标签:
在操作PDF文件时会遇到PDF文件加密了,不能操作的问题,从网络中查找资料一上午,鼓捣出如下的代码,可实现将已加密的PDF转化成未加密的PDF文件,纯代码,无需借助PDF解密软件,使用前需要导入如下引用,使用的itextsharp版本为5.5.9.0。
1 using iTextSharp.text.pdf; 2 using iTextSharp.text; 3 using System.IO;
1 /// <summary> 2 /// 将去掉PDF的加密 3 /// </summary> 4 /// <param name="sourceFullName">源文件路径(如:D:\old.pdf)</param> 5 /// <param name="newFullName">目标文件路径(如:D:\new.pdf)</param> 6 private static void deletePDFEncrypt(string sourceFullName, string newFullName) 7 { 8 if (string.IsNullOrEmpty(sourceFullName) || string.IsNullOrEmpty(newFullName)) 9 { 10 throw new Exception("源文件路径或目标文件路径不能为空或null."); 11 } 12 //Console.WriteLine("读取PDF文档"); 13 try 14 { 15 // 创建一个PdfReader对象 16 PdfReader reader = new PdfReader(sourceFullName); 17 PdfReader.unethicalreading = true; 18 // 获得文档页数 19 int n = reader.NumberOfPages; 20 // 获得第一页的大小 21 Rectangle pagesize = reader.GetPageSize(1); 22 float width = pagesize.Width; 23 float height = pagesize.Height; 24 // 创建一个文档变量 25 Document document = new Document(pagesize, 50, 50, 50, 50); 26 // 创建该文档 27 PdfWriter writer = PdfWriter.GetInstance(document, new FileStream(newFullName, FileMode.Create)); 28 // 打开文档 29 document.Open(); 30 // 添加内容 31 PdfContentByte cb = writer.DirectContent; 32 int i = 0; 33 int p = 0; 34 while (i < n) 35 { 36 document.NewPage(); 37 p++; 38 i++; 39 PdfImportedPage page1 = writer.GetImportedPage(reader, i); 40 cb.AddTemplate(page1, 1f, 0, 0, 1f, 0, 0); 41 } 42 // 关闭文档 43 document.Close(); 44 } 45 catch (Exception ex) 46 { 47 throw new Exception(ex.Message); 48 } 49 }
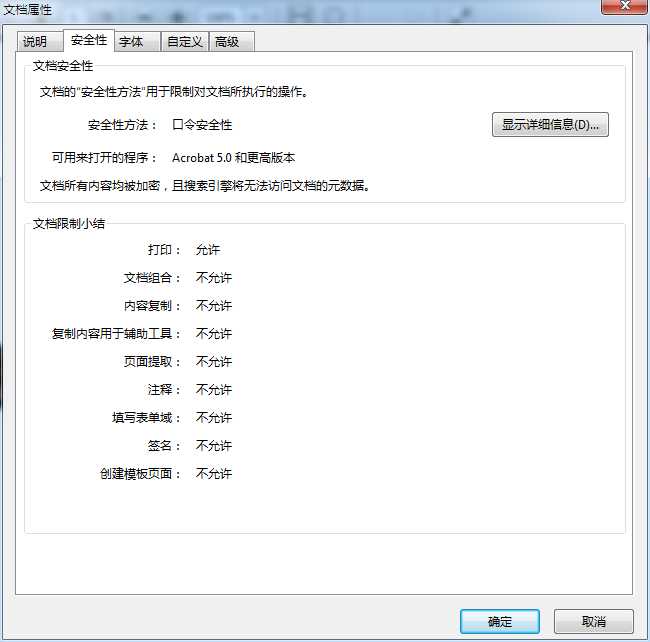
使用代码转换之前PDF的属性如下图:
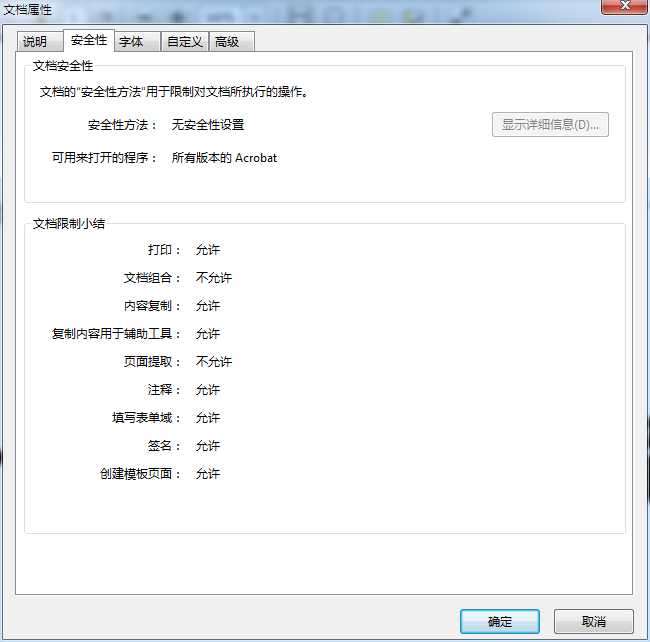
转换之后:
标签:
原文地址:http://www.cnblogs.com/smallangle/p/5644526.html