标签:
RabbitMQ内建集群的设计用于完成两个目标:允许消费者和生产者在RabbitMQ节点在奔溃的情况下继续运行,以及通过添加更多的节点来线性扩展消息通信的吞吐量。当失去一个RabbitMQ节点时客户端能够连接集群中的任何其他节点并继续生产或者消费消息。同样,如果RabbitMQ集群正疲于应对庞大的消息通信量,可以通过添加更过的节点线性增加性能。
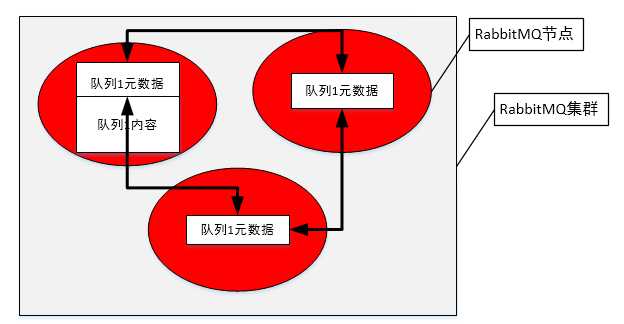
RabbitMQ集群不会保证消息的万无一失:因为RabbitMQ默认不会将队列的内容复制到整个集群上。如果不进行特殊的配置,这些消息仅存在队列所属的那个节点上。
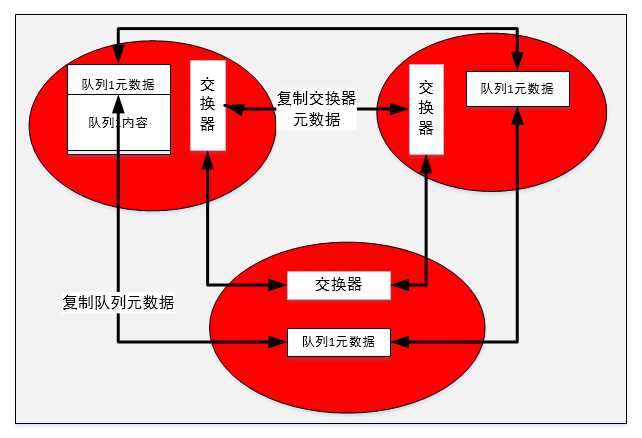
RabbitMQ会始终记录以下四种类型的内部元数据:
在单一节点中,RabbitMQ会将这些元数据信息存储在硬盘中,同时哪些标记为可持久化的队列和交换器(以及它们的绑定)存储在硬盘上。存储在硬盘和交换器和队列在重启RabbitMQ后重新重建。当引入集群时,RabbitMQ需要跟踪新的元数据类型:集群节点位置、以及节点与已记录的其他类型元数据的关系。
在RabbitMQ集群中,不是每一个节点都有所有队列的完全拷贝。如果在集群中创建队列的话,集群只会在单个节点而不是在所有节点上创建完整的队列信息(元数据、状态和内容)。结果是只有队列的所有者节点知道有关队列的所有信息。所有其他非所有者节点只知道队列的元数据和指向该队列存在的那个节点的指针。因此当集群节点奔溃是,该节点的队列和关联的绑定就都消失了。附加在队列的消费者也丢失了订阅信息,并且任何匹配该队列绑定信息的新消息也都丢失了。可以通过让消费者重新连接到集群并重新创建队列。但是这种做法仅对当队列最开始没有被设置成可持久化才行。
为什么在默认情况下RabbitMQ不将队列内容和状态复制到所有的节点呢?
交换器是一个名称和一个队列绑定的列表。当消息发布到交换器时,实际是由连接到的信道将消息上路由键同交换器的绑定进行比较,然后路由消息。
当创建一个新的交换器时,RabbitMQ所要做的是将查询表添加到集群中的所有节点上。
如果消息已经发布到信道上,但在消息路由之前节点发生故障的这些消息会怎样?
AMQP的basic.publish命令不会返回消息的状态。这种情况意味着消息将会丢失。解决方案是使用AMQP事务,在消息路由到队列之前一直它会一直阻塞;或者使用发送发确认模式来记录连接中断是尚未被确认的消息。
 内存节点和磁盘阶段
内存节点和磁盘阶段内存阶段:将所有队列、交换器、绑定、用户、权限和Vhost的元数据定义都出处在内存中。而磁盘节点则将元数据存储在磁盘中。单节点系统只允许磁盘类型的节点:否则每次重启RabbitMQ后,所有关于系统的配置信息都会丢失。
RabbitMQ只要求集群中至少有一个磁盘节点,其他节点都可以是内存节点。当节点加入或者离开集群时,它们必须要将变更通知到至少一个磁盘节点。如果只有一个磁盘节点,磁盘节点奔溃后,集群可以继续路由消息(即保持运行),但是直到该节点恢复之前,无法更改任何东西。通常在集群中设置两个磁盘节点。
标签:
原文地址:http://www.cnblogs.com/wxgblogs/p/5618151.html