标签:
Hadoop的文件系统,对于节点管理,最终还是为了进行运算。所以其中最主要的运算核心还是MapReduce。有些书上会吧Map和Reduce翻译过来讲,我觉得很生硬,不如直接用英文来的好。不翻译过来的前提要明白Map和Reduce的内在含义。Map原意是地图,计算机上多为映射,怎么个映射法?其实就是某个键值对映射到固定的reduce。那reduce又是什么,开始我也不明白,为什么不用compute了?后来算是明白了,其实reduce是对数据集进行精简,然后得出相应结果。所以叫reduce减少的意思,有翻译为归并。
当我们手中有大量数据的时候,如何对数据进行处理,比如去重,排序等甚至更加复杂的处理呢?我们又要如何来用多台机器对数据进行处理?
要是我,我肯定会将大量的数据进行分类,同一类的数据集给同一台机器来处理。怎么分?怎么处理呢?这就需要看到底要对数据做那些处理了。
而这种先分类后处理的想法就是MapReduce的过程。其中分类的具体过程在mapreduce结构中称为shuffle,下面讲解mapreduce的过程中会包涵在其中,但不会单独提出来讲。
如果不对数据分类,意味着不能用多台机器对数据进行处理,因为会出现机器处理的数据之间存在某些重要的联系,这些联系决定了这类数据一定要在同一台机器上运行。所以,运算前对数据进行分类是必要的准备。也就是Map的过程,将有联系的数据分到一起,然后交给相应的reduce做处理。Reduce是对数据进行最终目的性的处理。
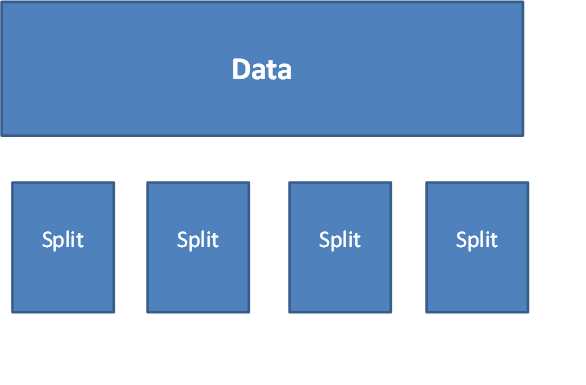
首先对大量的数据进行简单的分割,如下图所示,每一个split的大小可能是64M也可能是128M其大小是由硬盘传输速度决定的。
 、
、
图1.HDFS对大量数据进行分块
对于每个split交给一个map来处理。过程如下。Map的输入是split里面的一行,key为偏移量,value就是该行的内容。处理的结果放入一个容器中,容器填满了就溢出到硬盘,溢出的过程会对数据进行partition和sort。Sort很容易理解,关键是partition,partition也就是前面说的分类,这一部最终决定该键值对未来会交给哪个reduce。但所有map运行完了,就会有一堆spill。当然在map的过程中reduce的准备阶段以及开始,reduce的准备阶段就是把本reduce对应的partition移动到本地来。但要进行reduce操作一定要等所有map结束,属于本reduce的partition全部移到本地,然后真正进入reduce阶段。
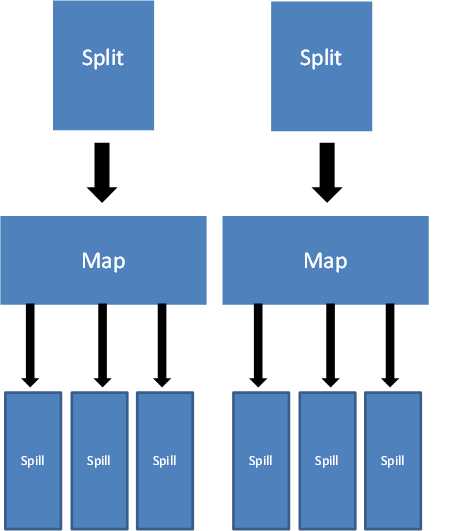
图2.Map过程
首先数据准备,也就是上面说的,将属于本reduce的partition移动到本地来。然后进行排序最后成为reduce 的运算数据。Reduce才是真正对数据进行相应的处理产生最终结果。在map和reduce有一个环节—shuffle。我已经融合在了上面说介绍的步骤里面了。Shuffle指的就是数据通过map进行初步处理后,将同一类的数据分发给同一个reduce。
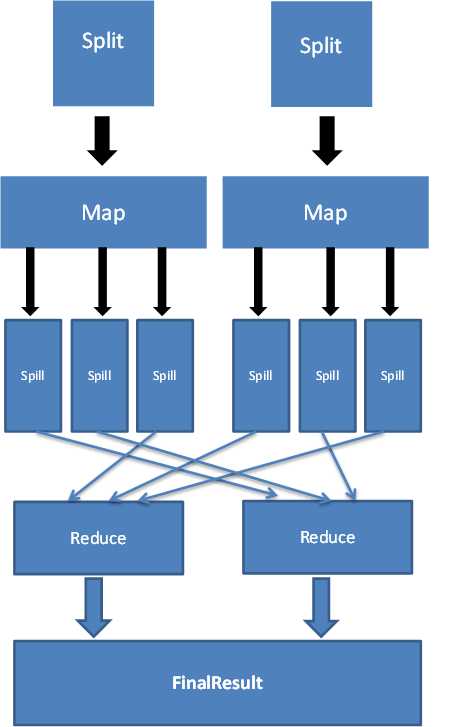
图3.map+reduce过程
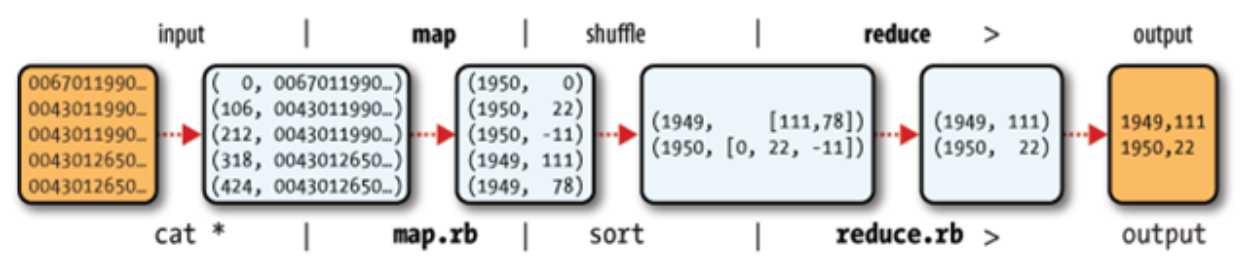
