本文系微博运维数据平台(DIP)在实时计算平台的研发过程中集群资源管理方面的一些经验总结和运用,主要关注以下几个问题:
- 异构资源如何整合?
- 实时计算应用之间的物理资源如何隔离?
- 集群资源利用率如何提高?
- 集群运维成本如何降低?
1. 背景
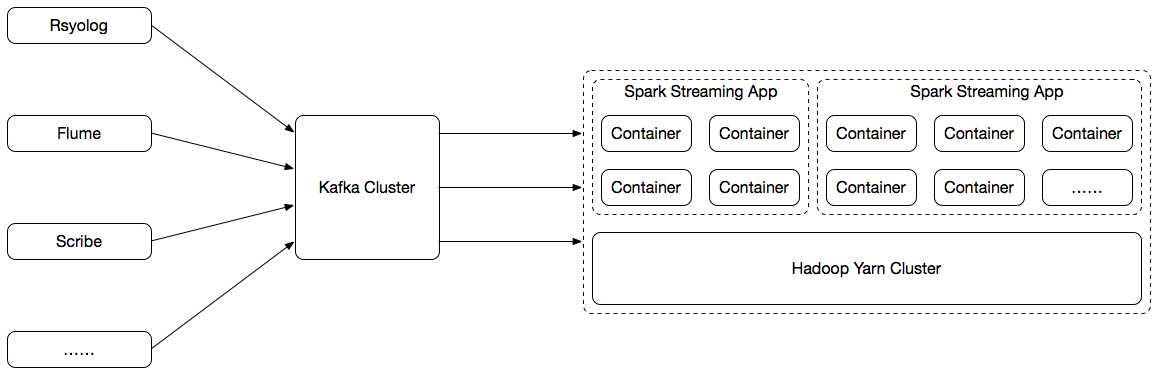
这是我们初期的一个实时计算架构,大致划分为三个部分:
(1)日志收集;
使用Rsynlog、Flume、Scribe汇聚各个业务方发送过来的日志数据;如果条件允许,业务方也可以直接将数据写入Kafka。
(2)日志传输;
使用Kafka作为日志收集组件与实时应用之间的一个高速传输通道,实际也是一个日志缓冲区。
(3)实时计算平台;
实时计算平台根据使用场景的不同包含有以下两种类型的应用:
(1)自助实时应用:依托于Spark Streaming、Spark SQL构建的通用实时处理模块,旨在简化用户开发、部署、运维实时应用的相关工作,大多数时候用户通过我们提供的Web页面即可完成实时应用的创建;
(2)第三方应用托管:应用计算处理逻辑与自身业务结合比较紧密,无法很好地抽象出可复用的模块,通常由业务方使用Spark Streaming自行开发完成,然后通过DIP平台统一部署;
这两种类型的实时应用均以Spark Streaming的形式运行于使用Hadoop Yarn FairScheduler作为资源管理器的集群之上。
本文仅介绍实时计算平台中的集群资源管理方案,关于日志收集、日志传输的内容可分别参考以下两篇文章:
2. Hadoop Yarn集群资源管理
在我们Hadoop Yarn集群中,集群资源管理器使用的是公平调度器(FairScheduler),以业务方为单位进行资源划分,为每个业务方分配一个单独的队列,这个队列关联着一定的资源(CPU、MEM)。为了保障各个业务方的资源使用,我们将各个队列的资源下限值(minResources)和资源上限值(maxResources)设置为相同,并禁用队列(业务)之间的资源抢占。上文中提及的自助实时应用和第三方应用提交时,均需要提交至业务方各自的队列中去运行。
