标签:
为了让Scala运行起来还是很麻烦,为了大家方便,还是记录下来:
2.1 进入设置菜单。
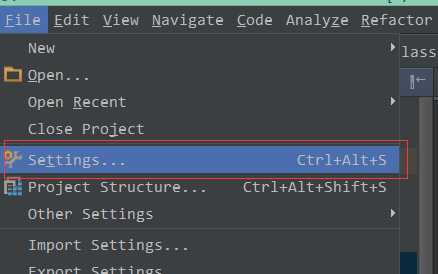
2.2 点击安装JetBrains plugin
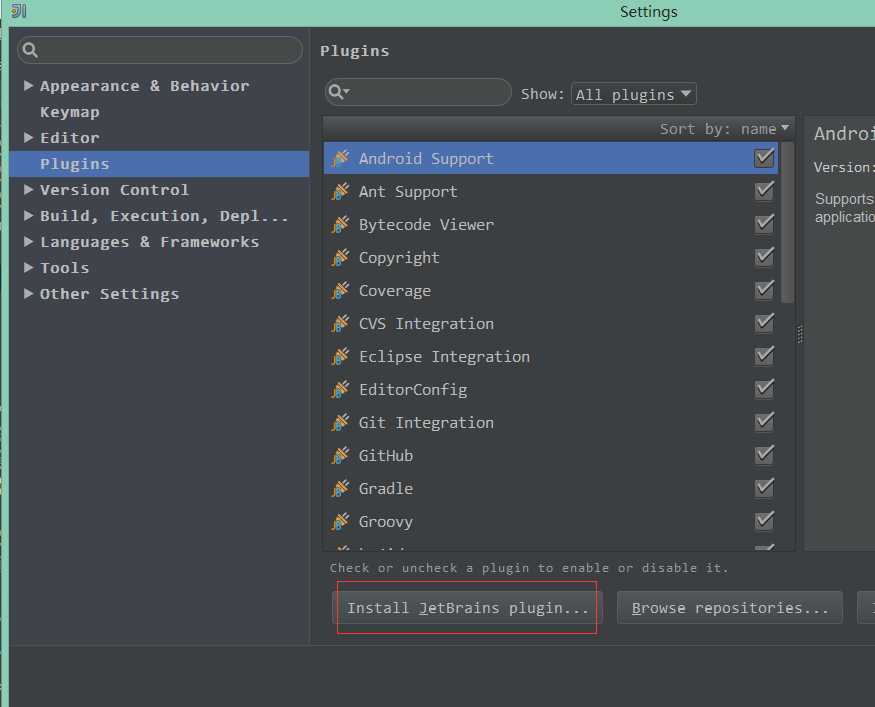
2.3 输入scala查询插件,点击安装
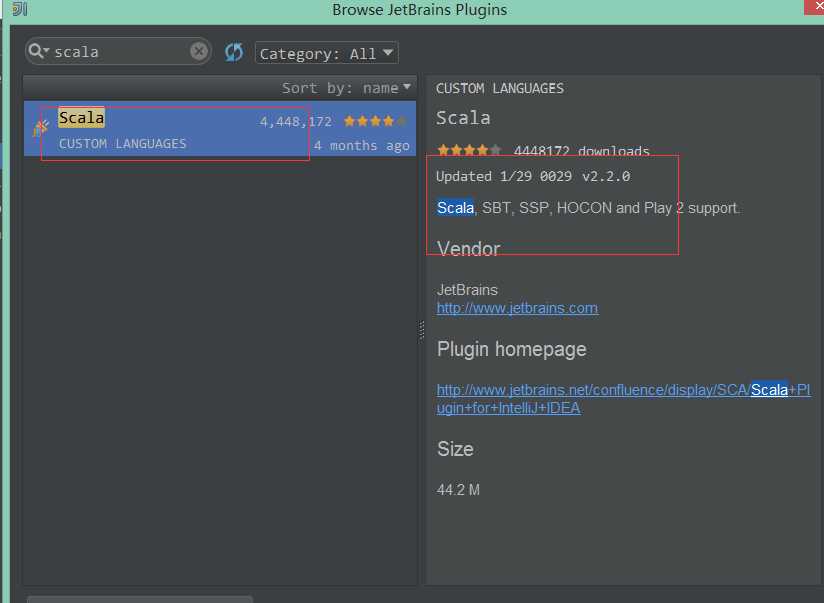
说明:我的IDEA已经安装,所以这里面没有显示出来安装按钮,否则右边有显示绿色按钮。
通过菜单:File----》New Project 选择Scala工程。
并且设置项目基本信息,如下图:

1)点击右上角的方块:
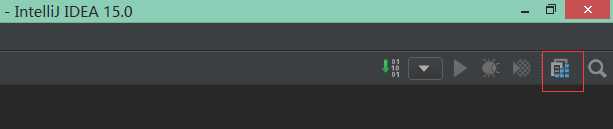
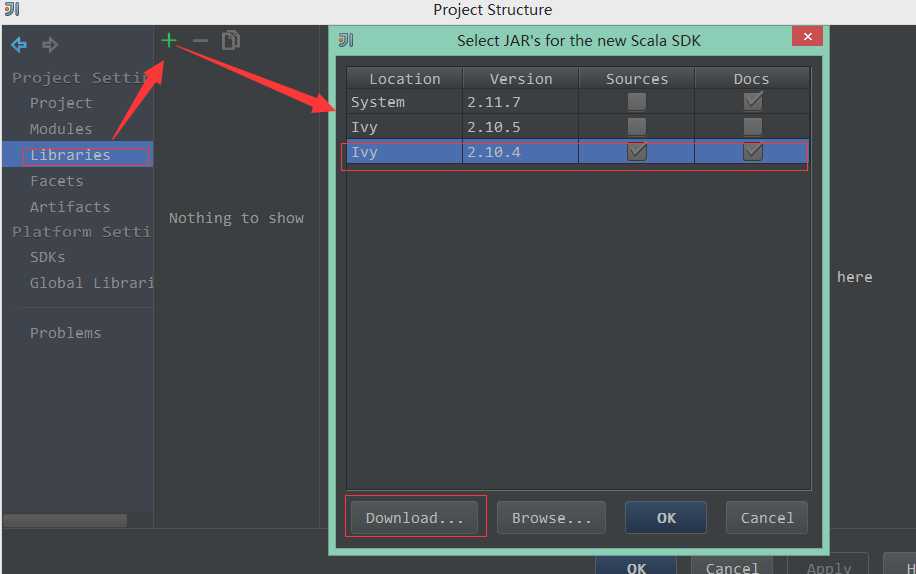
2)在左边选择Libraries---》+---》Scala SDK--》选择版本为2.10.4
说明:如果不存在这个版本可以通过左下角的download去下载。
3)选择添加Java的Jar文件,选择Spark和Hadoop关联的Jar
我这里添加的是:spark-assembly-1.6.1-hadoop2.6.0.jar 这个是spark安装时候自带的lib里面有,很大。
定位到jar所在的目录后,刷新,选择这个文件,点击OK,会花费比较长时间建索引。
4)在Src源码目录新建文件:WordCount.scala
且输入如下代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object WordCount {
def main(args: Array[String]) {
if (args.length < 1) {
System.err.println("Usage:<File>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val line = sc.textFile(args(0))
val words = line.flatMap(_.split("")).map((_, 1))
val reducewords = words.reduceByKey(_ + _).collect().foreach(println)
sc.stop()
}
}
标签:
原文地址:http://www.cnblogs.com/seaspring/p/5615976.html