标签:
| 代码 | 说明 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配字母或数字或下划线 |
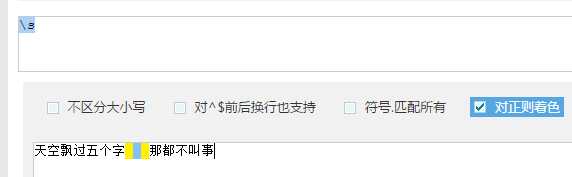
| \s | 匹配任意的空白符 |
| \d | 匹配数字 |
| \b | 匹配单词的开始或结束 |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结束 |
| 代码/语法 | 说明 |
|---|---|
| * | 重复零次或更多次 |
| + | 重复一次或更多次 |
| ? | 重复零次或一次 |
| {n} | 重复n次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n到m次 |
| 代码/语法 | 说明 |
|---|---|
| \W | 匹配任意不是字母,数字,下划线,汉字的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开头或结束的位置 |
| [^x] | 匹配除了x以外的任意字符 |
| [^aeiou] | 匹配除了aeiou这几个字母以外的任意字符 |
本文的实例不一定是相关问题的终极答案。事实上,与正则表达式有关的问题很少会有一个终极答案。更常见的情况时同时存在多种答案,它们没有对错之分,它们之间的区别只体现在你希望你的匹配操作严格到什么程度。
1 | [\u4e00-\u9fa5] |
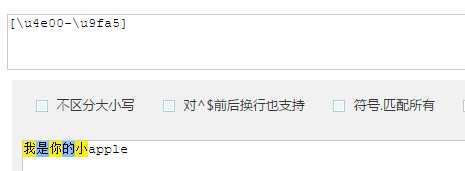
解析:使用utf-8编码时汉字的范围是u4e00-u9fa5
1 | [^\x00-\xff] |
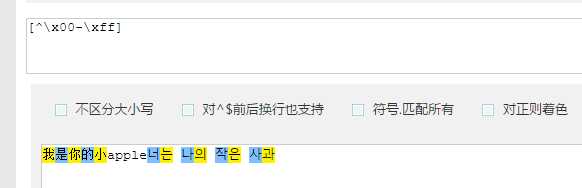
解析:\x00-\xff使用8位也就是单字节来表示字符,^是取非,也就是说除了单字节的字符,剩下就是双字节的字符了。
1 | ^\s+|\s+$ |
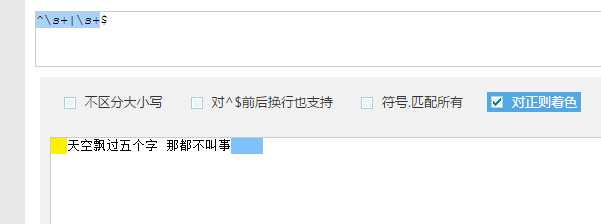
解析:^匹配字符串开头,$匹配字符串结尾,\s+匹配空格出现一次或者多次。
1 | (\w+\.)*\w+@(\w+\.)+[A-Za-z]+ |
解析:(\w+\.)*\w+负责匹配电子邮件地址的用户名部分(@之前的文本):(\w+\.)*匹配一些由.结束的文字的零次或多次重复出现,\w+匹配比不可少的文本。接下来,@匹配字符本身,(\w+\.)+匹配至少一个以.结束的字符串,[A-Za-z]+匹配顶级域名。
1 | https?://[-\w.]+(:\d+)?(/([\w/_.]*)?)? |
解析:https?://匹配http://或https:// (?使得字符s是可选的)。[-\w.]+匹配主机名。(:\d+)?匹配一个可选的端口号。(/([\w/_.]*)?)?负责匹配一个文件路径。