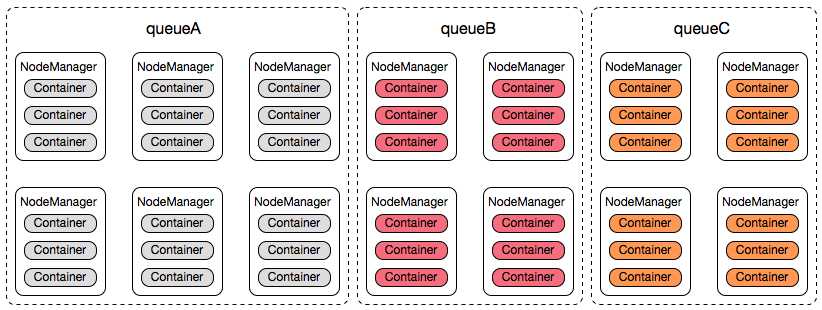
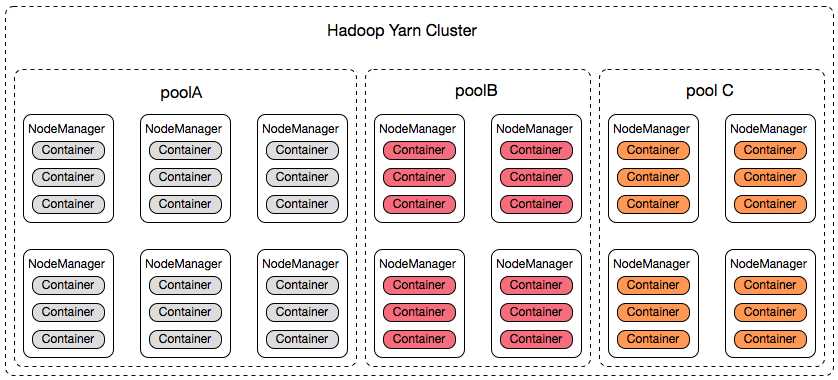
既然已经为各个业务方分配队列,且指定资源量,每个业务方就相当于在我们的Hadoop Yarn集群中拥有一定数量的服务器,集群运行时看起来是这个样子的:
简单起见,我们以队列名称代替业务方名称,每一个Container的资源为1 core、1g mem,由此可以得出如下信息:
(1)Hadoop Yarn 集群的总资源量:42cores,42g mem;
(2)三个业务方,即:queueA、queueB、queueC;
(3)queueA占有6台服务器资源:18 cores,18g mem,queueB、queueC各占有4台服务器资源:12 cores,12g mem;
这里我们需要注意,Hadoop Yarn FairScheduler只能控制各个队列的资源使用量,这是一种逻辑资源上的控制,并不能实际控制这些资源(Container)被分配在哪些服务器上运行。以queueA为例,queueA从资源使用分配的角度来说,它享有6台服务器的资源,但并不是说它会独占集群中的某6台服务器。
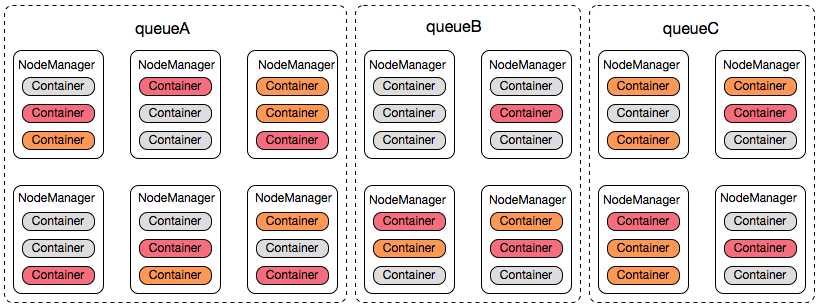
集群运行时实际是这个样子的:
queueA、queueB、queueC在各自资源使用量的范围内“逻辑共享”集群资源。这些资源的表现形式可以理解为就是Container(每个Container运行时需要分配一定的资源量,如1 core,1g mem),各个业务方的所有Container是混合运行在集群内的各个服务器上的。
Hadoop Yarn FairScheduelr的资源管理方式在我们的离线计算场景里运行良好,但在实时计算场景里却遇到了很多问题。
(1)异构资源如何整合?
