标签:
神经网络中,我们通过最小化神经网络来训练网络,所以在训练时最后一层是损失函数层(LOSS),
在测试时我们通过准确率来评价该网络的优劣,因此最后一层是准确率层(ACCURACY)。
但是当我们真正要使用训练好的数据时,我们需要的是网络给我们输入结果,对于分类问题,我们需要获得分类结果,如下右图最后一层我们得到
的是概率,我们不需要训练及测试阶段的LOSS,ACCURACY层了。
下图是能过$CAFFE_ROOT/python/draw_net.py绘制$CAFFE_ROOT/models/caffe_reference_caffnet/train_val.prototxt , $CAFFE_ROOT/models/caffe_reference_caffnet/deploy.prototxt,分别代表训练时与最后使用时的网络结构。
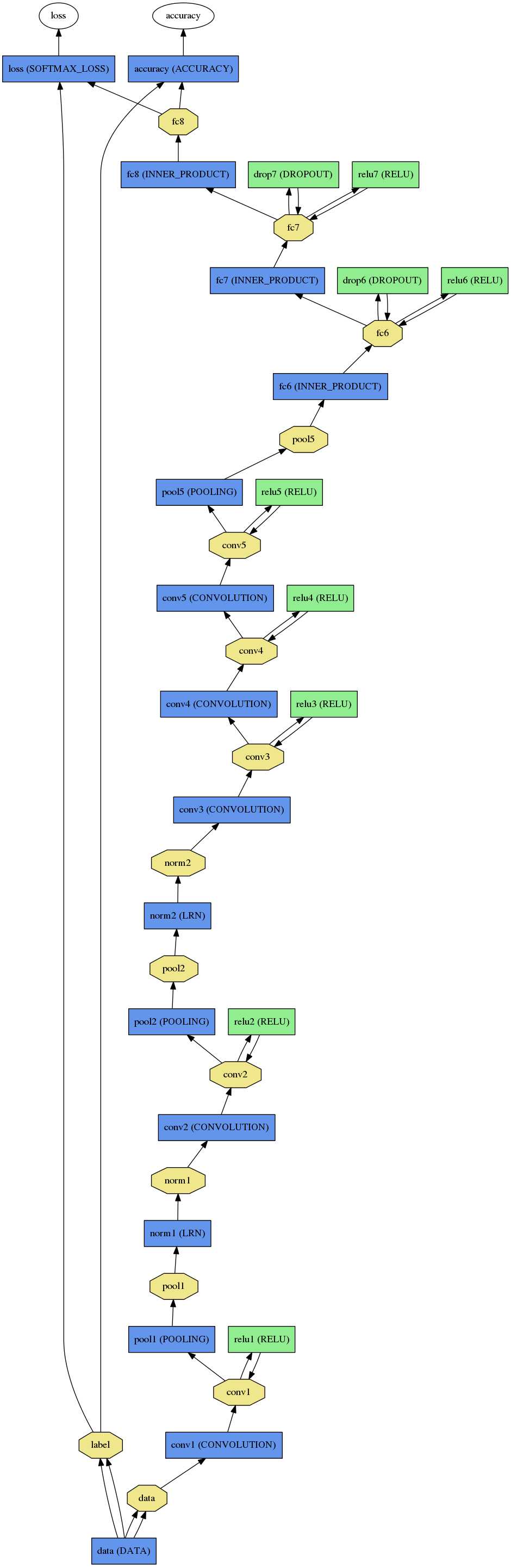
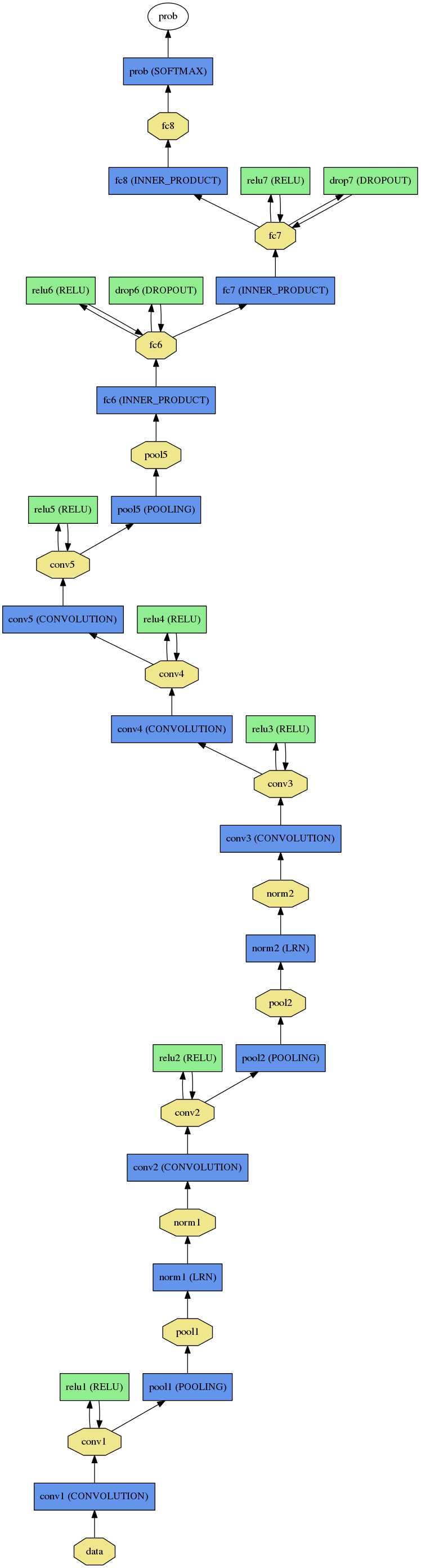
我们一般将train与test放在同一个.prototxt中,需要在data层输入数据的source,
而在使用时.prototxt只需要定义输入图片的大小通道数据参数即可,如下图所示,分别是
$CAFFE_ROOT/models/caffe_reference_caffnet/train_val.prototxt , $CAFFE_ROOT/models/caffe_reference_caffnet/deploy.prototxt的data层
训练时, solver.prototxt中使用的是rain_val.prototxt
|
1
|
./build/tools/caffe/train -solver ./models/bvlc_reference_caffenet/solver.prototxt |
使用上面训练的网络提取特征,使用的网络模型是deploy.prototxt
|
1
|
./build/tools/extract_features.bin models/bvlc_refrence_caffenet.caffemodel models/bvlc_refrence_caffenet/deploy.prototxt |


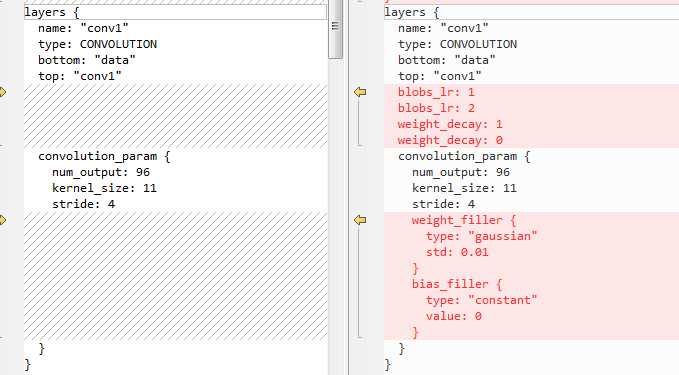
上一篇博文介绍在使用CAFFE中,训练阶段与使用阶段的网络设计有些许差别,这一篇博文我们主要研究下卷积层在两个阶段的不同,
在训练阶段,参数的初值,及学习率等参考需要设置,
下面分别是K:\deep learning\Caffe\caffe-master\caffe-master\models\bvlc_reference_caffenet\deploy.prototxt 与K:\deep learning\Caffe\caffe-master\caffe-master\models\bvlc_reference_caffenet\train_val.prototxt
第一个卷积层的网络设置,我们可以看出在训练阶段需要指定学习率,权重衰减参数,以及权重的初始化方法。
权重是使用方差为0.01的高斯函数初始化的,偏移使用0来初始化。
全连接层也有与卷积层相似的问题。
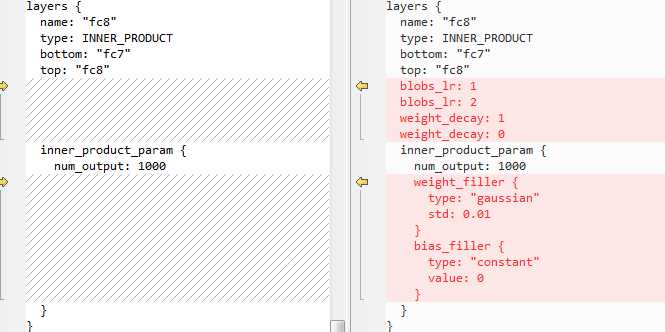
为什么只有卷积层与全连接层有此差别,而其它层木有呢?这是由于 LRN, POOLING, RELU层都是无参的,上一层固定,那么就会得到确定的值。