假设我们需要处理一批有关天气的数据,其格式如下: 按照ASCII码存储,每行一条记录,每一行字符从0开始计数,第15个到第18个字符为年,第25个到第29个字符为温度,其中第25位是符号+/-,现在需要统计出每年的最高温度。
0067011990999991950051507+0000+
0043011990999991950051512+0022+
0043011990999991950051518-0011+
0043012650999991949032412+0111+
0043012650999991949032418+0078+
0067011990999991937051507+0001+
0043011990999991937051512-0002+
0043011990999991945051518+0001+
0043012650999991945032412+0002+
0043012650999991945032418+0078+
MapReduce主要包括两个步骤:Map和Reduce 每一步都有key/value对作为输入和输出:
Map阶段的key/value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本,Map阶段的输出的key/value对的格式必须同Reduce阶段的输入key/value对的格式相对应
对于上面的例子,在map过程,输入的key-value对如下:
(0 ,0067011990999991950051507+0000+)
(1 ,0043011990999991950051512+0022+)
(2 ,0043011990999991950051518-0011+)
(3 ,0043012650999991949032412+0111+)
(4 ,0043012650999991949032418+0078+)
(5 ,0067011990999991937051507+0001+)
(6 ,0043011990999991937051512-0002+)
(7 ,0043011990999991945051518+0001+)
(8 ,0043012650999991945032412+0002+)
(9 ,0043012650999991945032418+0078+)
将上面的数据作为用户编写的map函数的输入,通过对每一行字符串的解析,得到年/温度的key/value对作为输出:
(1950, 0)
(1950, 22)
(1950, -11)
(1949, 111)
(1949, 78)
(1937, 1)
(1937, -2)
(1945, 1)
(1945, 2)
(1945, 78)
在Reduce过程,将map过程中的输出,按照相同的key将value放到同一个列表中作为用户写的reduce函数的输入
(1950, [0, 22, –11])
(1949, [111, 78])
(1937, [1, -2])
(1945, [1, 2, 78])
在Reduce过程中,在列表中选择出最大的温度,将年/最大温度的key/value作为输出:
(1950, 22)
(1949, 111)
(1937, 1)
(1945, 78)
其逻辑过程可用如下图表示:
标签:
原文地址:http://www.cnblogs.com/gy19920604/p/5627699.html