异构资源包括两个方面:服务器机型不一致、服务器角色不一致。
a. 服务器机型不一致
很多业务方在接入实时应用时无法提供与我们现有集群同等配置的服务器,大多数性能偏低。这些业务方通常是出于开发、计算、运维效率方面的考虑,从过去的计算引擎(如:nodejs-statsd)迁移至Spark Streaming,机型的选取是根据当时的情况来衡量的。
Hadoop已经为我们考虑到机型不一致的情况,它的解决方式是每一台服务器(计算节点,Hadoop NodeManager)的资源使用量可以通过配置文件(yarn-site.xml,yarn.nodemanager.resource.cpu-vcores、yarn.nodemanager.resource.memory-mb)进行设置。我们可以根据业务方服务器的实际情况合理地设置这台服务器可使用的资源量,再根据业务方服务器的资源量总和为其划分相应的队列资源。
这个业务方的问题解决了,但是其它业务方会有这样的疑问:“我们的实时业务很重要,申请的全部是高性能的服务器,如果我们的应用被调度到这些性能比较差的服务器中运行,计算性能会不会有损耗?”。
业务方的这种担忧确实值得我们考虑,Spark Streaming Application是7 * 24小时不间断运行的,如果这个应用的Containers被调度至性能迥异的Hadoop NodeManager服务器中去执行,确实无法保证性能较差的服务器上的Container不会拖慢整个实时应用的执行进度。
b. 服务器角色不一致
新业务方的接入不仅仅需要扩容集群的计算节点(Hadoop NodeManager),同时也需要扩容Kafka Brokers节点。多数情况下业务方无法提供这样的冗余机器,这时我们设想使用“混合部署”的技术方案,即计算节点与Kafka Brokers节点部署在同一台服务器中,但是这会使得(1)中的“计算性能会不会有损耗”的问题愈演愈烈。
注:实时计算场景下,以Spark Streaming Application为例,Hadoop NodeManager Container属于CPU密集型应用,Kafka Brokers属于IO密集型应用,如果是独立业务,两者混合部署的效果还是不错的,DIP平台在这方面已经有很好地实践。
(2)实时计算应用之间的物理资源如何隔离?
物理资源包括四个方面:CPU、MEM、DISK、NETWORK。如果一台Hadoop NodeManager服务器中运行着不同业务方的Spark Streaming Application Containers,那么这些Containers之间就有可能存在互相影响的情况。
目前Hadoop Yarn仅仅支持CPU、MEM的资源管理,同时提供基于线程监控的内存使用机制和基于Cgroup的资源隔离机制,但对于DISK、NETWORK则缺乏相应的资源隔离机制,可能会引发Container之间的资源竞争导致Container执行效率低下,进而影响整个Spark Streaming Application的情况。
(3)集群资源利用率如何提高?
业务方提交Spark Streaming Application时可以通过以下三个参数指定实时应用运行期间的资源配额,
num-executors:Spark Streaming Application运行时需要申请多少个Containers;
executor-cores:Spark Streaming Application的每一个Container需要申请多少 cores;
executor-memory:Spark Streaming Application的每一个Container需要申请多少mem;
这三个参数值的选取需要考虑两个因素:
业务方队列资源冗余情况:DIP平台为业务方划分的队列中是否有足够的冗余资源用于新的Spark Streaming Application接入;
Spark Streaming Application资源需求情况:如果为该Application分配较多的资源,会导致资源浪费;如果分配较少的资源,会导致计算资源不足,进而影响业务;
作为集群资源的管理者,我们还需要考虑更多的问题:
a. 集群CPU、MEM资源分配不均衡;
集群CPU资源被耗尽,MEM资源有冗余;或者集群MEM资源被耗尽,CPU资源有冗余;
b. 集群资源碎片化的问题;
Hadoop NodeManager CPU/MEM资源均有冗余,却无法分配给Spark Streaming Application使用,这是因为该Hadoop NodeManager CPU/MEM的资源剩余量不足以满足任何一个业务方的Spark Streaming Application Container的资源需求量。如果出现这种现象的Hadoop NodeManager数目较多,会导致集群大量资源处于无法使用(浪费)的状态,而Spark Streaming Application也会出现无法申请Container或申请不到足够数量的Container的情况。
这两种问题引发的现象:业务方队列中的资源还有冗余,但是提交的应用却迟迟分配不到资源。
(4)集群运维成本如何降低?
