标签:
转载请注明作者:梦里风林
Github工程地址:https://github.com/ahangchen/GDLnotes
欢迎star,有问题可以到Issue区讨论
官方教程地址
视频/字幕下载
与其他机器学习不同,在文本分析里,陌生的东西(rare event)往往是最重要的,而最常见的东西往往是最不重要的。
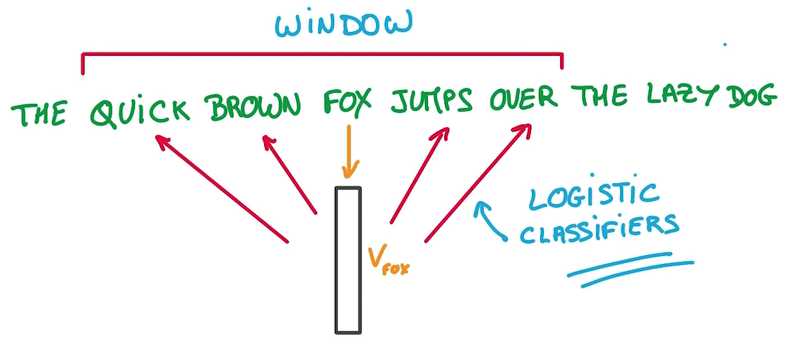
用来预测这些相邻位置单词的模型只是一个Logistics Regression, just a simple Linear model
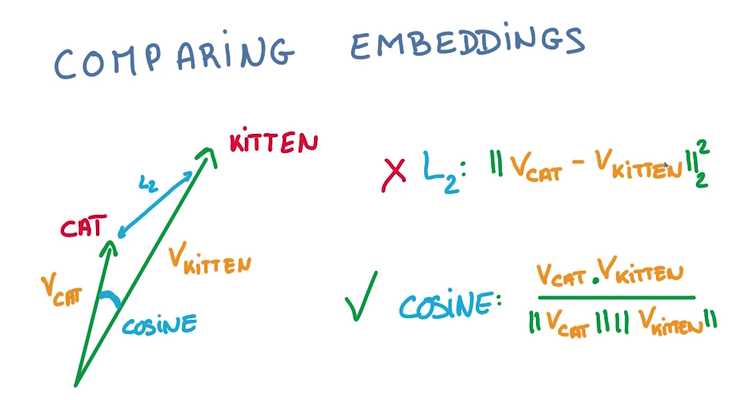
