标签:
编程实现判别分析,并给出西瓜数据集上的结果。
数据集如下
编号,色泽,根蒂,敲声,纹理,脐部,触感,密度,含糖率,好瓜 1,青绿,蜷缩,浊响,清晰,凹陷,硬滑,0.697,0.46,是 2,乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,0.774,0.376,是 3,乌黑,蜷缩,浊响,清晰,凹陷,硬滑,0.634,0.264,是 4,青绿,蜷缩,沉闷,清晰,凹陷,硬滑,0.608,0.318,是 5,浅白,蜷缩,浊响,清晰,凹陷,硬滑,0.556,0.215,是 6,青绿,稍蜷,浊响,清晰,稍凹,软粘,0.403,0.237,是 7,乌黑,稍蜷,浊响,稍糊,稍凹,软粘,0.481,0.149,是 8,乌黑,稍蜷,浊响,清晰,稍凹,硬滑,0.437,0.211,是 9,乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,0.666,0.091,否 10,青绿,硬挺,清脆,清晰,平坦,软粘,0.243,0.267,否 11,浅白,硬挺,清脆,模糊,平坦,硬滑,0.245,0.057,否 12,浅白,蜷缩,浊响,模糊,平坦,软粘,0.343,0.099,否 13,青绿,稍蜷,浊响,稍糊,凹陷,硬滑,0.639,0.161,否 14,浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,0.657,0.198,否 15,乌黑,稍蜷,浊响,清晰,稍凹,软粘,0.36,0.37,否 16,浅白,蜷缩,浊响,模糊,平坦,硬滑,0.593,0.042,否 17,青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,0.719,0.103,否
Python代码实现方式如下:调用了sklearn中的线性判别分析模块。
#!/usr/bin/python # -*- coding:utf-8 -*- import numpy as np import matplotlib.pyplot as plt from matplotlib import colors from sklearn.discriminant_analysis import LinearDiscriminantAnalysis file1 = open(‘c:\quant\watermelon.csv‘,‘r‘) data = [line.strip(‘\n‘).split(‘,‘) for line in file1] X = [[float(raw[-3]), float(raw[-2])] for raw in data[1:]] y = [1 if raw[-1]==‘\xca\xc7‘ else 0 for raw in data[1:]] X = np.array(X) y = np.array(y) #######################################################################以上是西瓜 # colormap cmap = colors.LinearSegmentedColormap( ‘red_blue_classes‘, {‘red‘: [(0, 1, 1), (1, 0.7, 0.7)], ‘green‘: [(0, 0.7, 0.7), (1, 0.7, 0.7)], ‘blue‘: [(0, 0.7, 0.7), (1, 1, 1)]}) plt.cm.register_cmap(cmap=cmap) ############################################################################### # plot functions def plot_data(lda, X, y, y_pred): plt.figure() plt.title(‘Linear Discriminant Analysis‘) plt.xlabel(‘Sugar Rate‘) plt.ylabel(‘Density‘) tp = (y == y_pred) # True Positive //Boolean matrix tp0, tp1 = tp[y == 0], tp[y == 1] print tp X0, X1 = X[y == 0], X[y == 1] X0_tp, X0_fp = X0[tp0], X0[~tp0] X1_tp, X1_fp = X1[tp1], X1[~tp1] # class 0: dots plt.plot(X0_tp[:, 0], X0_tp[:, 1], ‘o‘, color=‘red‘) plt.plot(X0_fp[:, 0], X0_fp[:, 1], ‘.‘, color=‘#990000‘) # dark red # class 1: dots plt.plot(X1_tp[:, 0], X1_tp[:, 1], ‘o‘, color=‘blue‘) plt.plot(X1_fp[:, 0], X1_fp[:, 1], ‘.‘, color=‘#000099‘) # dark blue # class 0 and 1 : areas nx, ny = 200, 100 x_min, x_max = plt.xlim() y_min, y_max = plt.ylim() xx, yy = np.meshgrid(np.linspace(x_min, x_max, nx), np.linspace(y_min, y_max, ny)) Z = lda.predict_proba(np.c_[xx.ravel(), yy.ravel()]) Z = Z[:, 1].reshape(xx.shape) plt.pcolormesh(xx, yy, Z, cmap=‘red_blue_classes‘, norm=colors.Normalize(0., 1.)) plt.contour(xx, yy, Z, [0.5], linewidths=2., colors=‘k‘) # means plt.plot(lda.means_[0][0], lda.means_[0][1], ‘o‘, color=‘black‘, markersize=10) plt.plot(lda.means_[1][0], lda.means_[1][1], ‘o‘, color=‘black‘, markersize=10) ############################################################################### # Linear Discriminant Analysis lda = LinearDiscriminantAnalysis(solver="svd", store_covariance=True) y_pred = lda.fit(X, y).predict(X) plot_data(lda, X, y, y_pred) plt.axis(‘tight‘) plt.suptitle(‘Linear Discriminant Analysis of Watermelon‘) plt.show()
结果如下:
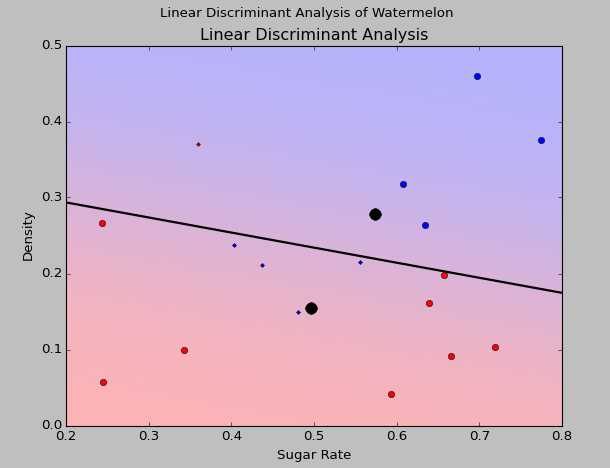
其中红色的蓝色的分别是两种西瓜。小红色的点和小蓝色的点表示区分错误。中间的横线是分界线。
标签:
原文地址:http://www.cnblogs.com/zhusleep/p/5621932.html