1 | (13|14|15|17|18)[0-9]{9} |
解析:国内手机号码开头两位数字一般是固定的几位,接下来就是9个数字。
1 | \(?0\d{2,4}\)?[- ]?[2-9]\d{2,3}[- ]?\d{4} |
解析:我国的固定电话号码的规律是,最开始的位一定是0,表示长途, 接着是两到四位数字组成的区号,然后是7到8位的电话号码,其中首位不为1.习惯格式有:029 8845 7890,029-88457890,(029) 88457890,029-8845-7890等。
1 | \d(9|[0-7])\d{4} |
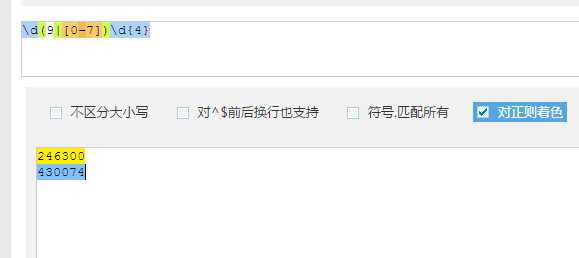
解析:我国的邮政编码规则是,前两位表示省、市、自治区,第三位代表邮区,第四位表示县、市,最后两位表示投递邮局。共六位数字,其中第二位不为8(港澳前两位为99,其余省市为0-7)。
1 | \b(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\b |
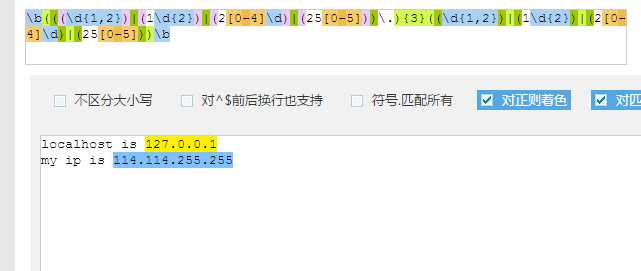
解析: IP地址由4个字节构成(取值范围是0~255)IP地址通常被写成4组以.字符隔开的整数,每个整数由1~3位数字构成。正则表达式首尾的\b用来匹配单词的边界,接下来由4个子表达式构成(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.):其中(\d{1,2})匹配任意一位或者两位数字;(1\d{2})匹配以1开头的任意三位数字;(2[0-4]\d)匹配整数200~249;(25[0-5])匹配整数250~255.这几个子表达式通过|操作符结合为一个更大的子表达式。随后的\.用来匹配.字符,它与前4个子表示构成的大子表达式再次构成更大的子表达式,{3}表明重复3次。因为第四个字节是没有.结尾的,所以最后把前面的四个小的子表达式组成的大表达式重复一次即可。
1 | ^(\d{6})(\d{4})(\d{2})(\d{2})(\d{3})([0-9]|X)$ |
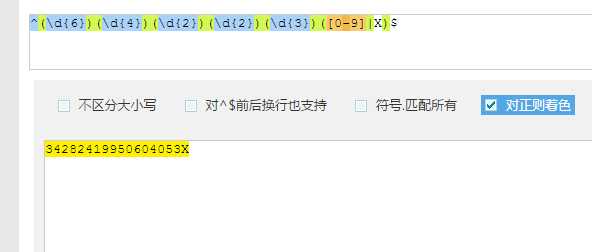
解析:身份证号码前6位为地区号码,接着四位为出身年,接着两位为月份,后面是出身日期,最后面是4位计算出来的标识码,需要注意的是这四位中最后一位有可能是字母X.
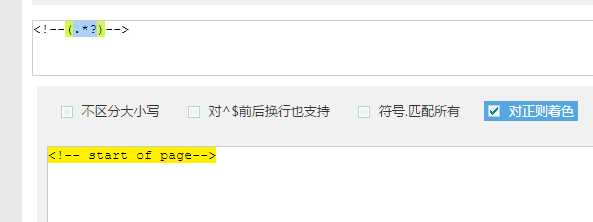
1 | <!--(.*?)--> |
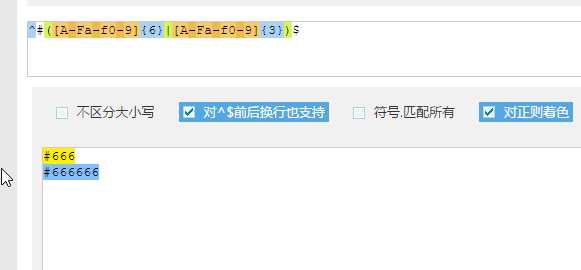
1 | ^#([A-Fa-f0-9]{6}|[A-Fa-f0-9]{3})$ |
后续随时跟新。。。。。。。。。。
标签:
原文地址:http://www.cnblogs.com/star91/p/5644971.html