CAFFE层类别如下所示,分为输入层(DATA,HDF5_DATA),element_wise(ABSVAL, ELTWISE, POWER, RELU, SIGMOID, TANH,THRESHOLD等)操作,LOSS层(CONTRASTIVE_LOSS, EUCLIDEAN_LOSS, INFOGAIN_LOSS, MULTINORMIAL_LOGISTIC_LOSS, SIGMOID_CROSS_ENTROPY_LOSS, SOFTMAX_LOSS等), 除此之外分为有参层,无参层。有参层在训练阶段需要指定参数的初始化方式,学习率等参数
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
<span style="font-family: 楷体;"> enum LayerType { // "NONE" layer type is 0th enum element so that we don‘t cause confusion // by defaulting to an existent LayerType (instead, should usually error if // the type is unspecified). NONE = 0; ABSVAL = 35; <span style="color: #3366ff;">//abs</span> ACCURACY = 1; <span style="color: #3366ff;">//accuracy</span> ARGMAX = 30; BNLL = 2; <span style="color: #3366ff;">//BNLL (binomial normal log likelihood) 层通过 log(1 + exp(x)) 计算每一个输入x的输出。</span> CONCAT = 3; <span style="color: #3366ff;">//通过Concatenation层,可以把多个的blobs链接成一个blob。</span> CONTRASTIVE_LOSS = 37; // 还没有具体研究 CONVOLUTION = 4; <span style="color: #3366ff;">//总面积</span> DATA = 5; //数据 DROPOUT = 6; DUMMY_DATA = 32; EUCLIDEAN_LOSS = 7; ELTWISE = 25; FLATTEN = 8; HDF5_DATA = 9; HDF5_OUTPUT = 10; HINGE_LOSS = 28; IM2COL = 11; IMAGE_DATA = 12; INFOGAIN_LOSS = 13; INNER_PRODUCT = 14; LRN = 15; MEMORY_DATA = 29; MULTINOMIAL_LOGISTIC_LOSS = 16; MVN = 34; POOLING = 17; POWER = 26; RELU = 18; SIGMOID = 19; SIGMOID_CROSS_ENTROPY_LOSS = 27; SILENCE = 36; SOFTMAX = 20; SOFTMAX_LOSS = 21; SPLIT = 22; SLICE = 33; TANH = 23; WINDOW_DATA = 24; THRESHOLD = 31; }</span> |
标签:
原文地址:http://www.cnblogs.com/laiqun/p/5640964.html