集群的运维成本主要来自于第三方实时应用托管,不同的应用对系统环境有不同的依赖,如:Spark Streaming使用Python进行开发,它运行时需要很多依赖的库,这些库需要在整个集群的所有Hadoop NodeManager机器上面进行安装,各种版本冲突问题给我们带来了很大的运维压力,同时也是对我们集群环境的一种“污染”。
3. 弹性集群资源管理
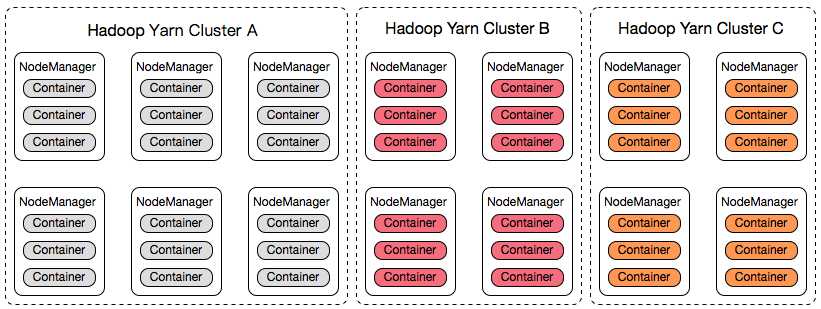
异构资源、物理隔离、资源利用率、运维成本引发了我们对Hadoop Yarn集群资源管理的思考,直接想到的方案是为各个业务方构建自己的集群,如下图所示:
根据我们以往的经验,这种方式运维监控的成本极高,我们很快就否定了这种方案。
既然无法构建多个集群,那么是否可以在一个集群内部划分多个“资源池”?每个资源池关联着若干台机器,为每一个业务方分配一个或多个资源池,业务方提交的应用仅在分配的资源池内运行,即仅在资源池关联的那些服务器中运行。
我们以“资源池”的方式来讨论一下是否可以解决上述提到的四个问题。
(1)异构资源;
我们将机型相同或相近的服务器组成一个或多个资源池,资源池的大小根据具体的业务需求而定。经过这样的处理之后,我们可以认为任何一个资源池内的服务器的计算性能都是等同的。业务方提交的应用只会在某一个资源池内运行,这个资源池内的多个计算节点性能相同,服务器机型不一致可能带来的性能损耗问题得到解决。
如果业务方需要“混合部署”,可以建立一个专用的资源池,将这些需要混合部署多个服务(这里特指Kafka Broker、Hadoop NodeManager)的服务器关联至该资源池。通常情况下,这种“混合部署”模式的资源池是特定应用专用的,这个资源池内的服务器角色是一致的,服务器角色不一致可能带来的性能损耗问题得到解决。
(2)物理资源隔离;
