标签:
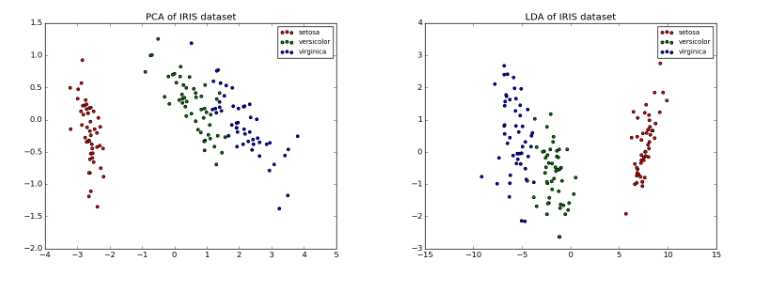
PCA 主成分分析方法,LDA 线性判别分析方法,可以认为是有监督的数据降维。下面的代码分别实现了两种降维方式:
print(__doc__) import matplotlib.pyplot as plt from sklearn import datasets from sklearn.decomposition import PCA from sklearn.discriminant_analysis import LinearDiscriminantAnalysis iris = datasets.load_iris() X = iris.data y = iris.target target_names = iris.target_names pca = PCA(n_components=2) X_r = pca.fit(X).transform(X) lda = LinearDiscriminantAnalysis(n_components=2) X_r2 = lda.fit(X, y).transform(X) # Percentage of variance explained for each components print(‘explained variance ratio (first two components): %s‘ % str(pca.explained_variance_ratio_)) plt.figure() for c, i, target_name in zip("rgb", [0, 1, 2], target_names): plt.scatter(X_r[y == i, 0], X_r[y == i, 1], c=c, label=target_name) plt.legend() plt.title(‘PCA of IRIS dataset‘) plt.figure() for c, i, target_name in zip("rgb", [0, 1, 2], target_names): plt.scatter(X_r2[y == i, 0], X_r2[y == i, 1], c=c, label=target_name) plt.legend() plt.title(‘LDA of IRIS dataset‘) plt.show()
结果如下
标签:
原文地址:http://www.cnblogs.com/zhusleep/p/5616294.html