‘]
使用configparser可以方便的对配置文件(ini)进行操作,其实configparser底层也是使用open函数打开文件,然后在此基础上做操作。
2. xml模块
xml在Internet上被广泛的用于数据交换,同时xml也是一种存储应用数据的常用格式。如下xml例子:
<?xml version="1.0"?>
<rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>Planet Python</title>
<link>http://planet.python.org/</link>
<language>en</language>
<description>Planet Python - http://planet.python.org/</description>
<item>
<title>Steve Holden: Python for Data Analysis</title>
<guid>http://holdenweb.blogspot.com/...-data-analysis.html</guid>
<link>http://holdenweb.blogspot.com/...-data-analysis.html</link>
<description>...</description>
<pubDate>Mon, 19 Nov 2012 02:13:51 +0000</pubDate>
</item>
<item>
<title>Vasudev Ram: The Python Data model (for v2 and v3)</title>
<guid>http://jugad2.blogspot.com/...-data-model.html</guid>
<link>http://jugad2.blogspot.com/...-data-model.html</link>
<description>...</description>
<pubDate>Sun, 18 Nov 2012 22:06:47 +0000</pubDate>
</item>
<item>
<title>Python Diary: Been playing around with Object Databases</title>
<guid>http://www.pythondiary.com/...-object-databases.html</guid>
<link>http://www.pythondiary.com/...-object-databases.html</link>
<description>...</description>
<pubDate>Sun, 18 Nov 2012 20:40:29 +0000</pubDate>
</item>
...
</channel>
</rss>
(1) 解析xml
使用XML() 将字符串解析成xml对象
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # Author: DBQ(Du Baoqiang) from xml.etree import ElementTree as ET #打开文件 result_xml = open(‘example.xml‘,‘r‘).read() #将字符串解析成xml特殊对象,root指的是xml文件的根节点 root = ET.XML(result_xml) print(root) #结果, 返回一个Element对象 <Element ‘rss‘ at 0x1018772c8>
使用xml.etree.ElementTree.parse() 函数解析整个xml文件并将其转换成一个文档对象。
tree = ET.parse(‘example.xml‘) root = tree.getroot() print(root) #执行后结果: <Element ‘rss‘ at 0x1019772c8>
(2)操作xml
xml格式类型是节点里嵌套节点 ,所以对于每一个节点都有如下的功能:
 节点功能
节点功能遍历xml文档的所有内容:
遍历xml文档的所有内容遍历xml文档中指定的节点:
遍历xml文档中指定节点link内容修改节点的内容
和上面configparser一样,所做的修改是在内存中进行,并不会对xml原始文档做修改,如果需要保存修改的配置,需要将内存里的数据写入到xml文件中。
也是分两种方式,解析字符串方式的修改保存, 和直接解析文件方式的修改,保存。
解析字符串方式修改保存 解析xml文件方式修改保存删除节点,删除所有节点下的language
解析字符串方式删除节点,保存配置 解析xml文件方式删除节点,保存配置(3) 创建xml文档
方式一 方式二创建 方式三创建默认保存的xml没有缩进,特别的难看,可以按照下面方式添加缩进:
缩进 三种创建方式都一样!(4) 命令空间
命名空间3. shutil模块
shutil是一种高级的文件操作工具,可操作的包括:文件、文件夹、压缩文件的处理。
操作方法:
shutil.copyfileobj(fsrc, fdst, [length=16*1024]) 将文件内容拷贝到另外一个文件
import shutil shutil.copyfileobj(open(‘data.xml‘,‘r‘),open(‘data_new.xml‘,‘w‘)) #将会生成一个data_new.xml文件,内容和data.xml一模一样,有点类似于Shell中的cat data.xml > data_new.xml
shutil.copyfile(src, dst) 直接拷贝文件,如果dst存在的话,会被覆盖掉,谨慎操作。
import shutil
import os
shutil.copyfile(‘data.xml‘,‘data_new2.xml‘)
result = os.listdir(os.path.dirname(__file__))
for i in result:
print(i)
#执行后会在当前目录下生成一个文件
data_new2.xml
shutil.copymode(src, dst) 拷贝文件权限,属主、属组和文件内容均不变。