每个业务方仅能使用自己资源池内的物理资源,各个业务方之间的物理资源竞争问题得到解决。
对于特定的业务方而言,自己的资源池内可能会运行着多个实时应用,这些实时应用之间依然可能存在着物理资源竞争的问题,这方面我们是这么认为的:
a. 因为资源池是业务方独享的,业务方在开发部署应用时应充分考虑应用之间的物理资源竞争问题,也就是说,将同一个业务方多个应用之间的物理资源资源问题交由业务方自己负责;
b. 如果有特殊情况,我们可以为同一个业务方划分多个资源池,甚至一个应用一个资源池;
这样物理资源隔离问题得到解决。
(3)资源利用率;
“一个集群、多个队列”的模式下,业务方是不需要考虑资源利用率的问题的,只需要根据队列分配的资源大小和应用需要的资源来部署应用就可以了。从业务方的角度看,只要资源的使用处于队列分配资源的区间范围内就是没有问题的,这种角度实际上是比较“自私”的,没有考虑自己的行为对其它业务方的影响,资源分配不平衡、资源碎片化的问题本质即来源于此。
“一个集群、多个资源池”的模式下,一个资源池之内的资源是完全被独享的,业务方必须在自己资源池的范围内主动充分考虑资源分配不平衡、资源碎片化的问题。每个业务方的这种主动参与会带来集群整体资源利用率的大幅提高。
假设我们有一台24 cores、128g mem的服务器,如果选用它作为Hadoop NodeManager,一般情况下我们会这么设置:22 cores、120g mem,以使得这台服务器的物理资源能够得到充分的利用,这也是业界比较常见的做法。集群运维过程中,我们发现这样的现象(以CPU为例):“22 cores已经全部被分配,但是这台服务器的CPU利用率却只有60%,而且不是个别现象”,这是对集群资源的巨大浪费。“一个集群、多个队列”的模式下,我们的集群配置需要充分考虑到各个业务方的需求,只能使用上述的通用做法;“一个集群、多个资源池”的模式下,我们则可以根据应用的实际情况为某资源池内的Hadoop NodeManager作出“物别”地设置,如“44 cores、120g mem”,资源池可提供的资源“变多”,集群的整体利用率也会有所提升。