比较两个vector之间的夹角大小来判断接近程度,用cos值而非L2计算,因为vector的长度和分类是不相关的:
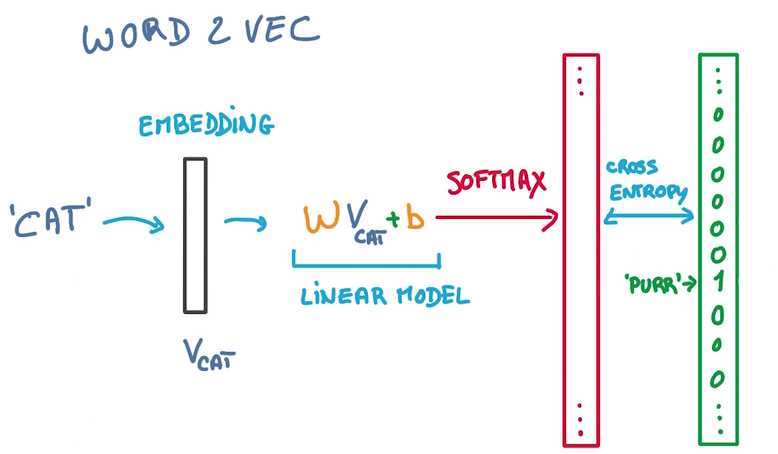
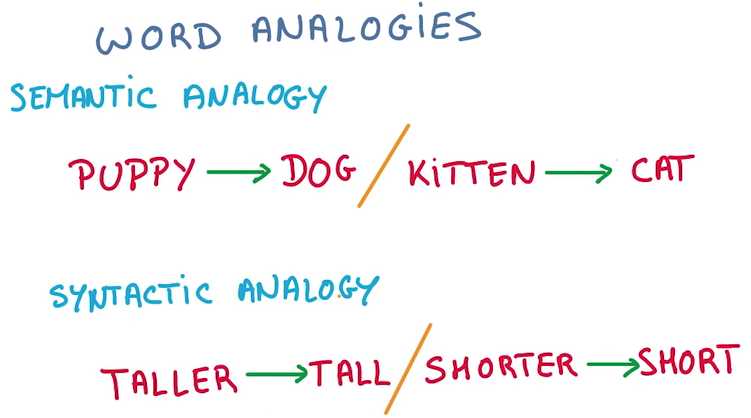
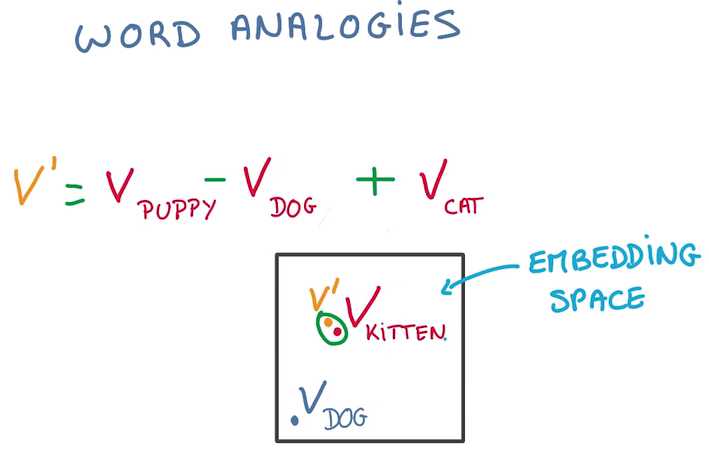
文本(Text)是单词(word)的序列,一个关键特点是长度可变,就不能直接变为vector
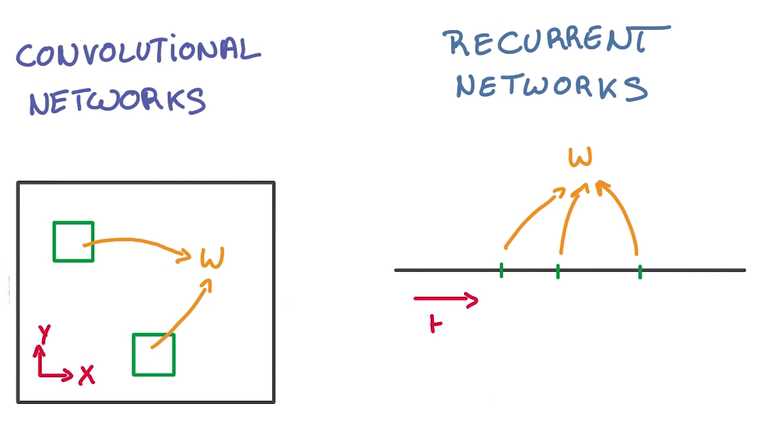
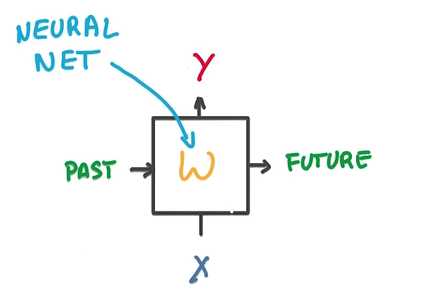
CNN 在空间上共享参数,RNN在时间上(顺序上)共享参数