#先查看文件权限: os.system(‘ls -l data.xml‘) -rw-r--r-- 1 daniel staff 690 Jun 20 19:15 data.xml #查看data_new2.xml权限 os.system(‘ls -l data_new2.xml‘) -rw------- 1 daniel everyone 690 Jun 21 11:40 data_new2.xml #拷贝权限试试 shutil.copymode(‘data.xml‘,‘data_new2.xml‘) os.system(‘ls -l data_new2.xml‘) #结果:权限变成和data.xml一样了,但是属主组这些不变 -rw-r--r-- 1 daniel everyone 690 Jun 21 11:40 data_new2.xml
shutil.copystat(src, dst) 拷贝文件状态信息,状态信息包括: atime , mtime, flags, mode bits
#先查看下两个文件的状态信息: print(os.stat(‘data.xml‘)) print(os.stat(‘data_new2.xml‘)) #执行结果: os.stat_result(st_mode=33188, st_ino=7289084, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466480420, st_mtime=1466421339, st_ctime=1466421339) os.stat_result(st_mode=33188, st_ino=7295271, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=12, st_size=690, st_atime=1466480420, st_mtime=1466480420, st_ctime=1466480490) #拷贝状态信息data.xml到data_new2.xml, 可以看到mtime同步了 os.stat_result(st_mode=33188, st_ino=7289084, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466480420, st_mtime=1466421339, st_ctime=1466421339) os.stat_result(st_mode=33188, st_ino=7295271, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=12, st_size=690, st_atime=1466480420, st_mtime=1466421339, st_ctime=1466480937)
shutil.copy(src, dst) 拷贝文件和权限
shutil.copy(‘data.xml‘,‘data2.xml‘) print(os.stat(‘data.xml‘)) print(os.stat(‘data2.xml‘)) #结果:uid,gid, 权限都一样 os.stat_result(st_mode=33188, st_ino=7289084, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466481121, st_mtime=1466421339, st_ctime=1466421339) os.stat_result(st_mode=33188, st_ino=7295817, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466481121, st_mtime=1466481121, st_ctime=1466481121)
shutil.copy2(src, dst) 拷贝文件以及文件的状态信息
shutil.copy2(‘data.xml‘,‘data3.xml‘) print(os.stat(‘data.xml‘)) print(os.stat(‘data3.xml‘)) #执行结果,atime, mtime一样 os.stat_result(st_mode=33188, st_ino=7289084, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466481242, st_mtime=1466421339, st_ctime=1466421339) os.stat_result(st_mode=33188, st_ino=7295871, st_dev=16777220, st_nlink=1, st_uid=501, st_gid=20, st_size=690, st_atime=1466481242, st_mtime=1466421339, st_ctime=1466481242)
shutil.ignore_patters(*patterns) 忽略某匹配模式的文件拷贝,生成一个函数,可以作为调用copytree()的ignore参数。
需要结合shutil.copytree(src , dst,symlinks=False, ignore=None)
import shutil
import os
#先看dir1下面有什么文件:
result = os.listdir(‘dir1‘)
for i in result:
print(i)
__init__.py
company.xml
company_v2.xml
company_v3.xml
data.tar
data.xml
data.zip
data2.xml
data3.xml
data_new
data_new.xml
data_new2.xml
example.xml
example_new.xlm
example_new.xml
example_new2.xml
my.cnf
test_popen
test_popen_2
#那就copy的时候排除xml后缀的文件
shutil.copytree(‘dir1‘,‘dir2‘, ignore=shutil.ignore_patterns(‘*.xml‘))
#注意,目标文件dir2不能存在,否则会报错!
