标签:
今天将scrapy安装成功,测试了下,倒腾了好长时间,才倒腾成功,特此分享。
其实最好的老师就是scrapy的帮助文档,只要把文档看懂,照着做,也就啥都会儿了!
帮助文档下载见http://download.csdn.net/detail/flyinghorse_2012/9566467
0.新建立一个文件夹,用来存放相关文件,命名为test
1.构建scrapy project
运行命令:
scrapy startproject tutorial
效果如下:

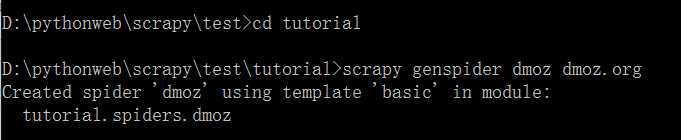
2.构建spider
运行如下命令:
scrapy genspider dmoz dmoz.org
格式要求说明:scrapy genspider spidername spiderwebsite
spidername必须为唯一,spiderwebsite可随便制定,对应dmoz.py中的allowed_domains.
效果如下:
3.修改items.py
找到....test\tutorial\tutorial\items.py,修改文件内容为:
import scrapy
class TutorialItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
保存。
4.修改dmoz.py
找到....\test\tutorial\tutorial\spiders\dmoz.py,修改文件内容为:
# -*- coding: utf-8 -*-
import scrapy
class DmozSpider(scrapy.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = (
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
)
def parse(self, response):
filename = response.url.split("/")[-2] + ‘.html‘
with open(filename, ‘wb‘) as f:
f.write(response.body)
保存。
5.运行爬虫
scrapy crawl dmoz
格式要求说明:scrapy crawl spidername
spidername即为step2中的spidername。
效果如下:
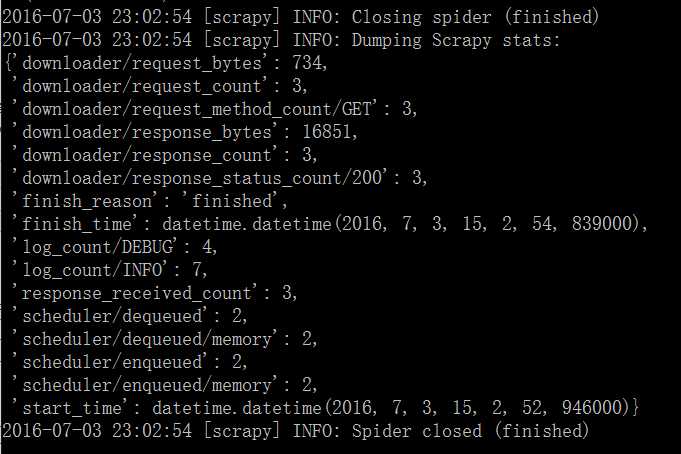
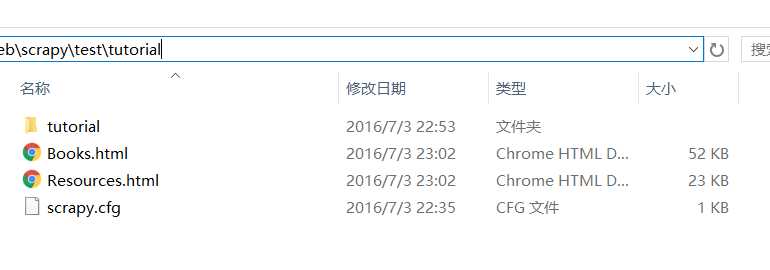
已成功生成2个html文件,网页内容已被抓取到。
标签:
原文地址:http://www.cnblogs.com/flyinghorse/p/5639118.html