(4)运维成本;
运维成本主要来自于业务方的特殊需求,这种特殊需求的实施需要涉及到整个集群,包括后续加入的节点,人力成本和维护成本都很高。针对这种情况,我们对Hadoop NodeManager实现“容器化”(Docker)部署,如果业务方有特殊需求,则可以在我们提供的Docker基础镜像的基础之上作出相应的变更,不会直接“污染”系统环境,容易回退,且变更后的镜像只会部署在业务方特定资源池内的服务器上,不会影响到其它业务方,这种方式使得运维成本大幅下降。
综上所述,“一个集群、多个资源池”的模式能够解决异构资源、物理资源隔离、资源利用率、运维成本的问题。
4. 实现
Hadoop Yarn FairScheduler只支持应用之间的公平调度,我们需要对其进行相应的扩展,使之支持“资源池”的模式:
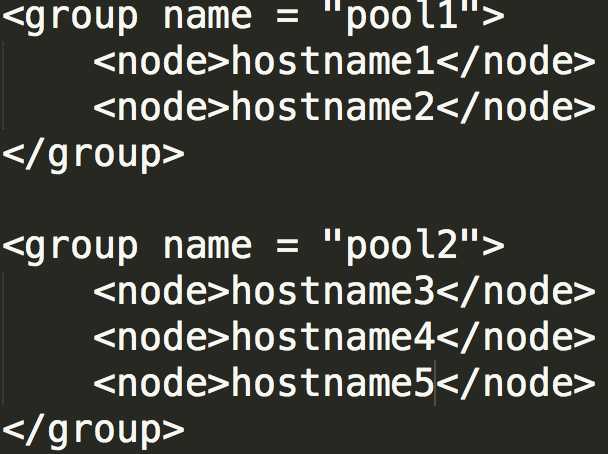
(1)资源池可配置,通过资源池名称可关联若干Hadoop NodeManager节点(使用主机名称(Hostname)表示),资源池配置在公平调度器的配置文件fair-scheduler.xml中即可,如下图所示:
多个资源池之间的Hadoop NodeManager节点不能有重合,即每一个Hadoop NodeManager节点仅能属于一个资源池;
(2)资源池与队列之间的对应关系依赖“名称前缀”来识别;以“pool1”、“pool2”为例,如果队列名称以“pool1”为前缀,那么该队列中的所有应用将运行于资源池pool1中;如果队列名称以“pool2”为前缀,该队列中的所有应用将运行于资源池pool2中;
