标签:
#-*- coding: UTF-8 -*- import numpy as np from sklearn.pipeline import Pipeline from sklearn.linear_model import SGDClassifier from sklearn.grid_search import GridSearchCV from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.datasets import fetch_20newsgroups from sklearn import metrics 获取待分类的文本数据源 categories = [‘comp.graphics‘, ‘comp.os.ms-windows.misc‘,‘comp.sys.ibm.pc.hardware‘,‘comp.sys.mac.hardware‘,‘comp.windows.x‘]; newsgroup_data = fetch_20newsgroups(subset = ‘train‘,categories = categories) X,Y=np.array(newsgroup_data.data),np.array(newsgroup_data.target) Xtrain,Ytrain,Xtest,Ytest =X[0:2400],Y[0:2400],X[2400:],Y[2400:] #Pipeline主要用于将三个需要串行的模块串在一起,后一个模型处理前一个的结果‘‘‘ #vect主要用于去音调、转小写、去停顿词->tdidf主要用于计词频->clf分类模型‘‘‘ pipeline_obj = Pipeline([(‘vect‘,CountVectorizer()),(‘tfidf‘,TfidfTransformer()),(‘clf‘,SGDClassifier()),]) print "pipeline:",‘\n‘, [name for name, _ in pipeline_obj.steps],‘\n‘ #定义需要遍历的所有候选参数的字典,key_name需要用__分隔模型名和模型内部的参数名‘‘‘ parameters = { ‘vect__max_df‘: (0.5, 0.75),‘vect__max_features‘: (None, 5000, 10000), ‘tfidf__use_idf‘: (True, False),‘tfidf__norm‘: (‘l1‘, ‘l2‘), ‘clf__alpha‘: (0.00001, 0.000001), ‘clf__n_iter‘: (10, 50) } print "parameters:",‘\n‘,parameters,‘\n‘ #GridSearchCV用于寻找vectorizer词频统计, tfidftransformer特征变换和SGD classifier分类模型的最优参数 grid_search = GridSearchCV( pipeline_obj, parameters, n_jobs = 1,verbose=1 ) print ‘grid_search‘,‘\n‘,grid_search,‘\n‘ #输出所有参数名及参数候选值 grid_search.fit(Xtrain,Ytrain),‘\n‘#遍历执行候选参数,寻找最优参数 best_parameters = dict(grid_search.best_estimator_.get_params())#get实例中的最优参数 for param_name in sorted(parameters.keys()): print("\t%s: %r" % (param_name, best_parameters[param_name])),‘\n‘#输出最有参数结果 pipeline_obj.set_params(clf__alpha = 1e-05,clf__n_iter = 50,tfidf__use_idf = True,vect__max_df = 0.5,vect__max_features = None) #将pipeline_obj实例中的参数重写为最优结果‘‘‘ print pipeline_obj.named_steps #用最优参数训练模型‘‘‘ pipeline_obj.fit(Xtrain,Ytrain) pred = pipeline_obj.predict(Xtrain) print ‘\n‘,metrics.classification_report(Ytrain,pred) pred = pipeline_obj.predict(Xtest) print ‘\n‘,metrics.classification_report(Ytest,pred)
执行结果:总共有96个参数排列组合候选组,每组跑3次模型进行交叉验证,共计跑模型96*3=288次。
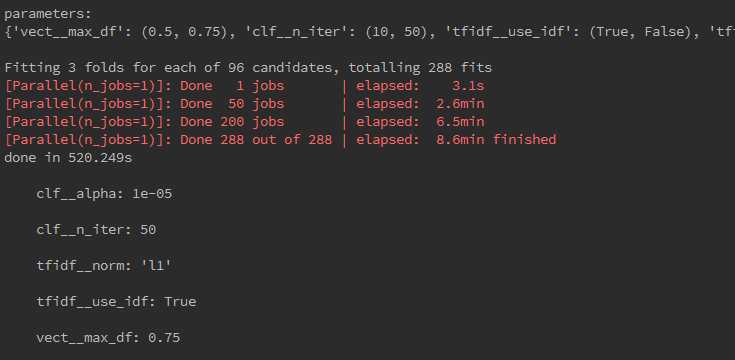
调参前VS调参后:
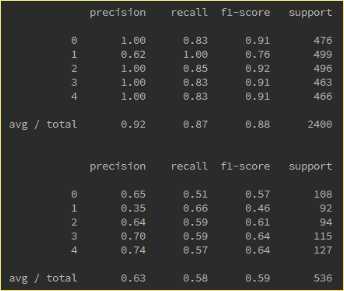
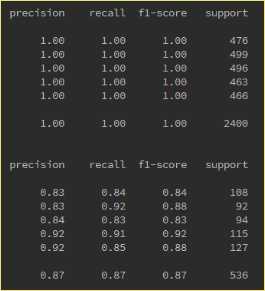
#参考
#http://blog.csdn.net/mmc2015/article/details/46991465
# http://blog.csdn.net/abcjennifer/article/details/23884761
# http://scikit-learn.org/stable/modules/pipeline.html
# http://blog.csdn.net/yuanyu5237/article/details/44278759
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类
标签:
原文地址:http://www.cnblogs.com/sunruina2/p/5630710.html