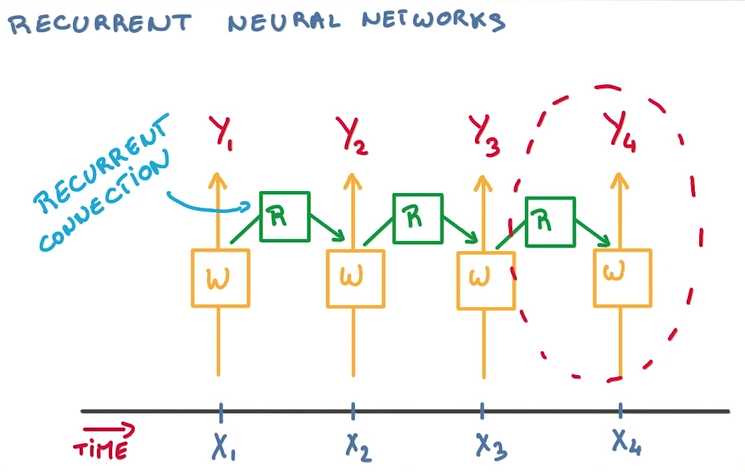
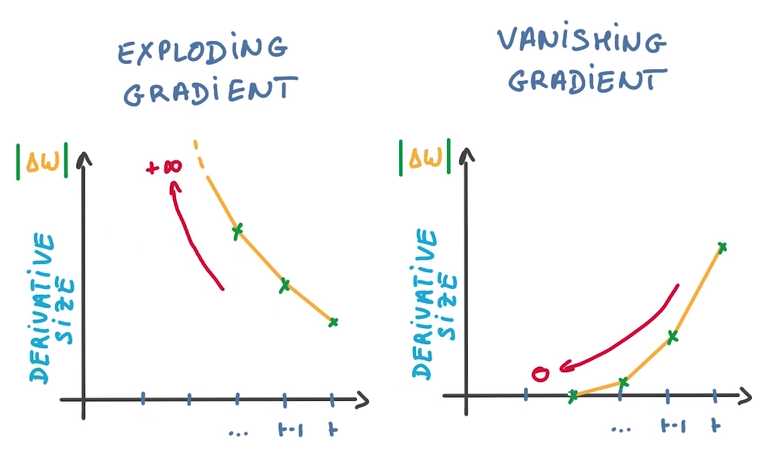
计算到梯度爆炸的时候,使用一个比值来代替△W(梯度是回流计算的,横坐标从右往左看)
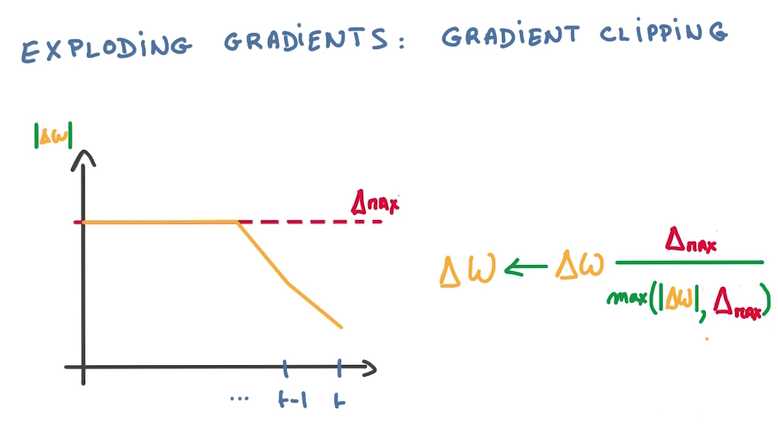
梯度消失会导致分类器只对最近的消息的变化有反应,淡化以前训练的参数,也不能用比值的方法来解决
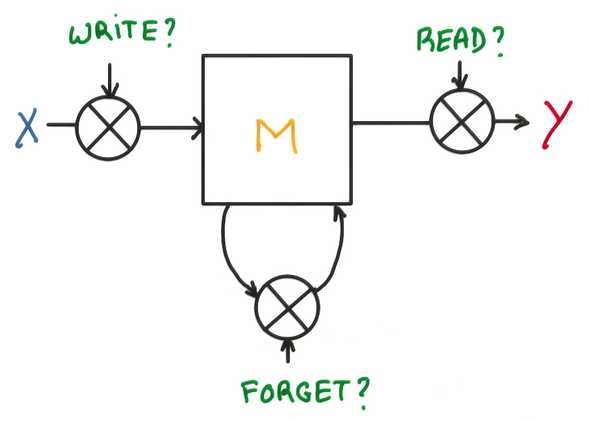
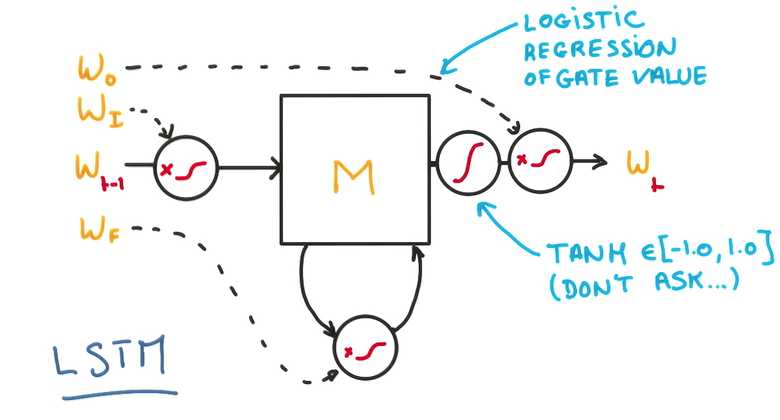
三个门,决定是否写/读/遗忘/写回