核心思想
Hadoop Yarn FairScheduler每次收到Hadoop NodeManager的“NODE_UPDATE”事件时,就会使用公平调度算法为每个处于运行状态的应用分配Containers。我们需要在公平调度的基础之上添加资源池的处理逻辑,如为某个应用分配Containers时:
(1)获取“NODE_UPDATE”事件的Hadoop NodeManager的主机名称;
(2)获取应用的提交队列名称,并根据队列名称获取对应的资源池;如果可以找到对应的资源池,则继续(3);如果未找到对应的资源池,则结束分配过程,继续处理下一个应用;
(3)如果该资源池的节点列表中包含(1)中的主机名称,则继续使用公平调度算法完成分配;否则,结束分配过程,继续处理下一个应用;
实现
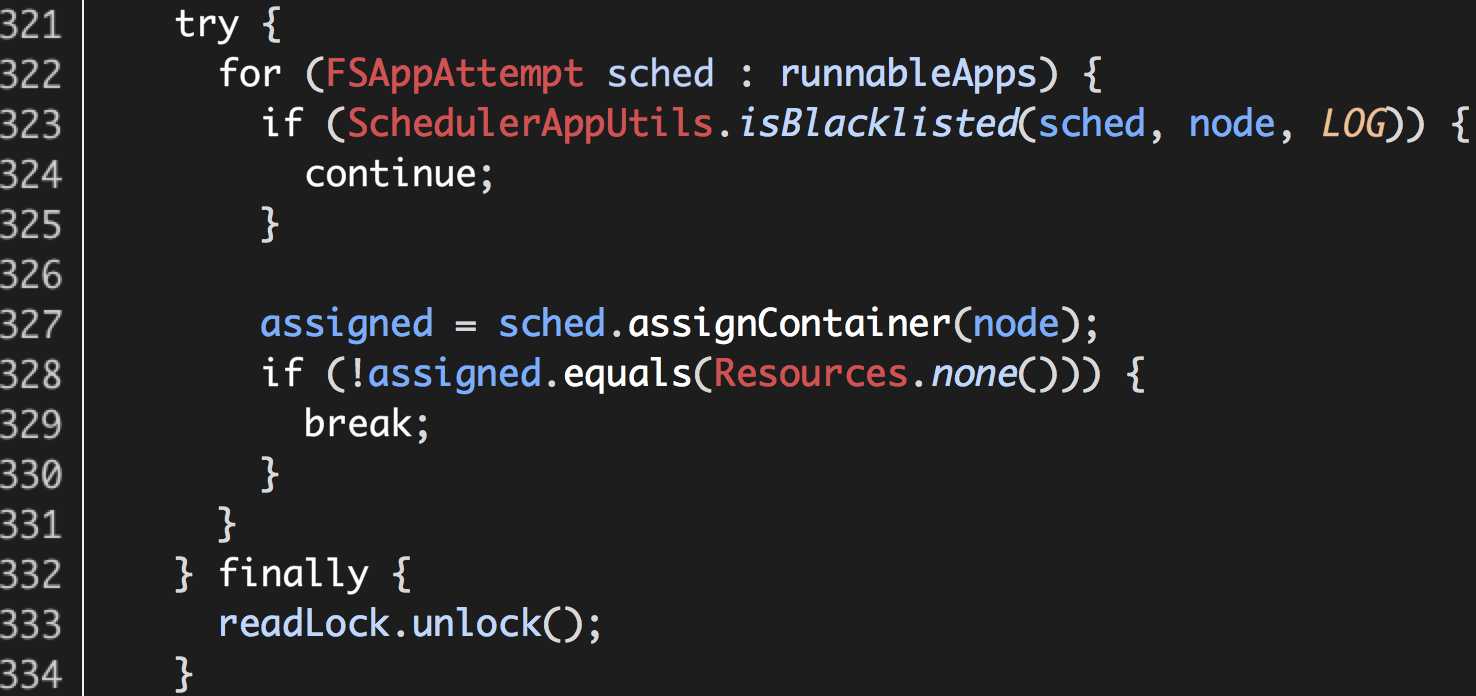
Hadoop Yarn FairScheduler原有处理逻辑(Hadoop 2.5.0-cdh5.3.2 org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FSLeafQueue.assignContainer):
在此基础之上添加资源池的处理逻辑:
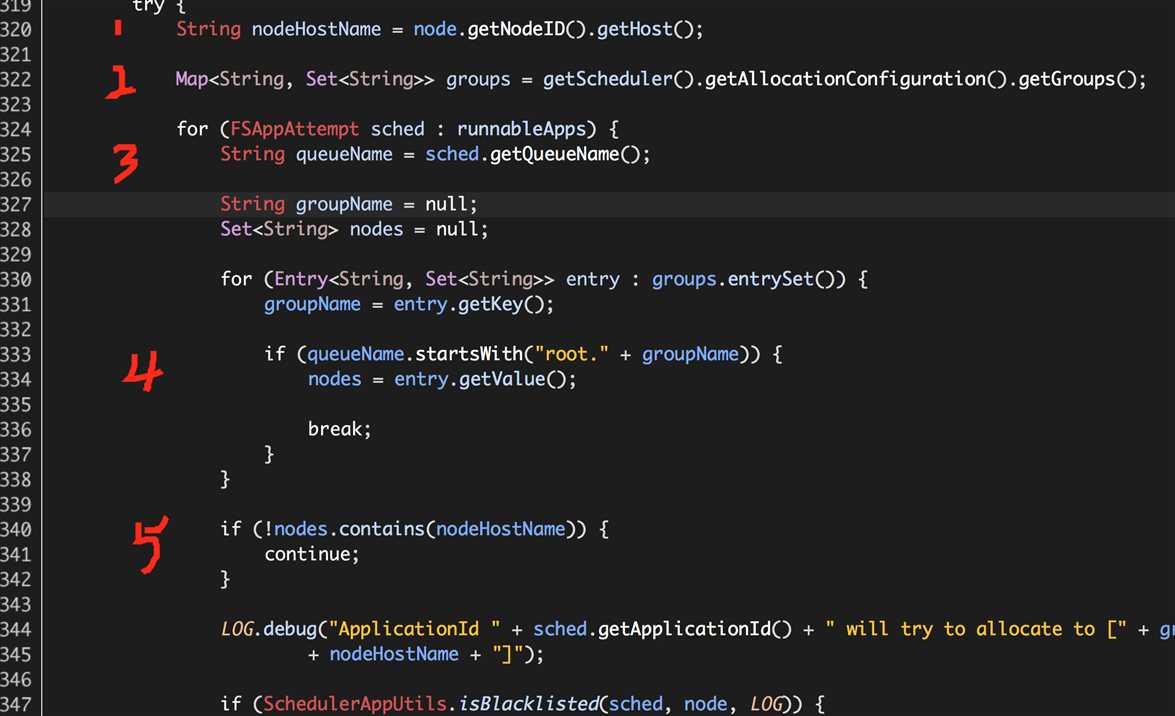
(1)获取“NODE_UPDATE”的Hadoop NodeManager的主机名称nodeHostName;
(2)获取资源池信息groups,其中“key”表示资源池名称,“value”表示资源池关联着的Hadoop NodeManager HostNames;
(3)获取待分配应用的队列名称queueName;
(4)寻找队列名称queueName对应资源池中的主机名称列表nodes;