result = os.listdir(‘dir2‘)
for i in result:
print(i)
#结果:
__init__.py
data.tar
data.zip
data_new
example_new.xlm
my.cnf
test_popen
test_popen_2
#默认的symlinks为False,如果dir1中有一个软链文件的话test.py: >>> os.system(‘ls -l dir1‘) total 4 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.txt -rw-r--r-- 1 root root 0 Jun 21 12:09 1.xml drwxr-xr-x 3 root root 4096 Jun 21 13:27 2 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.txt -rw-r--r-- 1 root root 0 Jun 21 12:09 2.xml -rw-r--r-- 1 root root 0 Jun 21 12:09 3.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 3.txt -rw-r--r-- 1 root root 0 Jun 21 12:09 3.xml lrwxrwxrwx 1 root root 12 Jun 21 13:27 test.py -> /tmp/test.py #默认的拷贝文件夹树 >>> shutil.copytree(‘dir1‘,‘dir2‘,ignore=shutil.ignore_patterns(‘*.xml‘)) ‘dir2‘ #查看dir2 >>> os.system(‘ls -l dir2‘) total 4 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.txt drwxr-xr-x 3 root root 4096 Jun 21 13:27 2 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.txt -rw-r--r-- 1 root root 0 Jun 21 12:09 3.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 3.txt -rw-r--r-- 1 root root 0 Jun 16 10:59 test.py #把软链文件直接复制一份过来了 #使用symlinks参数 >>> shutil.copytree(‘dir1‘,‘dir3‘,symlinks=True,ignore=shutil.ignore_patterns(‘*.xml‘)) ‘dir3‘ >>> os.system(‘ls -l dir3‘) total 4 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 1.txt drwxr-xr-x 3 root root 4096 Jun 21 13:27 2 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 2.txt -rw-r--r-- 1 root root 0 Jun 21 12:09 3.mp3 -rw-r--r-- 1 root root 0 Jun 21 12:09 3.txt lrwxrwxrwx 1 root root 12 Jun 21 13:27 test.py -> /tmp/test.py #软链也带过来了
shutil.rmtree(path[, ignore_error[,noerror]]) 递归方式删除文件
>>> shutil.rmtree(‘dir3‘) >>> os.listdir(‘.‘) [‘dir2‘, ‘dir1‘] #dir3目录已经被删除了
shutil.move(src, dst) 递归方式移动(重命名)文件/文件夹, 和shell中的mv命令一样
>>> os.listdir(‘.‘) [‘dir2‘, ‘dir1‘] >>> shutil.move(‘dir2‘,‘/tmp/dir_2‘) ‘/tmp/dir_2‘ >>> os.listdir(‘.‘) [‘dir1‘] >>> os.listdir(‘/tmp‘) [‘dir_2‘, ‘test.py‘, ‘1_bak‘, ‘hsperfdata_root‘]
shutil.make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0,dry_run=0, owner=None, group=None, logger=None)
创建压缩包并返回文件的路径
base_name: 压缩包名,也可以指定文件存放的绝对路径,如果不指定路径名,压缩包存放在当前路径。
format: 压缩包种类,如 zip, tar, bztar, gztar
root_dir: 要压缩文件/文件夹的路径, 默认当前路径
owner: 属主, 默认当前用户
group: 属组, 默认当前用户组
logger: 记录日志,通常是logging.Logger对象
>>> shutil.make_archive(‘dir1‘,‘gztar‘,base_dir=‘dir1‘) ‘dir1.tar.gz‘ #查看压缩的 >>> os.listdir(‘.‘) [‘dir1.tar.gz‘, ‘dir1‘]
#指定绝对路径 >>> shutil.make_archive(‘/tmp/dir1‘,‘gztar‘,base_dir=‘dir1‘) ‘/tmp/dir1.tar.gz‘ >>> os.listdir(‘/tmp‘) [‘dir_2‘, ‘dir1.tar.gz‘, ‘test.py‘, ‘1_bak‘, ‘hsperfdata_root‘]
ZipFile模块是处理zip压缩包的模块,用于压缩和解压,添加和列出压缩包的内容。ZipFile是主要的类,其过程是讲每个文件以及相关的信息作为ZipInfo对象操作到ZipFile的成员,包括文件头信息和文件内容。ZipFile模块详细介绍,点我
tarfile模块可以用于压缩/解压tar类型文件,并且支持进一步压缩tar.gz和tar.bz2文件,主要是调用open函数打开文件,并返回TarFile实例。Tarfile模块详细介绍,点我
其实shutil对压缩包的处理就是调用ZipFile 和 TarFile两个模块来处理的。
import zipfile #压缩 zip_file = zipfile.ZipFile(‘test.zip‘,‘w‘) zip_file.write(‘s2_xml.py‘) zip_file.write(‘s3_xml2.py‘) zip_file.close() #执行完上面代码后,会发现在当前目录生辰搞一个test.zip文件 #解压缩: zf = zipfile.ZipFile(‘test.zip‘,‘r‘) zf.extractall() zf.close() #手动删除原有的s2_xml.py s3_xml2.py之后,执行上述代码,而后两个文件又恢复了。。。