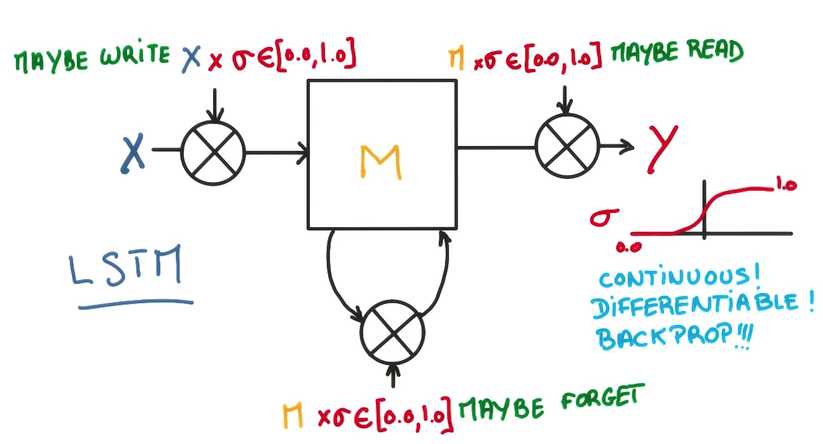
有了上面的模型之后,我们可以根据上文来推测下文,甚至创造下文,预测,筛选最大概率的词,喂回,继续预测……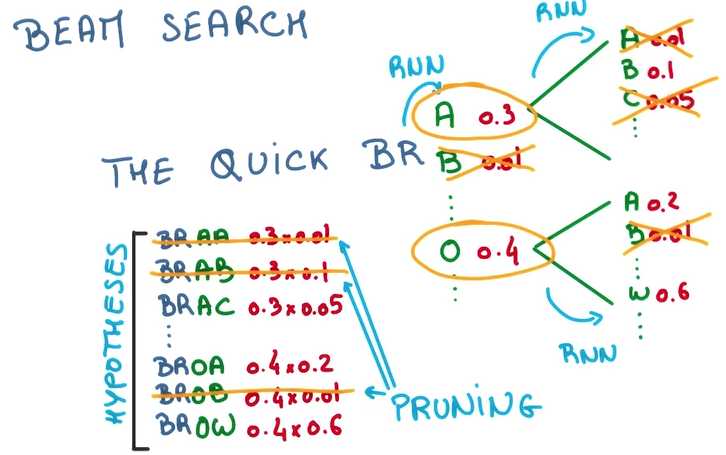
RNN将variable length sequence问题变成了fixed length vector问题,同时因为实际上我们能利用vector进行预测,我们也可以将vector变成sequence
如果我们将CNN的输出接到一个RNN,就可以做一种识图系统
标签:
原文地址:http://www.cnblogs.com/Leo_wl/p/5634566.html