(5)如果nodes包含nodeHostName,则继续分配过程;否则结束分配过程,继续下一个应用;
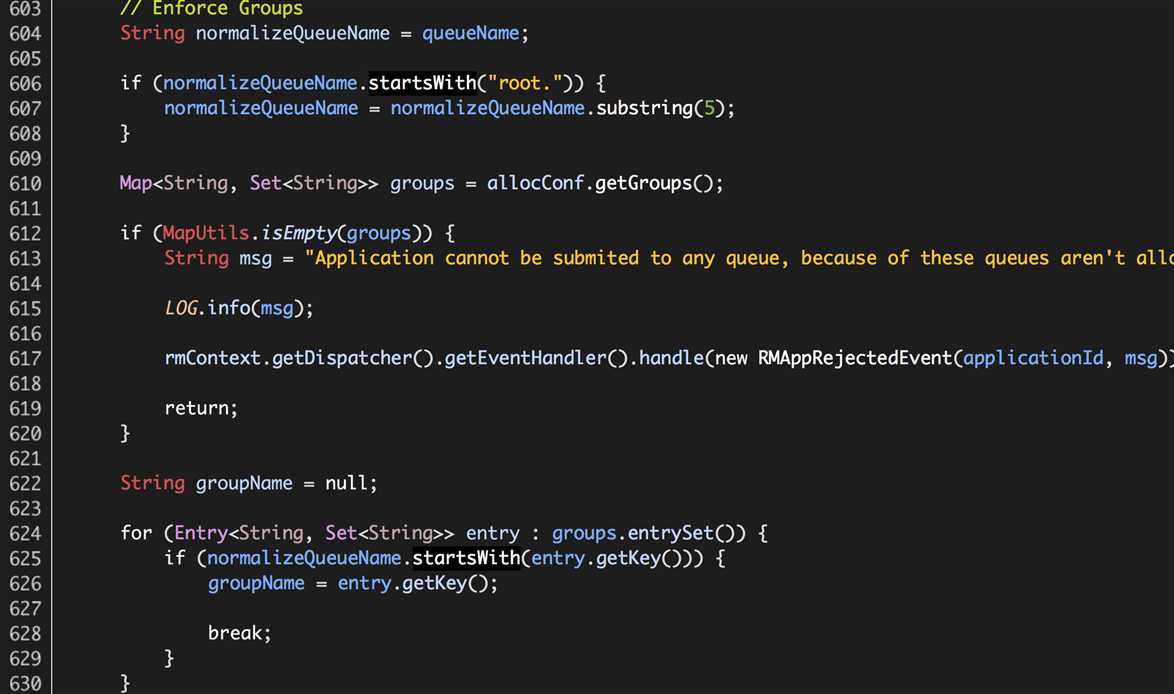
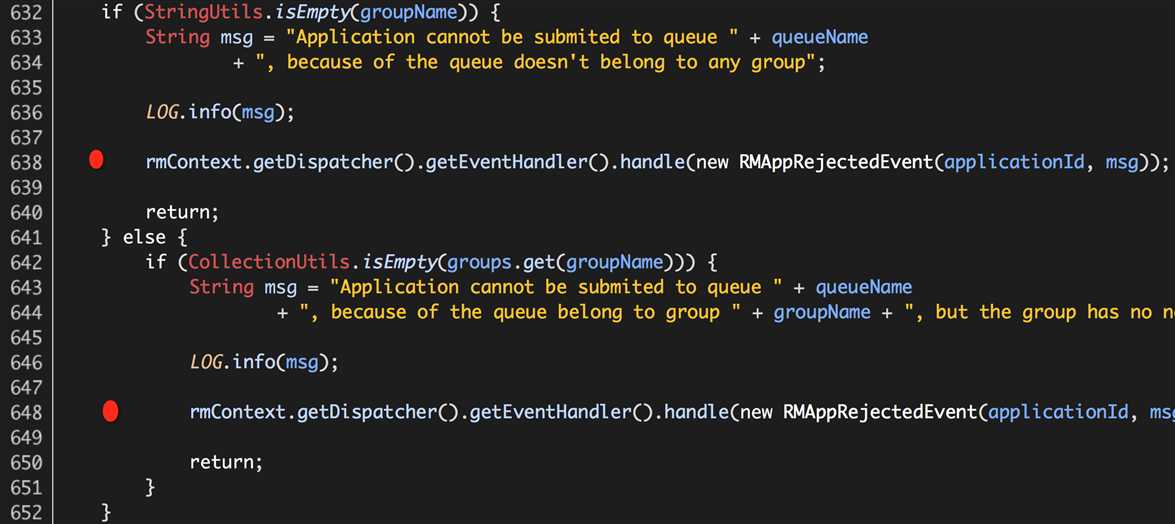
也就是说,Hadoop Yarn FairScheduler的原有逻辑,只要收到集群中任何一个Hadoop NodeManager的“NODE_UPDATE”事件,就会根据公平调度算法完成Containers的分配过程;添加资源池的处理逻辑之后,提交至队列queueName中的所有应用,只有收到来自对应资源池中的Hadoop NodeManager的“NODE_UPDATE”事件时,才会根据公平高度算法完成Containers的分配过程。
我们还需要处理这两种异常情况:
(1)应用提交至某队列,该队列没有配置对应的资源池;
(1)应用提交至某队列,该队列对应资源池的主机名称列表为空;
这两种情况我们的处理方式相同,终止该应用的执行,如下:
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler.addApplication
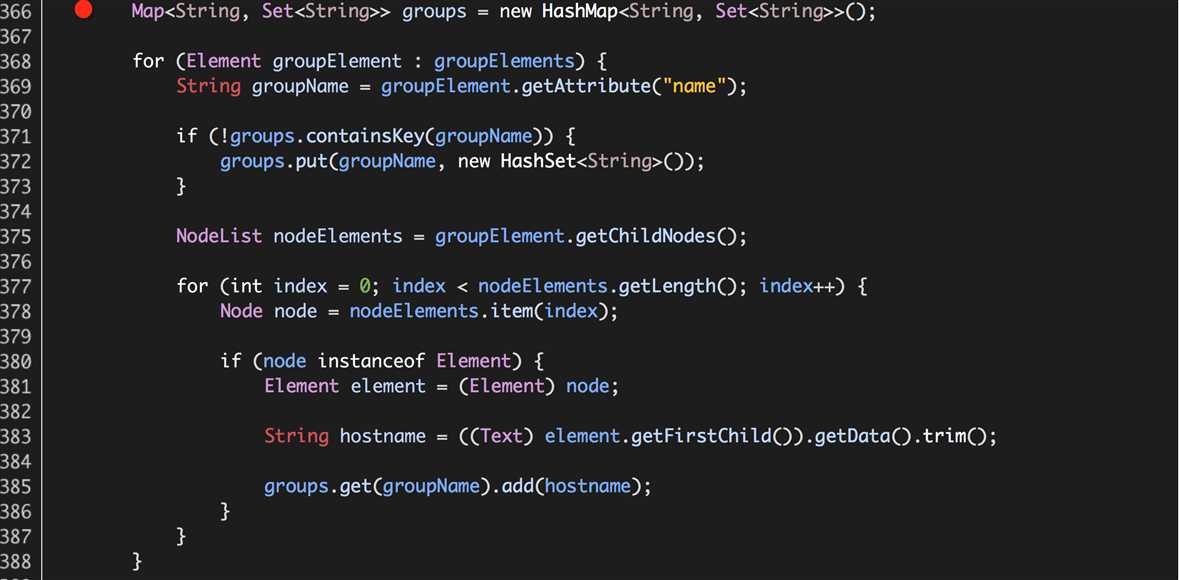
此外,还涉及到公平调度器fair-scheduler.xml的源码扩展,如下:
org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.AllocationFileLoaderService.reloadAllocations
实际就是从公平调度器配置文件fair-scheduler.xml中解析出资源池的信息,存储变量groups中,详细过程不再赘述。