如果要解压单个文件:
#想要解压缩某一个文件,首先要知道压缩包内包含什么文件。
zf = zipfile.ZipFile(‘test.zip‘,‘r‘)
#先使用namelist()方法来查看压缩包内的文件,返回一个列表的形式
result = zf.namelist()
for i in result:
print(i)
#for循环,查看执行结果:
s2_xml.py
s3_xml2.py
#解压s2_xml.py出来,先删除当前目录下的这个文件:
#而后使用extract()方法解压
zf.extract(‘s2_xml.py‘)
tarfile
import tarfile #打包 tar_file = tarfile.open(‘test.tar‘,‘w‘) tar_file.add(‘s3_xml2.py‘,arcname=‘s3_xml2.py‘) tar_file.add(‘s4_xml.py‘,arcname=‘wobugaosuni.py‘) tar_file.close() #arcname是在包里的文件名字,打包后的文件名字可以和源文件名字不同 #删除原有两个文件,而后解压 tar_file = tarfile.open(‘test.tar‘,‘r‘) tar_file.extractall() tar_file.close() #注意上面的s4_xml.py在压缩包内的名字是wobugaosuni.py, 解压后的文件,也是这个名字
#解压归档包里的某一个文件,还是首先要查看包里包含什么文件。使用getnames()方法,返回一个列表,而后使用extract()解压所需的单个文件 tar_file = tarfile.open(‘test.tar‘,‘r‘) tar_file.extract(‘s3_xml2.py‘) tar_file.close()
4. subprocess模块
subprecess模块允许你产生新的进程,然后连接他们的输入、输出、错误管道,并获取返回值。
启动一个子进程的方式是使用便捷函数。对于更高级的使用场景当便捷函数不能满足需求是,可以使用底层的Popen接口。
subprocess.call(args, * , stdin=None, stdout=None, stderr=None,shell=False) 执行args命令,等待命令完成,然后返回状态码。
import subprocess result = subprocess.call([‘ls‘,‘-l‘]) #默认shell为False,传入命令带参数的时候也是需要使用列表元素来传入。 print(result) #可将shell 置为True,使用和shell下一样的方式: result = subprocess.call(‘ls -l‘,shell=True)
print(result)
subprocess.check_call(args, *, stdin=None,stdout=None,stderr=None,shell=False)执行带参数的命令,等待命令完成,如果状态码是0则返回0,否则则抛出CalleProcessError的异常。
result = subprocess.check_call(‘ls -l‘,shell=True)
#正常执行后返回执行结果
print(result)
#执行一个不存在的命令,则抛出异常:
result1 = subprocess.check_call(‘sb‘,shell=True)
print(result1)
.....
raise CalledProcessError(retcode, cmd)
subprocess.CalledProcessError: Command ‘sb‘ returned non-zero exit status 127
subprocess.check_output(args, *, stdin=None,stdout=None,stderr=None,shell=False,universal_newlines=False)
执行带参数的命令并将它的输出作为字字节字符串返回。如果返回值非0,抛出异常CalledProcessError。
>>> subprocess.check_output([‘ls‘,‘-l‘])
b‘total 8\ndrwxr-xr-x 3 root root 4096 Jun 21 13:27 dir1\n-rw-r--r-- 1 root root 276 Jun 21 13:55 dir1.tar.gz\n‘
#返回非0,抛异常
>>> subprocess.check_output([‘ls‘,‘-l‘,‘/sb‘])
ls: cannot access /sb: No such file or directory
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/lib/python3.4/subprocess.py", line 620, in check_output
raise CalledProcessError(retcode, process.args, output=output)
subprocess.CalledProcessError: Command ‘[‘ls‘, ‘-l‘, ‘/sb‘]‘ returned non-zero exit status 2
subprocess.Popen() Popen构造函数接受大量可选参数。对于大部分典型的使用场景,这些参数中的许多个可以安全的保持为默认值。常用参数:
输入python3,进入解释器,然后输出一个hello world
import subprocess
#将标准输入、输出、错误使用PIPE管道
obj = subprocess.Popen(‘Python‘,stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE,universal_newlines=True)
#而后写入stdin
obj.stdin.write(‘print("hello world")\n‘)
obj.stdin.write(‘print("hello world agin")\n‘)
obj.stdin.close()
#读取标准输出,而后关闭
out = obj.stdout.read()
obj.stdout.close()
#读取标准错误,而后关闭
err = obj.stderr.read()
obj.stderr.close()
#打印
print(out)
print(err)
标签:
原文地址:http://www.cnblogs.com/wml1989/p/5613677.html